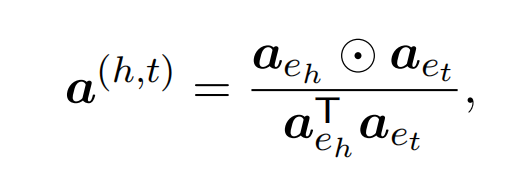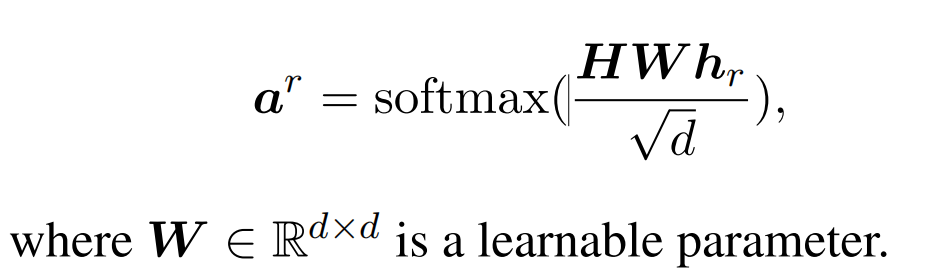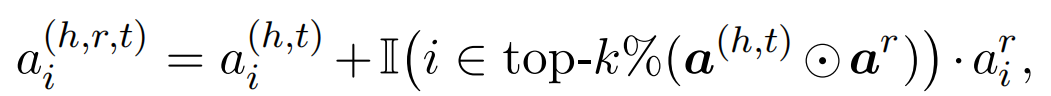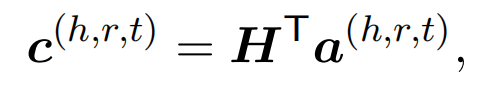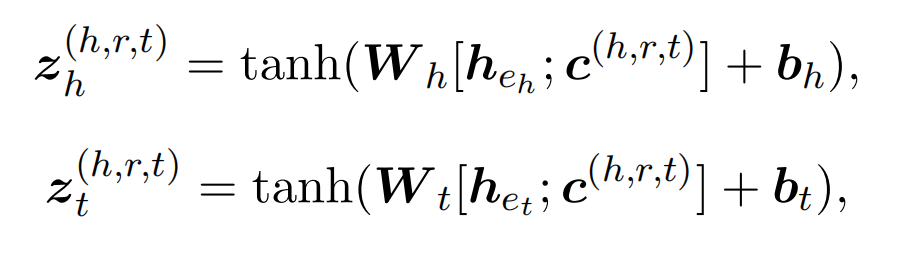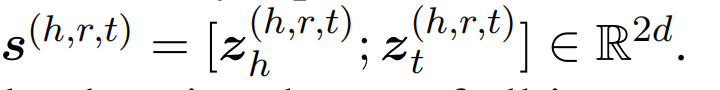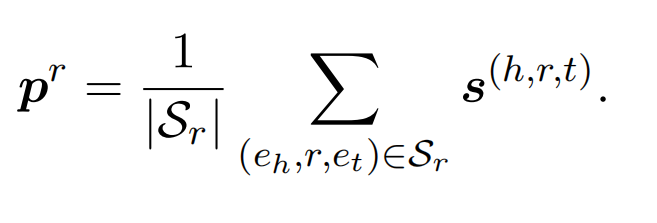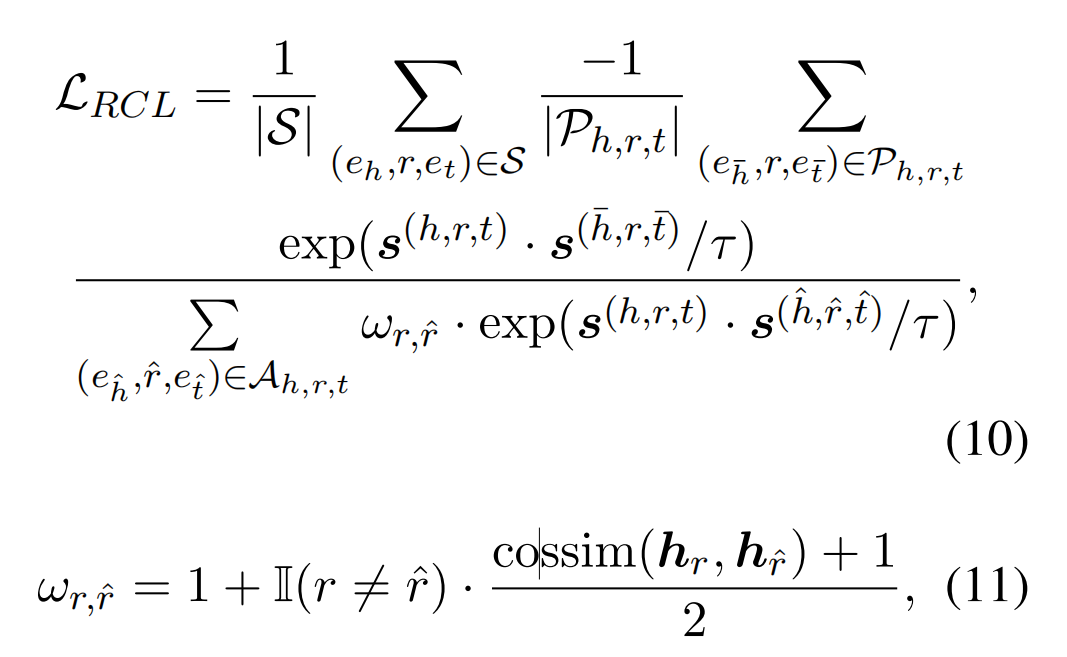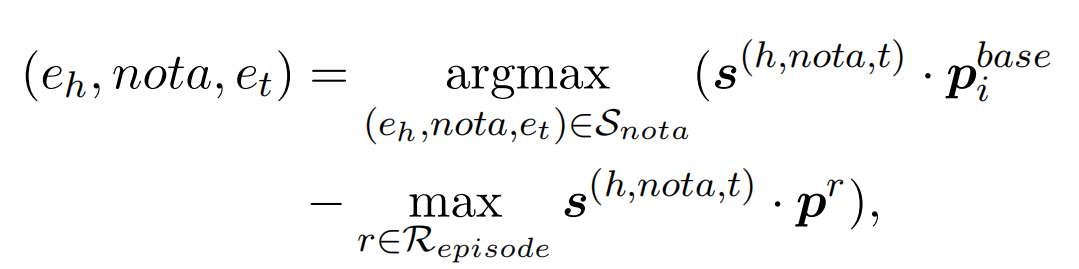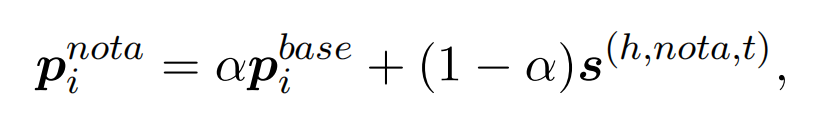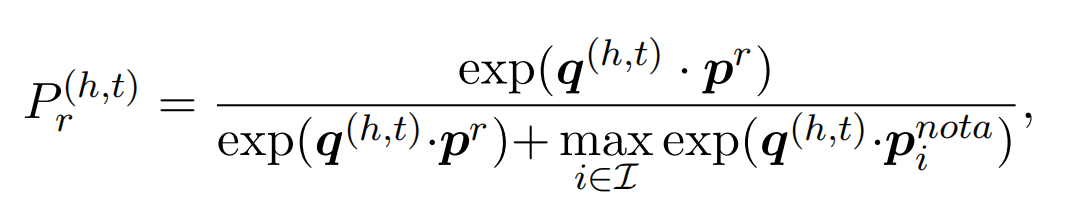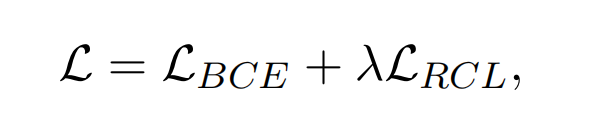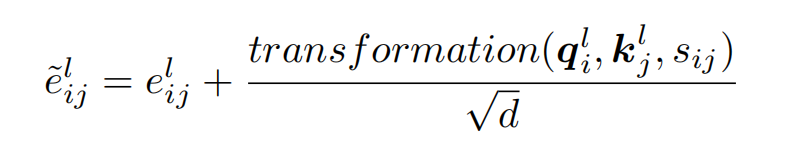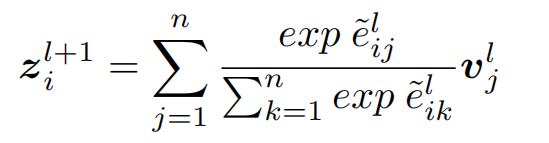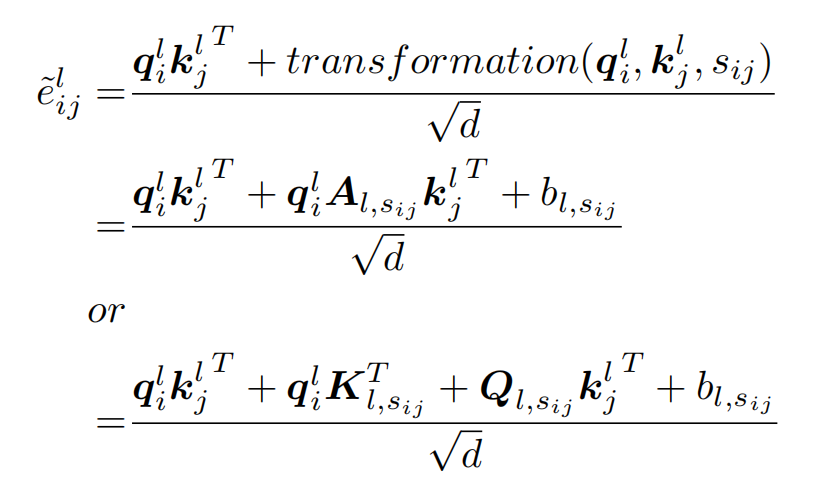Document-Level Relation Extraction with Adaptive Focal Loss and Knowledge Distillation
年份:2022
From:ACL
作者:Qingyu Tan, Ruidan He etc.
机构:DAMO Academy, Alibaba Group
GitHub:https://github.com/tonytan48/KD-DocRE
工作:
- 为了改进了双跳关系的推理,提出使用轴向注意力模块作为特征提取器。这个模块能够关注位于双跳逻辑路径中的元素,并捕获关系三元组之间的相互依赖关系。
- 其次,提出了自适应焦点损失(Adaptive Focal Loss)来解决不平衡的关系类型分布问题,提出的损失函数使得长尾类对总体损失的贡献更大。
- 最后,使用知识蒸馏来克服注释数据和远程监督数据之间的差异。具体来说,首先用少量的人类注释数据来训练一个教师模型。然后,将使用教师模型对大量的远程监督数据进行预测。生成的预测被用作预训练学生模型的软标签。最后,对预先训练好的学生模型进行了进一步的微调。
现有工作的缺陷:
- 现有方法聚焦于从预训练语言模型获取上下文信息,但是忽略了实体对之间的交互信息。
- 现有方法没有明确的解决DocRE数据集中关系类别数量不平衡的问题,仅关注于动态阈值以平衡正负样本数量不平衡的问题。
- 几乎没有工作讨论在DocRE数据集上应用远程监督方法。
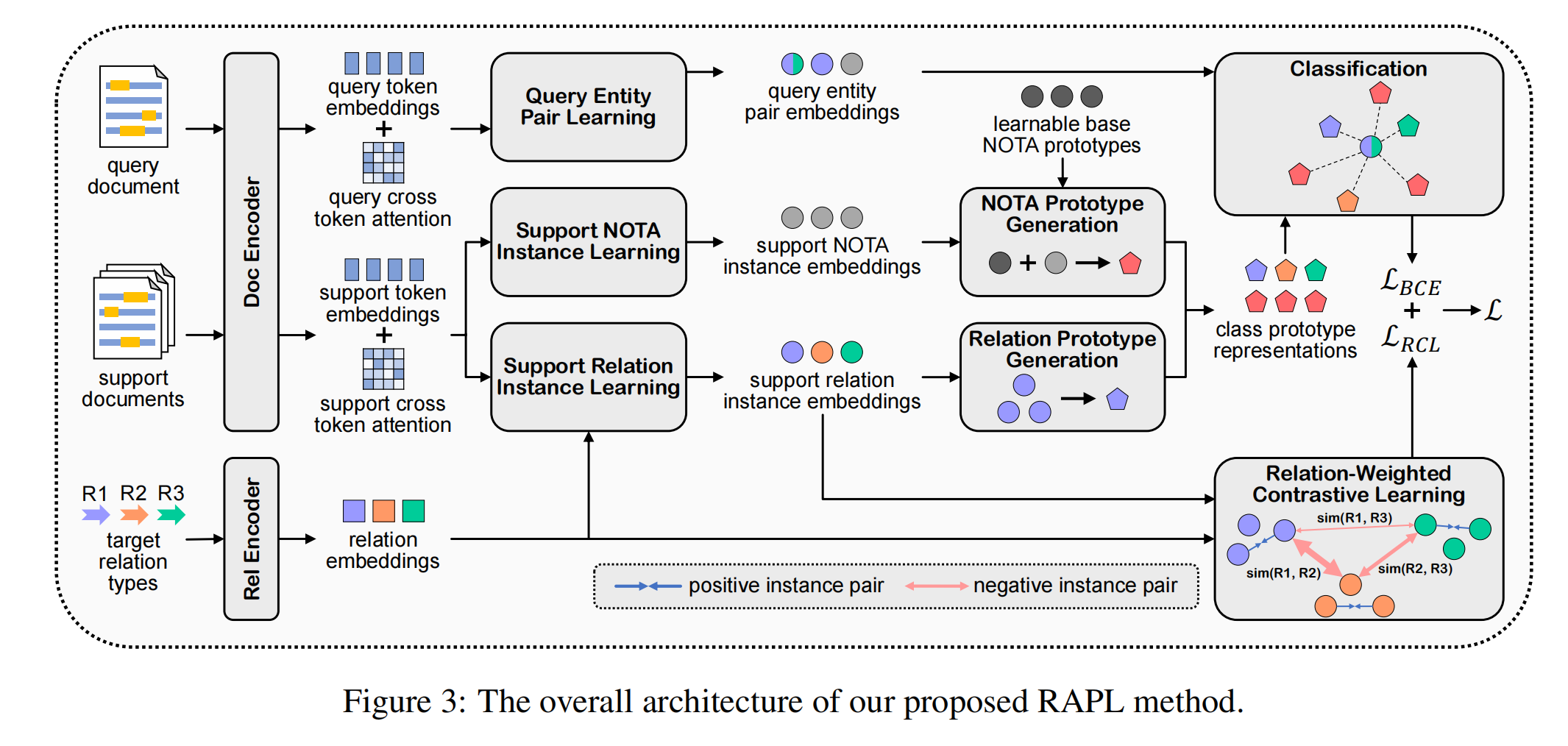
模型结构
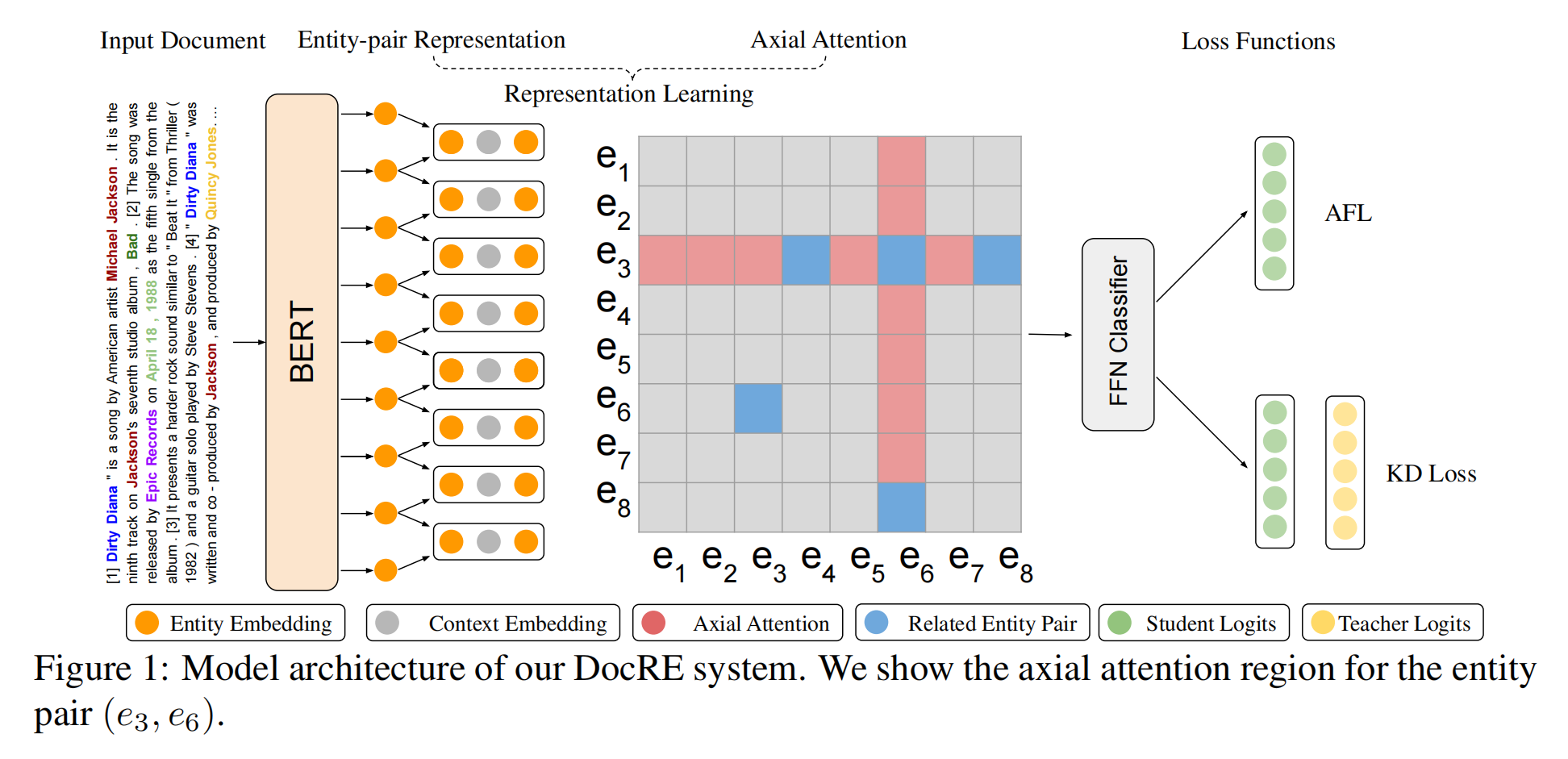
提出的模型包含三个部分:
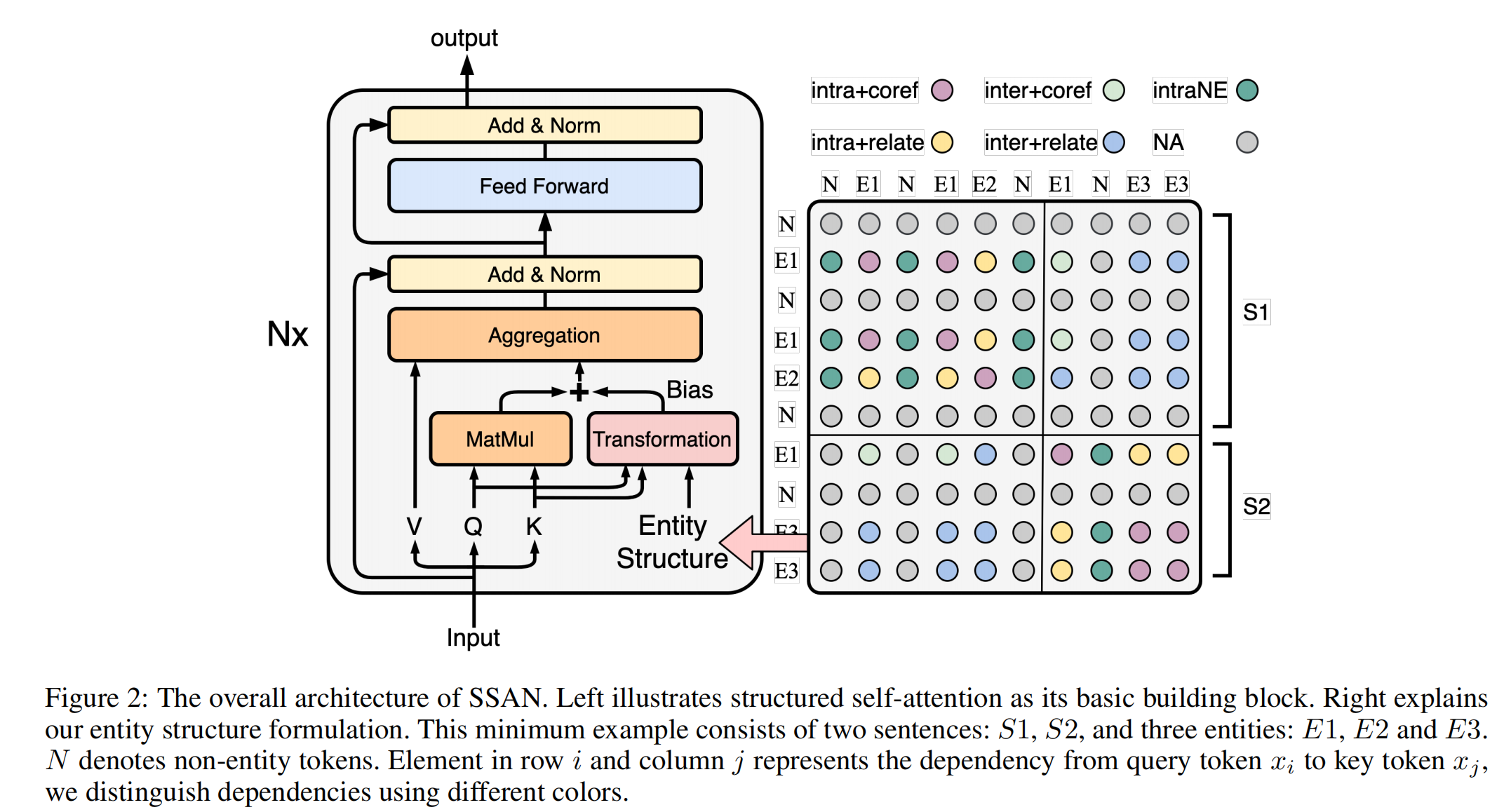
- 表示学习(Representation Learning):首先通过预先训练的语言模型提取每个实体对的上下文表示。轴向注意模块将进一步增强实体对的表示,该模块将对实体对之间的相互依赖信息进行编码。
- 自适应Focal损失(Adaptive Focal Loss):使用一个前馈神经网络分类器,用于计算损失,应用AFL损失以更好的应对长尾分布。
- 知识蒸馏:使用知识蒸馏客服人工标注数据和远程数据之间的差异。具体来说,就是用带注释的数据训练一个教师模型,并将其输出作为软标签。然后,我们基于软标签和远程标签对学生模型进行预训练。预先训练好的学生模型将再次使用带注释的数据进行微调。
Representation Learning
实体表示
利用预训练语言模型对文档进行编码,同时用特殊token标记实体位置(星号)。实体表示为,多个实体提及的sumexp池化操作:
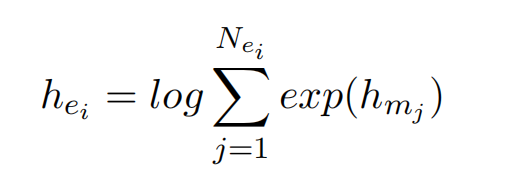
后用多个实体提及在最后一层的多头注意力权重的平均值,作为上下文信息增强:
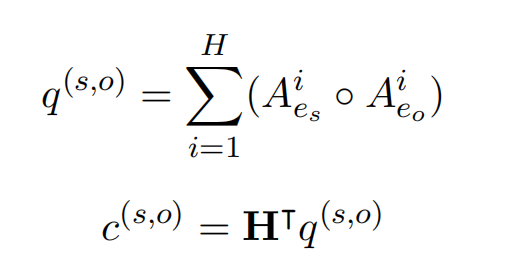
最终,实体表示为两部分,分别是实体嵌入和上下文多头注意力机制增强:
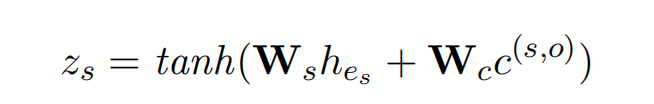
实体对表示(轴向注意力)
实体对通过分组的线性函数进行表示:
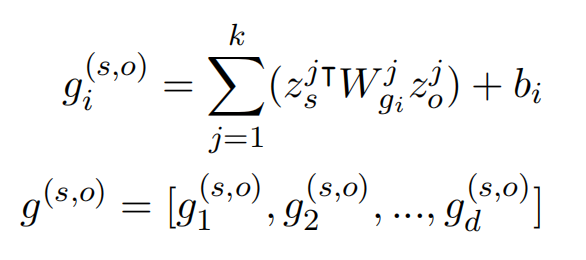
引入轴向注意力机制,来引入两跳的实体对信息,最终实体对表示为:

Adaptive Focus Loss
通过线性层来进行关系类型的预测:
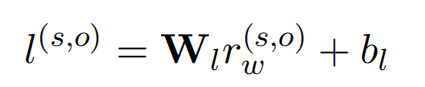
引入AFL来解决长尾分布问题,损失函数分为两个部分。第一部分是正例的,第二部分是关于负例的。其中,正例的概率分布计算方式:
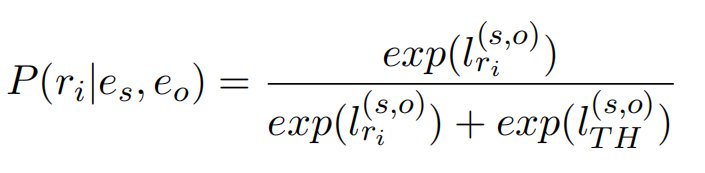
负例的概率分布计算方式:
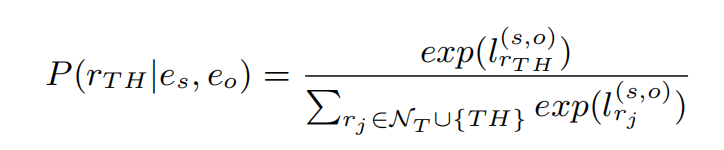
损失函数被定义为:
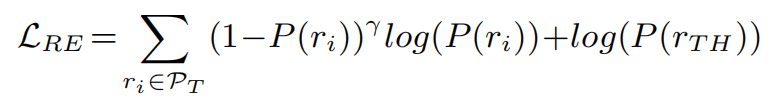
其中r为超参数,AFL损失是被设计成更多地关注低置信度的类别。如果一个正例关系类别的概率分布较低,则相关类的损失贡献将较高,从而可以对长尾类进行更好的优化。
利用远程监督进行知识蒸馏
略,这部分没有参考价值。
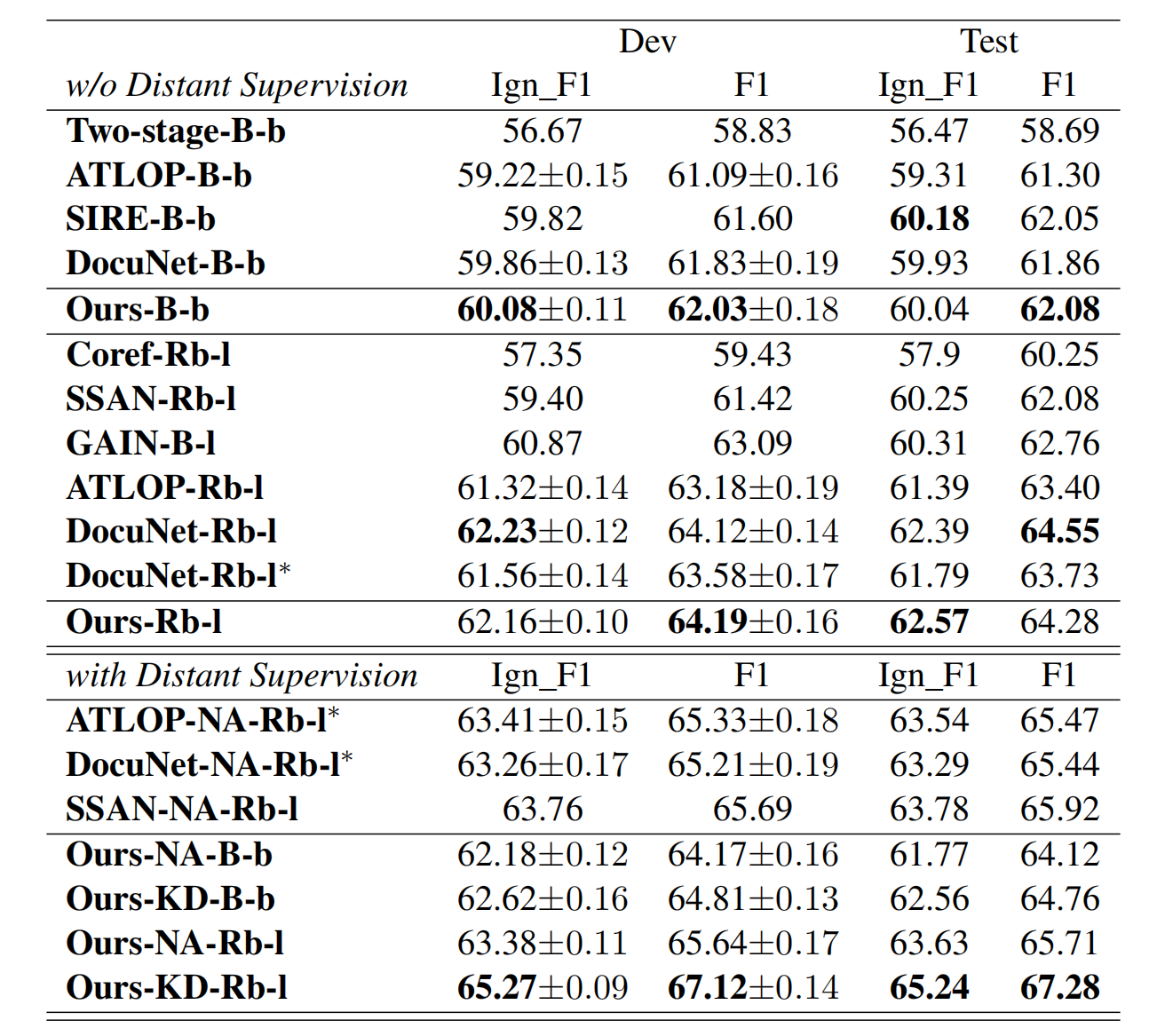
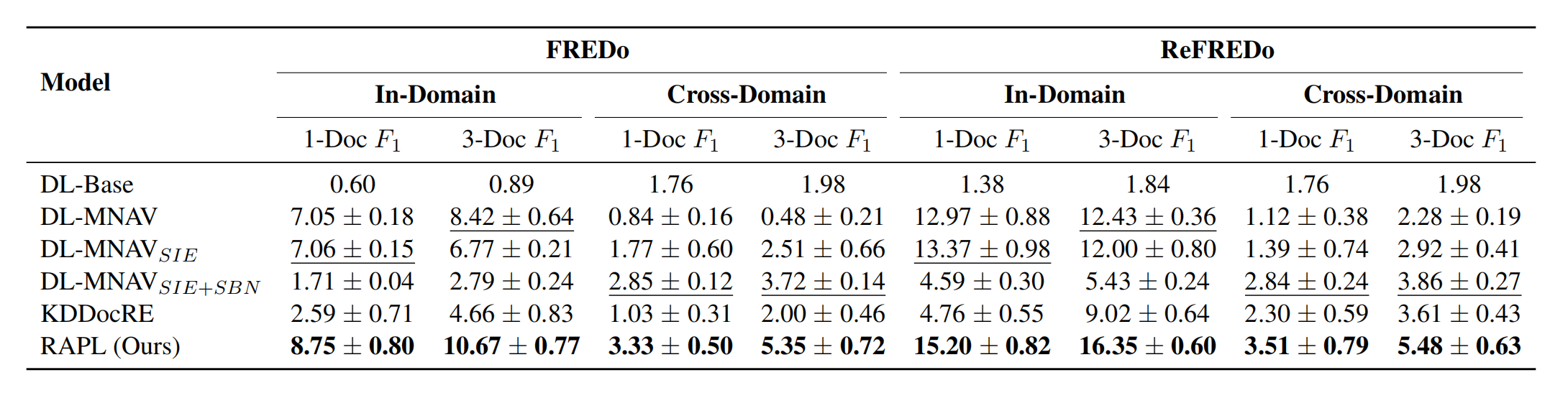
实验