SQL查询优化大致上可以分为两种:
- 物理查询优化:通过索引和表连接方式等技术进行优化
- 逻辑查询优化:通过SQL等价变换来提升查询效率
索引创建的基本原则
联合索引优于单值索引
若WHERE过滤条件中有涉及到多个列,那么对多个列创建联合索引的查询效率高于对单个列创建的索引查询效率
最佳左前缀法则
在MySQL建立联合索引时,会遵循最佳左前缀匹配原则,在检索数据时从联合索引的最左边开始匹配。也就是说,过滤条件要使用索引必须按照索引建立时的顺序,一旦某个顺序与联合索引的顺序不匹配,后面的字段无法使用索引。
引文件具有B-Tree的最左前缀匹配特性,如果左边的值未确定,那么无法使用此索引。
索引失效的情况
索引对于查询速度至关重要:
- 使用索引时,可以利用B+树的查找,快速找到某条记录
- 没有使用索引,就会顺序扫描表中的所有记录
但是,用不用索引最终都是优化器说了算。SQL语句是否使用索引,与数据库版本、数据量、数据选择度(如查询所有记录)有关
主键插入顺序
若不按照顺序插入主键,就可能引起页分裂,产生性能损耗。最好让插入的记录的主键值依次递增,这样就不会发生这样的性能损耗了。
建议:
- 让主键具有
AUTO_INCREMENT,让存储引擎自己为表生成主键,而不是我们手动插入
计算、函数导致索引失效
- 使用函数时,不会用到索引:
1 | EXPLAIN SELECT SQL_NO_CACHE * FROM student WHERE LEFT(student.name,3) = 'abc'; |

- 进行运算时,不会用到索引:
1 | EXPLAIN SELECT SQL_NO_CACHE id, stuno, NAME FROM student WHERE stuno+1 = 900001; |

类型转换导致索引失效
不管是显示的还是隐式的类型转换,都会导致索引失效:
1 | # 索引失效 |
范围条件右侧的列索引失效
范围查找所对应列应该放到联合索引的最右侧,否则会导致范围查找右侧的列索引失效:
1 | # 对classid进行范围查找,但是没有放在联合索引的最右侧 |
不等于导致索引失效
过滤条件中使用不等于符号!=或者<>,会导致索引失效
is null可以使用索引,is not null无法使用索引
like以通配符%开头索引失效
左模糊或者全模糊搜索,会导致索引失效:
1 | EXPLAIN SELECT * FROM student WHERE name LIKE '%ab'; |

OR 前后存在非索引的列,索引失效
字符集不统一导致索引失效
不同的字符集进行比较前需要进行转换,会造成索引失效
关联查询优化
在进行外连接/内连接查询时,在被驱动表上建立索引更好:
- 外连接,以左外连接为例,被驱动表是右边的表:
1 | # 在book.card上建立索引可以避免全表扫描,此时book是被驱动表 |
- 内连接,内连接中的两个表都是同等地位的,由优化器决定谁是被驱动表:
1 | # 在type.card或者book.card上建立索引都可 |
注意:
对于内连接来说,若两个表上都有索引,优化器会选择小表作为驱动表,大表作为被驱动表(小表驱动大表)
JOIN语句的原理
前两种是 Nested-Loop Join 嵌套循环连接的方式
MySQL 8.0推出新特性,Hash Join 哈希连接
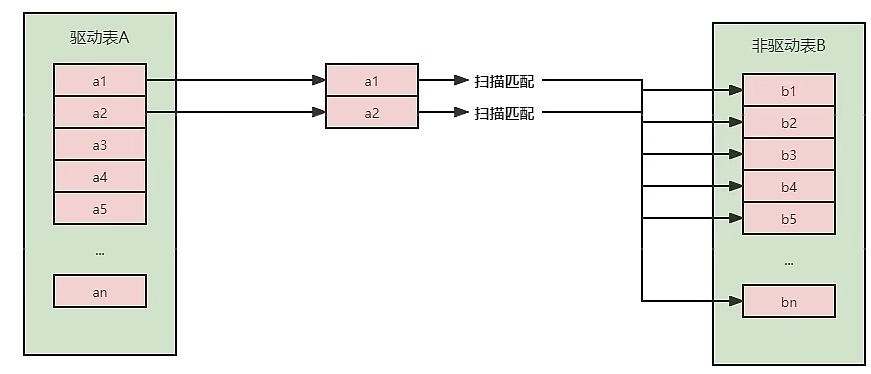
被驱动表上没有索引
若表A是驱动表,表B是被驱动表。若没有索引,会对被驱动表上进行全表扫描。
JOIN语句的执行流程是:依次取出表A中的数据,一行一行的遍历表B
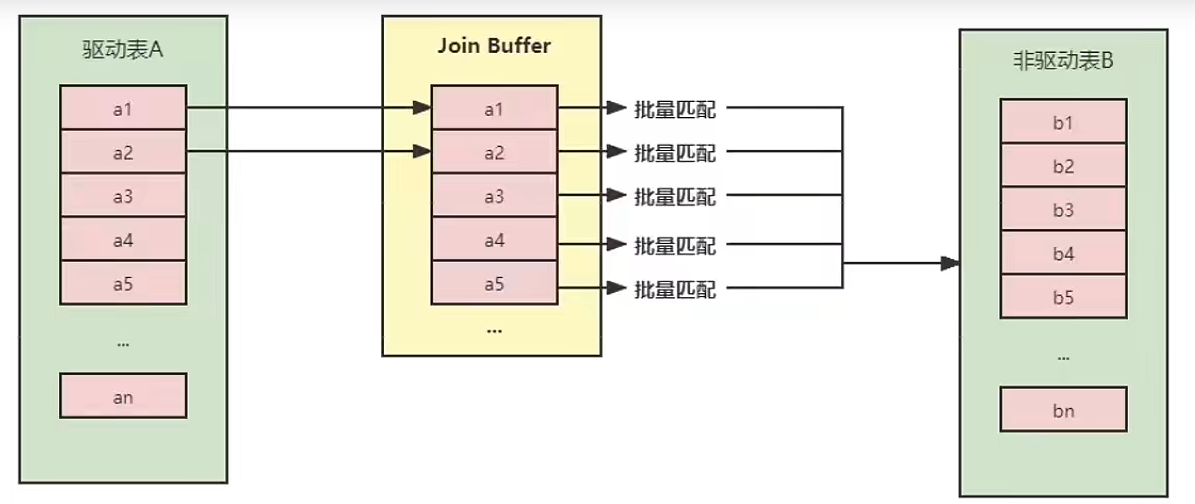
优化:对于驱动表而言,一条一条取数据会进行很多次IO。为了减少IO,可以一次性读取多条驱动表中的数据组成一个块,放入内存中的join buffer中,被驱动表的每条记录一次性和join buffer中所有驱动表记录进行匹配:
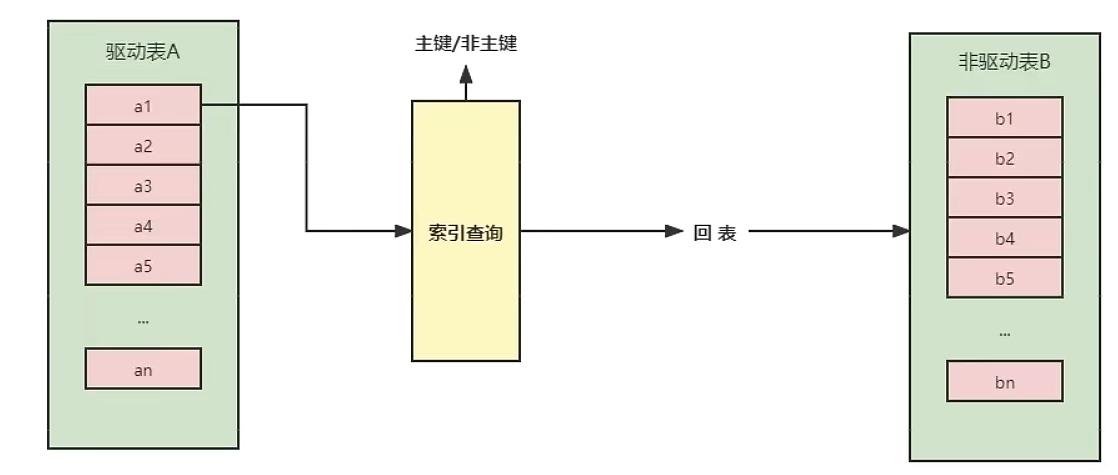
被驱动表示有索引
若A是驱动表,B是被驱动表,被驱动表上有索引
JOIN语句的执行流程是:依次从A中取出数据,根据索引查询被驱动表B
总结
- 小表驱动大表(为了减少外层循环的次数,外层循环即驱动表的数据量)
- 为被驱动表添加索引
- 增加join buffer大小
MySQL 8.0新特性:hash join
hash join(哈希连接)分为两个阶段:
- 选择一个表(一般情况下是较小的那个表,以减少建立哈希表的时间和空间),对其中每个元组上的连接属性采用哈希函数得到哈希值,从而建立一个哈希表
- 对另一个表,扫描它的每一行并计算连接属性的哈希值,从哈希表中进行匹配
子查询优化
子查询执行效率不高,原因:
- 执行子查询时,MySQL需要为内层查询语句的查询结果建立一个临时表,然后外层查询语句从临时表中查询记录。查询完毕后,再撤销这些临时表。这样会消耗过多的CPU和IO资源,产生大量的慢查询
- 子查询的结果集存储的临时表,不论是内存临时表还是磁盘临时表都 不会存在索引 ,所以查询性能会受到一定的影响
优化思路:可以使用连接(JOIN)查询来替代子查询。连接查询不需要建立临时表,其速度比子查询要快,如果查询中使用索引的话,性能就会更好
排序优化
MySQL排序方式
在MySQL种,支持两种排序方式,分别是FileSort和Index:
Index排序中,索引可以保证数据的有效性,无需进行排序,效率高FileSort排序在内存中利用排序算法进行排序,效率低
优化思路
基本思想是:
在需要排序的列上建立索引,避免使用FileSort进行排序,而是使用Index进行排序
优先使用覆盖索引
在非聚簇索引(覆盖索引也记录主键)中,建索引的字段正好是覆盖查询条件中所涉及的字段,此时不用回表操作,这样的索引是覆盖索引
注意:回表是随机IO,所以覆盖索引在范围查询时,可以将随机IO变为顺序IO
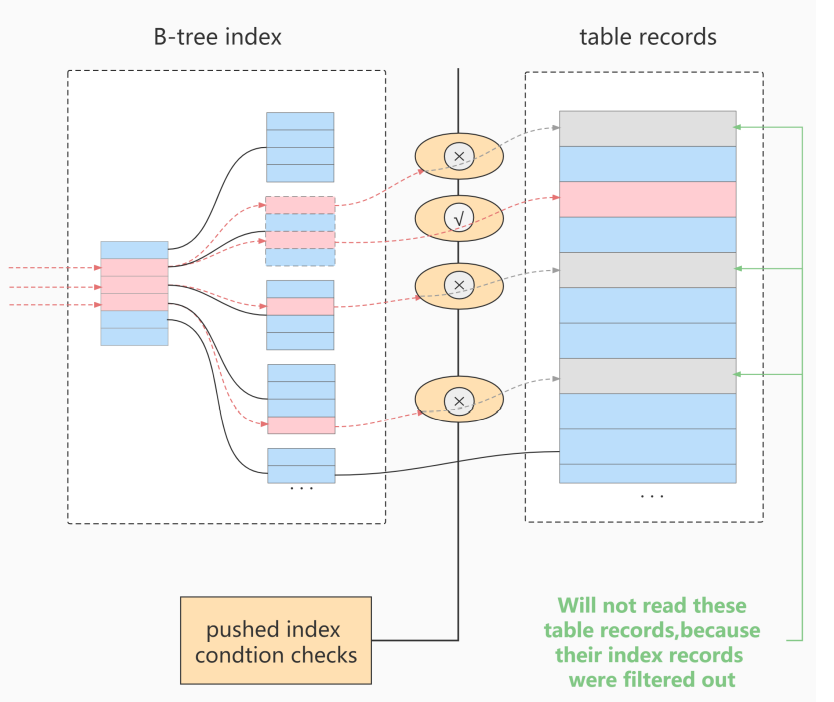
索引下推
索引下推Index Condition Pushdown(ICP)是MySQL 5.6中的新特性,是一种在存储引擎层使用索引过滤数据的一种优化方式。
ICP可以减少存储引擎访问基表(主键索引)的次数以及MySQL服务器访问存储引擎的次数。
原理
在联合索引中,过滤条件使用到了索引的字段,但是部分索引失效了,可以使用索引条件下推在回表之前进行数据过滤
不使用ICP
在不使用ICP时,存储引擎在查询索引时,对索引失效的字段不做过滤,回表后再一并使用过滤条件进行过滤:
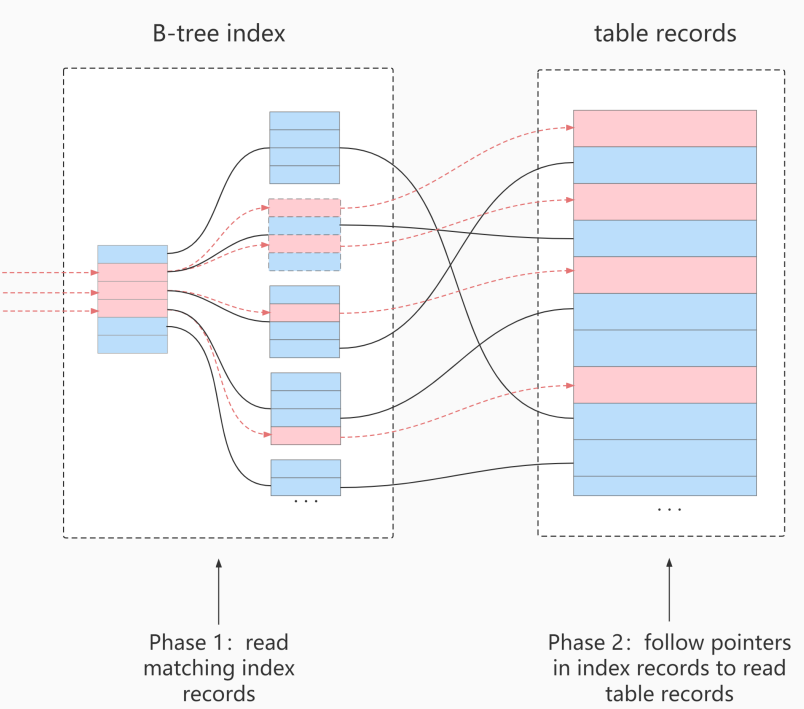
使用ICP
在使用ICP时,存储引擎在查询索引时,对于索引失效的字段先进行条件过滤,再进行回表操作: