概述
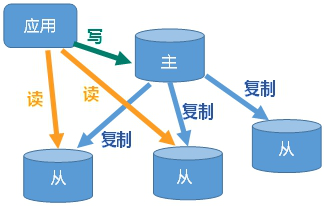
主从复制就是,主机数据更新后,自动同步到备机的master/slaver机制,master以写为主,slaver以读为主。
好处:
- 读写分离
- 容灾快速恢复(一台服务器宕机了,转到其他服务器)
1 | # 在从机上使用slaveof命令加入主机,host为主机地址,port为主机端口 |
原理
当从服务器首次连接上主服务器后(全量复制):
- 当从服务器连接上主服务器后,向主服务器发生数据同步消息
- 主服务器接到从服务器发送过来的同步消息,首先主服务器进行数据持久化,将数据保存到rdb文件中,再把rdb文件发送给从服务器
- 从服务器拿到rdb文件进行读取、同步
每次主服务器进行写操作后(增量复制):
- 主服务器主动将写命令依次传给从服务器,完成同步
当从服务器网络断开后(增量复制或者全量复制):
- 主服务器会维护一个缓冲区,缓冲近期的命令。
- 从节点断开重连后,如果从节点发送的 offset 落在缓冲区内,就进行增量复制;否则进行全量复制。
常用搭建方式
一主二(多)从
一个主机,两个从机。
- 从服务器宕机后恢复,需要重新设置主服务器
- 主服务器宕机后恢复,无需重新设置从服务器
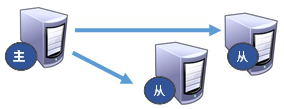
薪火相传
上一个slave可以是写一个slave的master。
好处:
- 主服务器只需要同步一台从服务器,剩下的从服务器的同步由下一个从服务器完成同步,有效的降低了主服务器的压力
缺点:
- 链上的某个从服务器宕机,后面的从服务器无法同步

反客为主
当一个master宕机后,后面的slave可以立刻升为master,其后面的slave不用做任何修改。
slaveof on one 可以将从服务器变为主服务器,原来同步的数据不会丢失。
缺点:需要手动操作。
哨兵模式
哨兵模式是反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从服务器转换为主服务器。
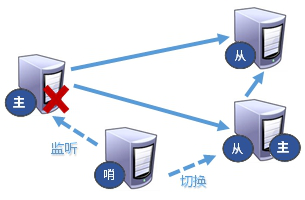
切换工作方式如下:
- 优先级:在 redis.conf 中设置,slave-priority 100,值越小优先级越高
- 偏移量:偏移量是指获得原主机数据最全的
- runid:每个redis实例启动后都会随机生成一个40位的runid
搭建方法
首先编写哨兵配置文件
sentinel.conf:1
2
3
4sentinel monitor [为监控对象起的服务器名称] [主服务器IP] [主服务器端口] [至少需要有多少个哨兵同意迁移]
# sentinel monitor <master-name> <ip> <redis-port> <quorum>
如:
sentinel monitor mymaster 127.0.0.1 6379 1启动哨兵:
1
redis-sentinel sentinel.conf路径
- 哨兵之间如何相互发现?
哨兵节点之间是通过 Redis 的发布者/订阅者机制来相互发现的。在主从集群中,主节点上有一个名为
__sentinel__:hello的频道,不同哨兵就是通过它来相互发现,实现互相通信的。
- 哨兵如何知道从节点的信息?
主节点知道所有从节点的信息,所以哨兵会每 10 秒一次的频率向主节点发送 INFO 命令来获取所有从节点的信息。
作用
哨兵sentinel有三个作用:
- 监控:sentinel会不断地检查你的主服务器和从服务器是否运作正常
- 通知:把新主节点的相关信息通知给从节点和客户端。
- 自动故障迁移:当一个主服务器不能正常工作时,sentinel会开始一次自动故障迁移操作, 它会将失效主服务器的其中一个从服务器升级为新的主服务器, 并让失效主服务器的其他从服务器改为复制新的主服务器; 当客户端试图连接失效的主服务器时, 集群也会向客户端返回新主服务器的地址, 使得集群可以使用新主服务器代替失效服务器。
工作方式
- 每个哨兵sentinel进程以每秒钟一次的频率向整个集群中的master、slaver以及其他sentinel发送PING命令。
- 如果一个实例在发送PING命令后超时,那么这个实例会被这个哨兵标记为主观下线。
- 如果一个master被标记为主观下线,则正在监视这个master的所有sentinel要以每秒一次的频率确认master服务器是否真的进入了主观下线
- 当足够数量的sentinel在指定的时间范围内确认master进入了主观下线状态,那么master会被标记为客观下线。
- 在一般情况下, 每个sentinel会以每10秒一次的频率向集群中的所有master和slaver发送INFO命令。当master被sentinel标记为客观下线时,sentinel向master治下的所有slaver发送的INFO命令会从10秒一次改为1秒一次。
- 当master被标记为客观下线后,sentinel之间会进行一次投票,选举出一个sentinel进行自动故障迁移操作。
上述流程涉及到三个方面:
- 如何判断主节点下线?
- 由哪个哨兵进行故障转移?
- 故障转移的流程?
如何判断主节点下线
判断主节点下线分为两步:判断主观下线,判断客观下线。
- 哨兵会每隔 1 秒给所有主从节点发送 PING 命令,如果在一定的时间内没有收到响应,则会被标记为主观下线。
有可能主节点其实并没有故障,可能只是因为主节点的系统压力比较大或者网络发送了拥塞,导致主节点没有在规定时间内响应哨兵的 PING 命令。所以,为了减少误判的情况,哨兵在部署的时候不会只部署一个节点,而是用多个节点部署成哨兵集群,通过多个哨兵节点一起判断,就可以就可以避免单个哨兵因为自身网络状况不好,而误判主节点下线的情况。
- 当一个哨兵判断主节点为主观下线后,就会向其他哨兵发起命令,其他哨兵赞成投票或者拒绝投票。当这个哨兵的赞同票数达到哨兵配置文件中的 quorum 配置项设定的值后,这时主节点就会被该哨兵标记为客观下线。
由哪个哨兵进行故障转移
哨兵是以哨兵集群的方式存在的,由哨兵集群中的哪个节点进行主从故障转移呢?所以这时候,还需要在哨兵集群中选出一个 leader,让 leader 来执行主从切换故障转移。哨兵 leader 选举分为两步:确定候选者,选举 leader。
- 确定候选者:哪个哨兵判断主节点为客观下线,哪个哨兵就是候选者(同一时段内可能多个哨兵判断客观下线,所以有多个候选者)。
- 选举 leader:候选者会向其他哨兵发送命令,让其他哨兵进行投票。每个哨兵只有一次投票机会,如果用完后就不能参与投票了。需要拿到半数以上的选票,并且拿到的票数同时还需要大于等于哨兵配置文件中的 quorum 值,才可以成为 leader。
故障转移流程
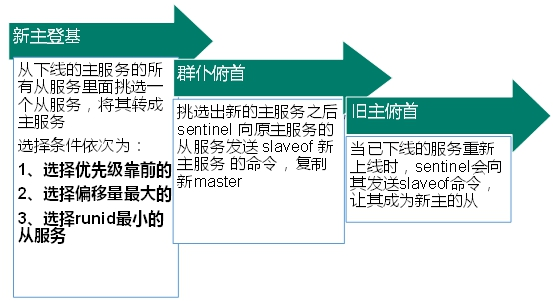
主从故障转移操作包含以下四个步骤:
- 第一步:在已下线主节点属下的所有从节点里面,挑选出一个从节点,并将其转换为主节点。
- 第二步:让已下线主节点属下的所有从节点修改复制目标,修改为复制新主节点;
- 第三步:将新主节点的 IP 地址和信息,通过发布/订阅机制通知客户端;
- 第四步:继续监视旧主节点,当这个旧主节点重新上线时,将它设置为新主节点的从节点。
选出新的主节点
选新的节点熟悉过滤掉网络不好的从节点(如果发生断连的次数超过了 10 次,就说明这个从节点的网络状况不好,不适合作为新主节点),接着按照以下条件进行筛选:
- 优先级:在 redis.conf 中设置,slave-priority 100,值越小优先级越高
- 偏移量:偏移量是指获得原主机数据最全的
- runid:每个redis实例启动后都会随机生成一个40位的runid,选择最小的从节点。
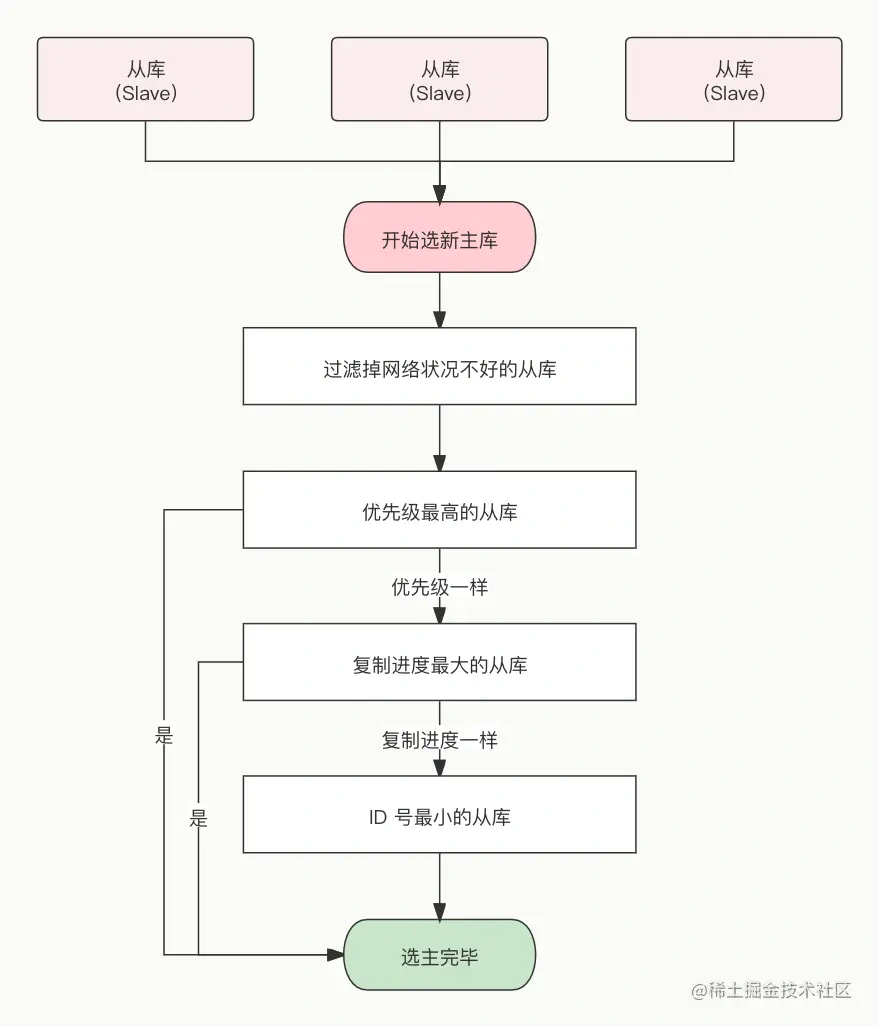
哨兵 leader 向被选中的从节点发送 SLAVEOF no one 命令,将该从节点升级为新主节点。在发送 SLAVEOF no one 命令之后,哨兵 leader 会以每秒一次的频率向被升级的从节点发送 INFO 命令(没进行故障转移之前,INFO 命令的频率是每十秒一次),并观察命令回复中的角色信息,当被升级节点的角色信息从原来的 slave 变为 master 时,哨兵 leader 就知道被选中的从节点已经顺利升级为主节点了。
从节点指向新的主节点
哨兵 leader 像所有从节点发送 SLAVEOF <new_ip> <new_port> 命令,让所有从节点指向新的主节点。
通知客户端
每个哨兵节点提供发布/订阅机制,客户端可以从哨兵订阅消息。哨兵提供的消息订阅频道有很多,不同频道包含了主从节点切换过程中的不同关键事件,几个常见的事件如下:
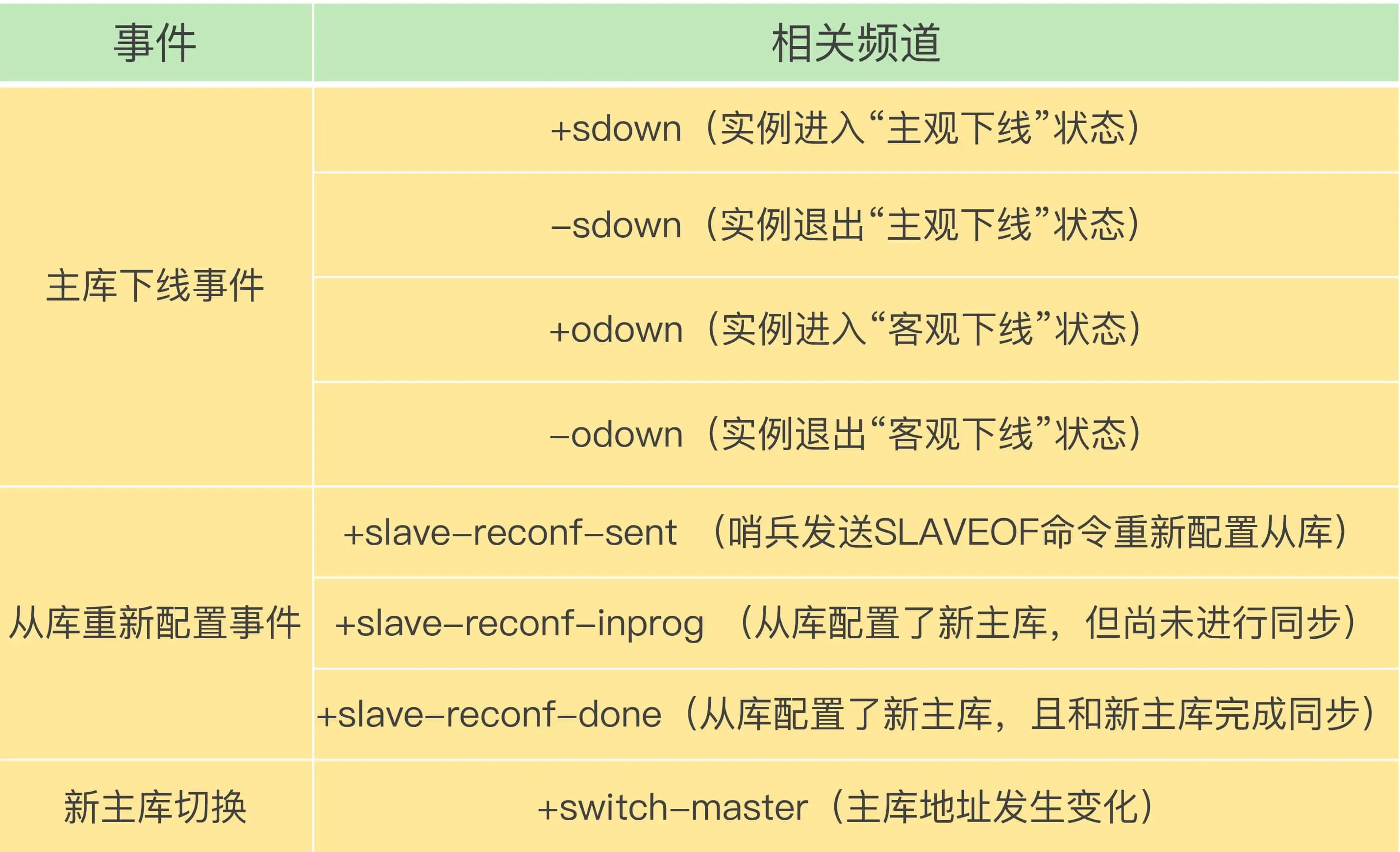
客户端和哨兵建立连接后,客户端会订阅哨兵提供的频道。主从切换完成后,哨兵就会向 +switch-master 频道发布新主节点的 IP 地址和端口的消息,这个时候客户端就可以收到这条信息,然后用这里面的新主节点的 IP 地址和端口进行通信了。
旧的主节点变为从节点
故障转移操作最后要做的是,继续监视旧主节点,当旧主节点重新上线时,哨兵集群就会向它发送 SLAVEOF 命令,让它成为新主节点的从节点。