消息队列
应用场景
- 缓存/消峰:将消息暂存在消息队列中,以生产消息和消费消息的处理速度不一致的情况。
- 解耦:可以修改或者扩充生产者和消费者,只需要遵守消息格式的一致即可。
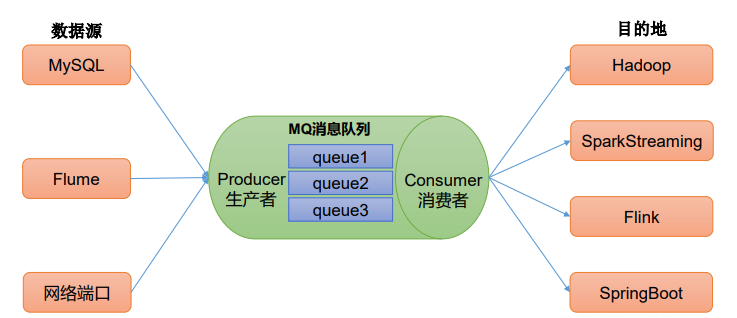
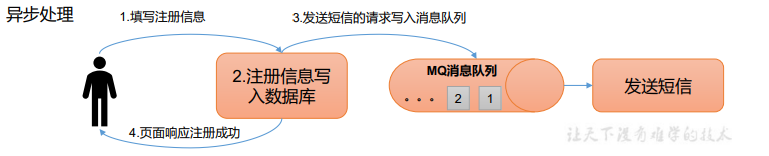
- 异步通信:允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。
消息队列两种模式
点对点模式
类似于队列,消费者消费消息后会清除消息。
发布/订阅模式
消息⽣产者(发布)将消息发布到topic中,同时有多个消息消费者(订阅)消费该消息。和点对点⽅式不同,发布到topic的消息会被所有订阅者消费。
Kafka介绍
Kafka是一种高吞吐量的分布式发布订阅消息系统。
同时Kafka结合点对点模型和发布订阅模型:
- 对于同一个消费者组Consumer Group,一个message只有被一个consumer消费 - 点对点模型
- 同一个消息可以被广播到不同的Consumer Group中 - 发布订阅模型
架构
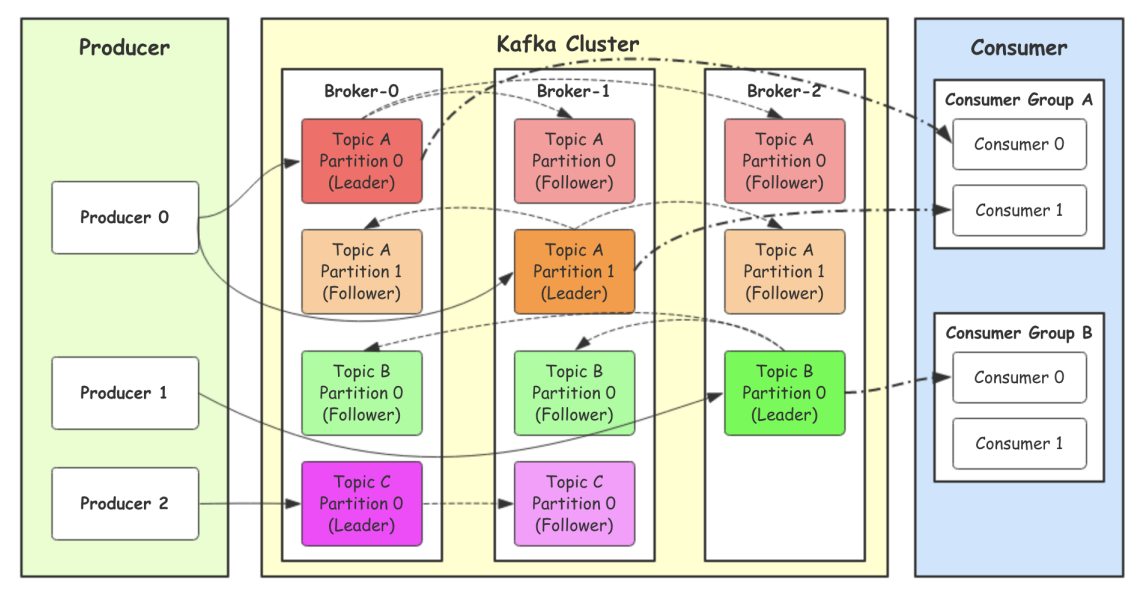
- Producer:Producer即⽣产者,消息的产⽣者,是消息的⼊⼝。
- kafka cluster:kafka集群,⼀台或多台服务器组成
- Broker:Broker是指部署了Kafka实例的服务器节点。每个服务器上有⼀个或多个kafka的实例,我们姑且认为每个broker对应⼀台服务器。每个kafka集群内的broker都有⼀个不重复的编号。
- Topic:消息的主题,可以理解为消息的分类,kafka的数据就保存在topic。在每个broker上都可以创建多个topic。实际应⽤中通常是⼀个业务线建⼀个topic。
- Partition:Topic的分区,每个topic可以有多个分区,分区的作⽤是做负载,提⾼kafka的吞吐量。同⼀个topic在不同的分区的数据是不重复的,partition的表现形式就是⼀个⼀个的⽂件夹。为了提高可靠性,提出分区的副本,分为Leader和Follower,生产和消费只针对Leader。
- Replication:每⼀个分区都有多个副本,副本的作⽤是做备份。当主分区(Leader)故障的时候会选择⼀个备胎(Follower)上位,成为Leader。在kafka中默认副本的最⼤数量是10个,且副本的数量不能⼤于Broker的数量,follower和leader绝对是在不同的机器,同⼀机器对同⼀个分区也只可能存放⼀个副本(包括自己)。
- Consumer:消费者,即消息的消费⽅,是消息的出⼝。
- Consumer Group:我们可以将多个消费组组成⼀个消费者组,在kafka的设计中同⼀个分区的数据只能被消费者组中的某⼀个消费者消费。同⼀个消费者组的消费者可以消费同⼀个topic的不同分区的数据,这也是为了提⾼kafka的吞吐量!
细节:
- 生产者将消息发送给broker,broker会将消息保存在本地日志文件中
- 消息的保存是有序的,通过offset偏移量来描述消息的有序性
- 消费者消费消息时也是通过offset来描述当前要消费的那条消息的位置(默认是最后⼀条消息offset+1位置开始消费)
主题和分区
主题Topic
主题在Kafka中是一个逻辑的概念,Kafka通过topic将消息进行分类。消费者可以订阅topic,所有订阅了这个主题的消费者(组)都可以消费消息。
分区Partition
通过partition可以将一个topic中的消息分区来存储。当新的数据写⼊时,就被追加到partition的末尾。在每个partition中,每条消息都会被分配⼀个顺序的唯⼀标识,这个标识被称为offset,即偏移量。
Partition在服务器上的表现形式就是⼀个⼀个的文件夹,每个partition的文件夹包含.index文件、.log文件、.timeindex文件。其中.log文件就是实际存储消息的地方,而.index文件和.timeindex文件为索引文件,⽤于检索消息。文件中保存的消息,默认保存7天。
分区的好处有多个:
- 分布式存储:解决了一个topic的数据文件过大的问题。
- 并行读写:一个消费者组中的不同消费者可以消费同一个主题下的不同分区;也可以并行生产消息。
注意:Kafka只保证在同⼀个partition内部消息是有序的,在不同partition之间,并不能保证消息有序。
__consumer_offsets主题
Kafka内部有一个自己创建的默认主题__consumer_offsets,包含了50个分区。这个主题⽤来存放消费者消费某个主题的偏移量。因为每个消费者都会自己维护着消费的主题的偏移量,也就是说每个消费者会把消费的主题的偏移量自主上报给kafka的默认主题:
- 提交到哪个分区,分区号计算公式:
hash(consumerGroupID) % __consumer_offsets主题的分区数 - 提交到该主题的内容:key是
consumerGroupID + topic + 分区号,value是当前offset的值