消息队列通信模型
队列模式
消息⽣产者⽣产消息发送到队列queue中,然后消息消费者从queue中取出并且消费消息。 ⼀条消息被消费以后,queue中就没有了,不存在重复消费。
发布/订阅
消息⽣产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点⽅式不同,发布到topic的消息会被所有订阅者消费
发布订阅模式下,当发布者消息量很⼤时,显然单个订阅者的处理能⼒是不⾜的。实际上现实场景中是多个订阅者节点组成⼀个订阅组负载均衡消费topic消息即分组订阅,这样订阅者很容易实现消费能⼒线性扩展。可以看成是⼀个topic下有多个queue,每个queue是点对点的⽅式,queue之间是发布订阅⽅式。
Kafka
Kafka是一种高吞吐量的分布式发布订阅消息系统。
同时Kafka结合队列模型和发布订阅模型:
- 对于同一个消费者组Consumer Group,一个message只有被一个consumer消费
- 同一个消息可以被广播到不同的Consumer Group中
架构介绍
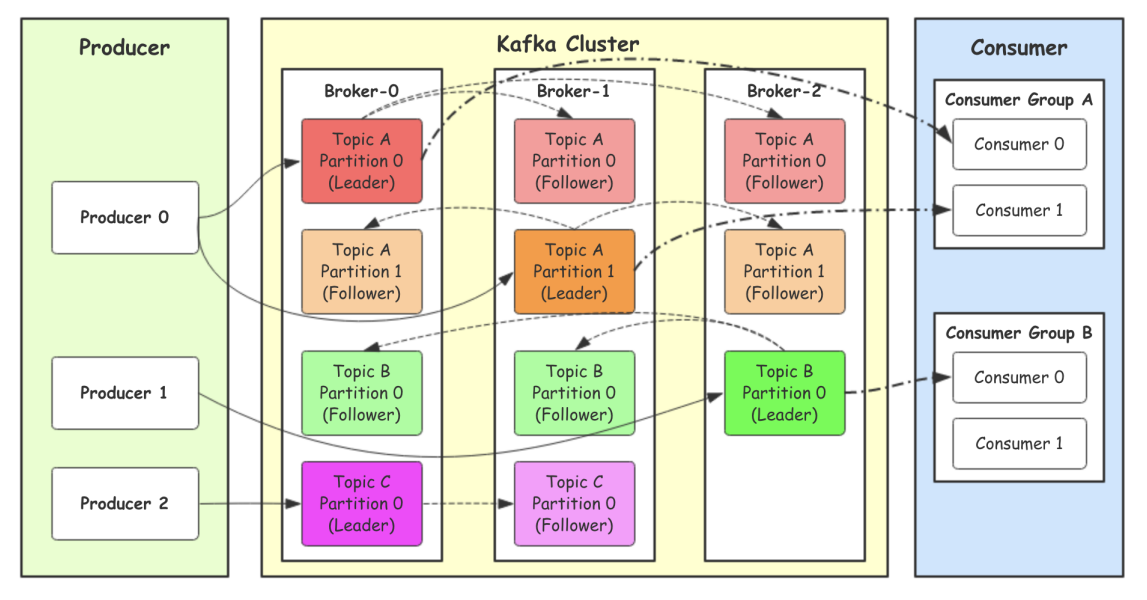
- Producer:Producer即⽣产者,消息的产⽣者,是消息的⼊⼝。
- kafka cluster:kafka集群,⼀台或多台服务器组成
- Broker:Broker是指部署了Kafka实例的服务器节点。每个服务器上有⼀个或多个kafka的实例,我们姑且认为每个broker对应⼀台服务器。每个kafka集群内的broker都有⼀个不重复的编号。
- Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。实际应⽤中通常是⼀个业务线建⼀个topic。
- Partition:Topic的分区,每个topic可以有多个分区,分区的作⽤是做负载,提⾼kafka的吞吐量。同⼀个topic在不同的分区的数据是不重复的,partition的表现形式就是⼀个⼀个的⽂件夹。为了提高可靠性,提出分区的副本,分为Leader和Follower,生产和消费只针对Leader。
- Replication:每⼀个分区都有多个副本,副本的作⽤是做备份。当主分区(Leader)故障的时候会选择⼀个备胎(Follower)上位,成为Leader。在kafka中默认副本的最⼤数量是10个,且副本的数量不能⼤于Broker的数量,follower和leader绝对是在不同的机器,同⼀机器对同⼀个分区也只可能存放⼀个副本(包括⾃⼰)。
- Consumer:消费者,即消息的消费⽅,是消息的出⼝。
- Consumer Group:我们可以将多个消费组组成⼀个消费者组,在kafka的设计中同⼀个分区的数据只能被消费者组中的某⼀个消费者消费。同⼀个消费者组的消费者可以消费同⼀个topic的不同分区的数据,这也是为了提⾼kafka的吞吐量!
工作流程
生产者寻找Leader、写入流程
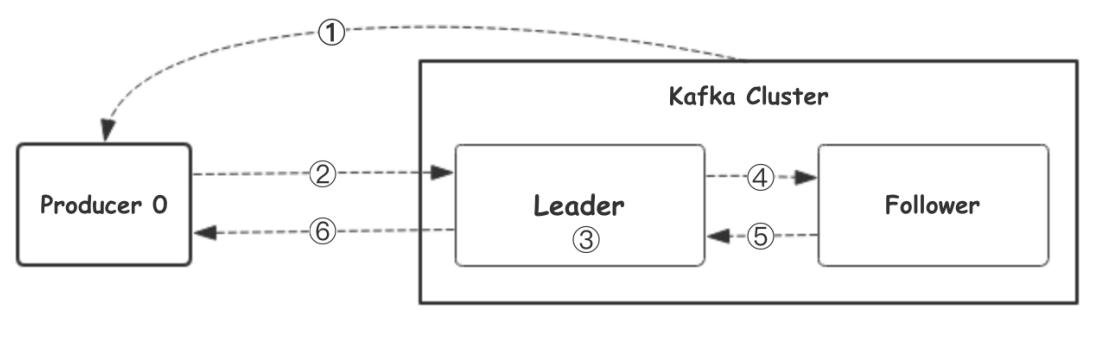
- ⽣产者从Kafka集群获取分区leader信息
- ⽣产者将消息发送给leader
- leader将消息写⼊本地磁盘
- follower从leader拉取消息数据
- follower将消息写⼊本地磁盘后向leader发送ACK
- leader收到所有的follower的ACK之后向⽣产者发送ACK
选择Partition的原则
那在kafka中,如果某个topic有多个partition,producer⼜怎么知道该将数据发往哪个partition呢?
- partition在写⼊的时候可以指定需要写⼊的partition,如果有指定,则写⼊对应的partition。
- 如果没有指定partition,但是设置了数据的key,则会根据key的值hash出⼀个partition。
- 如果既没指定partition,⼜没有设置key,则会采⽤轮询⽅式,即每次取⼀小段时间的数据写⼊某个partition,下⼀⼩段的时间写⼊下⼀个partition。
ACK应答机制
producer在向kafka写⼊消息的时候,可以设置参数来确定是否确认kafka接收到数据,这个参数可设置的值为0、1、all。
0代表producer往集群发送数据不需要等待集群的返回,不确保消息发送成功。安全性最低但是效率最⾼。1代表producer往集群发送数据只要leader应答就可以发送下⼀条,只确保leader发送成功。all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下⼀条,确保leader发送成功和所有的副本都完成备份。安全性最⾼,但是效率最低。
Topic分区数据日志
在Kafka中,对于每一个主题Topic,Kafka集群维护了⼀个分区数据⽇志⽂件:
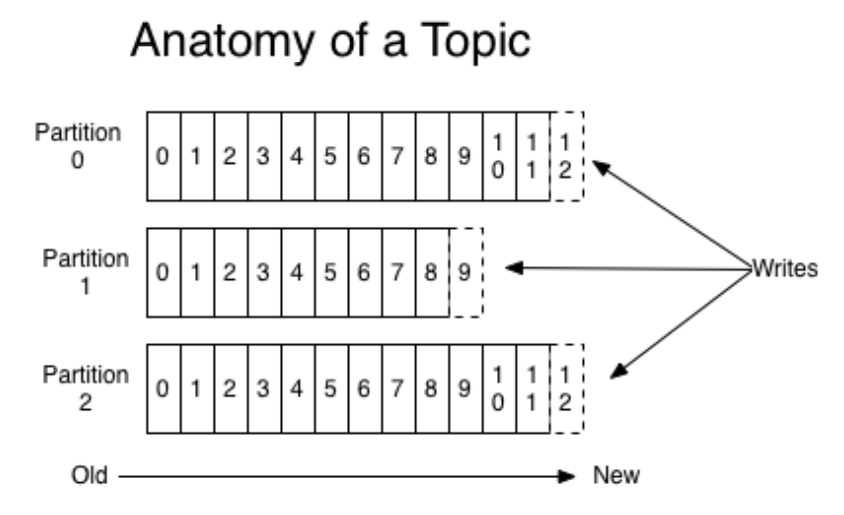
每个partition都是⼀个有序并且不可变的消息记录集合。当新的数据写⼊时,就被追加到partition的末尾。在每个partition中,每条消息都会被分配⼀个顺序的唯⼀标识,这个标识被称为offset,即偏移量。
注意,Kafka只保证在同⼀个partition内部消息是有序的,在不同partition之间,并不能保证消息有序。
Kafka可以配置⼀个保留期限,⽤来标识⽇志会在Kafka集群内保留多⻓时间。Kafka集群会保留在保留期限内所有被发布的消息,不管这些消息是否被消费过。⽐如保留期限设置为两天,那么数据被发布到Kafka集群的两天以内,所有的这些数据都可以被消费。当超过两天,这些数据将会被清空,以便为后续的数据腾出空间。由于Kafka会将数据进⾏持久化存储(即写⼊到硬盘上),所以保留的数据⼤⼩可以设置为⼀个比较⼤的值。
Partition结构
Partition在服务器上的表现形式就是⼀个⼀个的文件夹,每个partition的文件夹包含.index文件、.log文件、.timeindex文件。
其中.log文件就是实际存储消息的地方,而.index文件和.timeindex文件为索引文件,⽤于检索消息。
GO语言操作kafka
GO语言操作kafka需要使用第三方库:github.com/Shopify/sarama
连接kafka发送消息
连接kafka生产消息总体来说需要4步:
- 配置信息,新建配置
sarama.NewConfig() - 生产者连接kafka
- 构造消息
- 发送消息
1 | package main |
连接kafka消费消息
消费者连接kafka消费消息总体来说需要3步:
- 生成消费者
sarama.NewConsumer - 拿到对应主题下的所有分区
- 遍历所有分区:
- 针对每个分区建立一个对应的分区消费者
- 每个分区消费者单独开启一个协程从分区中取出消息
1 | package main |