范式
在关系型数据库中,关于数据表设计得基本原则/规则,就称为范式(Normal Form,NF)。目前关系型数据库有六种常见范式,按照范式级别从低到高分别是:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF)
数据库得范式设计越高阶,冗余度越低,同时高阶范式一定满足低阶范式得要求。一般在关系型数据库设计中,最高也就遵循到BCNF,普遍还是3NF。但是有些时候为了提高查询性能,还需要破坏范式规则,称为反规范化。
键和相关属性
范式得定义会使用到主键和候选键,数据库中的键由一个或者多个属性组成。数据库中常用得几种键和属性得定义如下:
- 超键:能唯一标识元组得属性集叫做超键
- 候选键:如果超键不包括多余的属性,那么这个超键就是候选键
- 主键:用户可以从候选键中选择一个作为主键
- 外键:如果数据表R1中的某属性集不是R1的主键,而是另一个表R2的主键,那么这个属性集就是数据表R1的外键
- 主属性:包含在任一候选键中的属性称为主属性
- 非主属性:不包含在任何一个候选键中的属性
第一范式
第一范式主要确保数据表中的每个字段的值必须具有原子性,也就是说数据表中的每个字段的值都是不可再拆分的最小数据单元
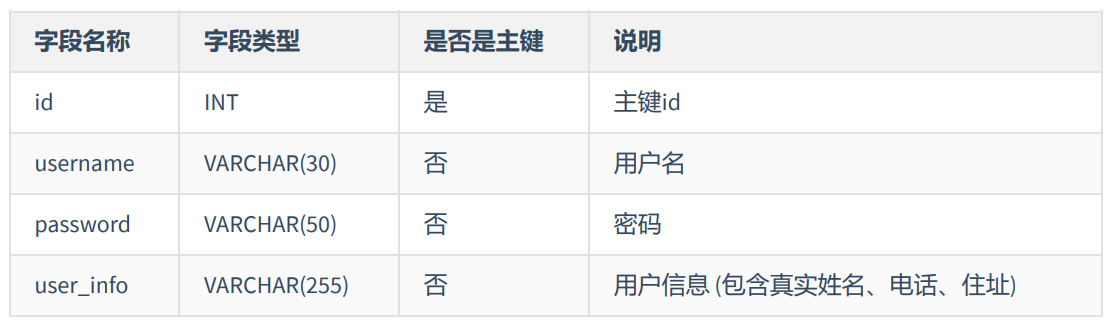
如user表的设计不符合第一范式,user_info字段为用户信息,可以进一步拆分成更小粒度的字段,不符合数据库设计对第一范式的要求:
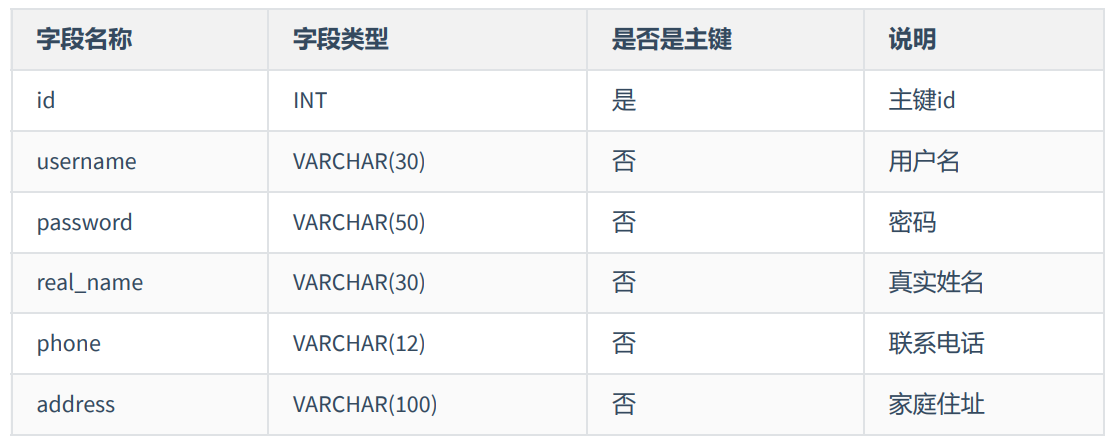
应该将user_info进一步拆分,才符合第一范式:
第二范式
第二范式要求,在满足第一范式的基础上,还要满足数据表中的每一条数据记录,都是唯一可标识的。而且所有的非主键字段,都必须完全依赖主键,不能只依赖主键的一部分。如果知道主键的所有属性的值,就可以检索到任何行的任何属性任何值。
如比赛表里面包含球员编号、姓名、年龄、比赛编号、比赛时间和比赛场地等属性,这里候选键和主键都为(球员编号,比赛编号),我们可以通过候选键(或主键)来决定如下的关系:
1 | (球员编号, 比赛编号) → (姓名, 年龄, 比赛时间, 比赛场地,得分) |
但是这个数据表不满足第二范式,因为数据表中的字段之间还存在着如下的对应关系:
1 | (球员编号) → (姓名,年龄) |
对于非主属性而言,并非完全依赖于候选键,会产生以下问题:
- 数据冗余:如果一个球员可以参加 m 场比赛,那么球员的姓名和年龄就重复了 m-1 次。一个比赛也可能会有 n 个球员参加,比赛的时间和地点就重复了 n-1 次
- 插入异常:如果我们想要添加一场新的比赛,但是这时还没有确定参加的球员都有谁,那么就没法插入
- 删除异常:如果我要删除某个球员编号,如果没有单独保存比赛表的话,就会同时把比赛信息删
除掉 - 更新异常:如果我们调整了某个比赛的时间,那么数据表中所有这个比赛的时间都需要进行调整,否则就会出现一场比赛时间不同的情况
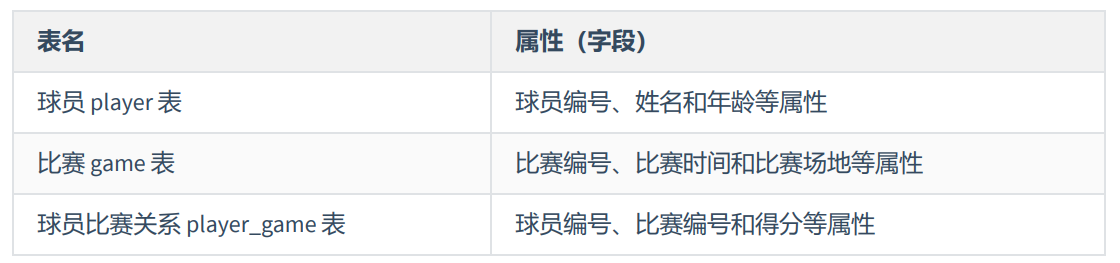
为了避免以上情况,可以把比赛表划分为多个表,这些表都满足第二范式:
1NF 告诉我们字段属性需要是原子性的,而 2NF 告诉我们一张表就是一个独立的对象,一张表只
表达一个意思
第三范式
第三范式是在第二范式的基础上,确保数据表中的每个非主键字段和主键字段直接相关。也就是说,要求数据表中的所有非主键字段不能依赖于其他非主键字段。所有的非主键属性之间不能存在依赖关系,必须相互独立。
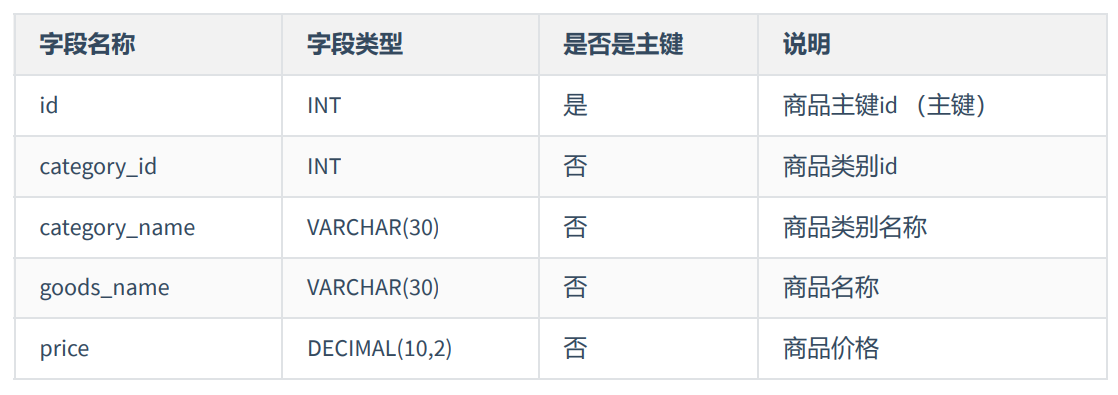
如商品类别名称依赖于商品类别编号,不符合第三范式:
符合第三范式的商品类别表的设计:

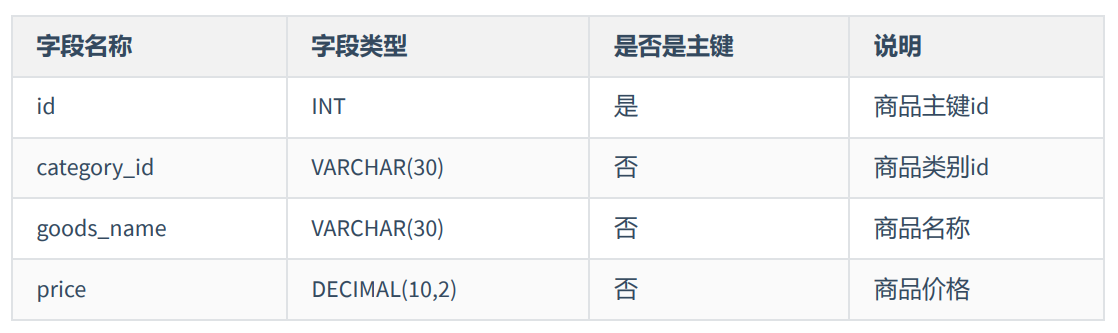
符合第三范式的商品表的设计:
小结
对于三种范式:
- 第一范式:确保每列数据的原子性
- 第二范式:确保每列和主键完全依赖
- 第三范式:确保每列和主键直接相关,而不是间接相关(非主属性之间不能存在依赖关系)
反范式化
概述
应该遵循业务优先的原则,首先满足业务需求,再尽量减少冗余。范式化可能在查询时产生大量关联,有时为了提高查询效率可以进行反范式化。通过在数据表中增加冗余字段来提高数据库的读性能。
1 | 规范化 vs 性能: |
举例
员工的信息存储在employees表 中,部门信息存储在departments表 中。通过employees表中的department_id字段与departments 表建立关联关系。如果要查询一个员工所在部门的名称:
1 | select employee_id,department_name |
如果经常需要进行这个操作,连接查询就会浪费很多时间。可以在employees表中增加一个冗余字段department_name,这样就不用每次都进行连接操作了
反范式化的问题
- 存储空间变大了
- 一个表中字段做了修改,另一个表中冗余的字段也需要做同步修改,否则数据不一致
- 若采用存储过程来支持数据的更新、删除等额外操作,如果更新频繁,会非常消耗系统资源
- 在数据量小的情况下,反范式不能体现性能的优势,可能还会让数据库的设计更加复杂
巴斯 第四范式
巴斯范式
在第三范式的基础上,提出了巴斯范式(巴斯-科德范式)。巴斯范式没有新的设计规范加入,只对第三范式中设计规范的要求更强,使得数据库的冗余度更小:
若一个关系达到第三范式,并且只有一个候选键,或者每个候选键都是单属性的,则达到了巴斯范式。
引入巴斯范式,它在 3NF 的基础上消除了主属性对候选键的部分依赖或者传递依赖关系
第四范式
多值依赖的概念:
- 多值依赖即属性之间的一对多关系,记为
K→→A - 函数依赖事实上是单值依赖,不能表达属性值之间一对多的关系
- 平凡的多值依赖:全集U=K+A,一个K可以对应多个A,即
K→→A。此时整个表是一组一对多的关系 - 非平凡的多值依赖:全集U=K+A+B,一个K可以对应多个A,也可以对应多个B,即
K→→A、K→→B。整个表有多组一对多关系
第四范式,就是在满足巴斯范式的基础上,消除非平凡并且非函数依赖的多值依赖。(把同一个表中的多对多关系删除)
ER模型
概述
ER模型用于描述/设计数据库。ER 模型中有三个要素,分别是实体、属性和关系:
- 实体(表) :可以看做是数据对象,往往对应于现实生活中的真实存在的个体。在 ER 模型中,用矩形来表示。实体分为两类,分别是强实体和弱实体
- 强实体是指不依赖于其他实体的实体
- 弱实体是指对另一个实体有很强的依赖关系的实体
- 属性(列):指实体的特性。在 ER 模型中用椭圆形表示
- 关系:则是指实体之间的联系。在 ER 模型中用菱形表示
关系的类型
关系可以分成三类:一对一、一对多、多对多(、自我引用)
一对一关系
- 一个表中的一条记录,对应另一张表的一条记录。
- 在实际开发中应用不多(可以将常用信息与非常用信息拆开成为两张表,形成一对一关系),因为可以制成一张表。
- 两种建表原则:
- 外键唯一:主表的主键和从表的外键,形成主外键关系,外键唯一
- 外键是主键:主表的主键和从表的主键,形成主外键关系
一对多关系
- 常见关系:客户表和订单表,分类表和商品表,部门表和员工表,学生表和成绩表
- 一对多建表原则:在从表(多方)创建一个字段,字段作为外键指向主表(一方)的主键
多对多关系
- 要表示多对多的关系,必须创建第三个表,称为联接表,将多对多关系划分为两个一对多关系,将这两个表的主键都插入第三个表中。
- 例如:
- 学生信息表、课程信息表、选课信息表(联接表):一个学生可以选多门课,一门课可以被多个学生选择
- 产品表、订单表、订单明细表(联接表)