生产者
选择Partition原则
在kafka中,一个topic指定了多个partition,生产者选择partition的方式:
- partition在写⼊的时候可以指定需要写⼊的partition,如果有指定,则写⼊对应的partition。
- 如果没有指定partition,但是设置了数据的key,则会根据key的值hash出⼀个partition。
- 如果既没指定partition,⼜没有设置key,则会采⽤轮询⽅式,即每次取⼀小段时间的数据写⼊某个partition,下⼀⼩段的时间写⼊下⼀个partition。
同步发送和异步发送
同步发送
⽣产者同步发消息,在收到kafka的ACK告知发送成功之前⼀直处于阻塞状态。
异步发送
⽣产者发消息,发送完后不用等待broker给回复,直接执⾏下面的业务逻辑。
注意:异步发送可能会丢失消息。
生产者ACK机制
同步发送的前提下,生产者向集群发送消息时,关于ACK应答机制有3个配置:
0代表producer往集群发送数据不需要等待集群的返回。也就是说,集群不需要任何broker收到消息,就立刻返回ACK给生产者。不确保消息发送成功。安全性最低但是效率最⾼。1代表producer往集群发送数据只要leader应答(Leader将消息写入本地日志中)就可以发送下⼀条,只确保leader发送成功。默认选项。all代表producer往集群发送数据需要所有的follower都完成从leader的同步才会发送下⼀条,确保leader发送成功和所有的副本都完成备份。安全性最⾼,但是效率最低。
生产者发送消息流程
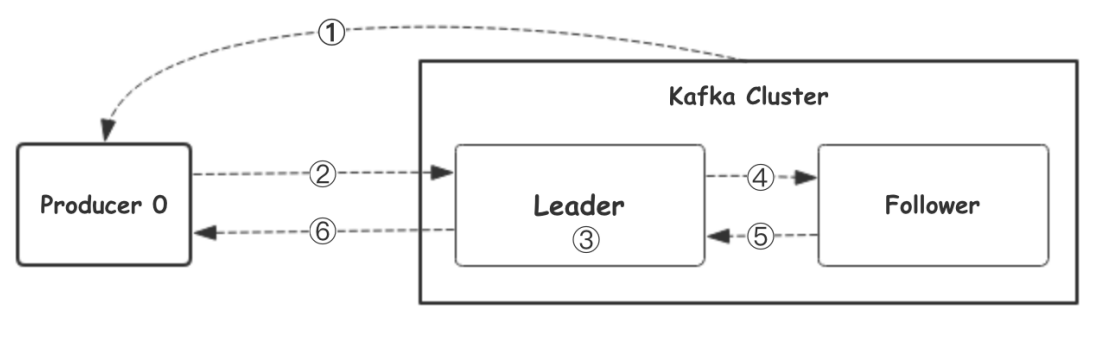
- ⽣产者从Kafka集群获取分区leader信息
- ⽣产者将消息发送给leader
- leader将消息写⼊本地磁盘
- follower从leader拉取消息数据
- follower将消息写⼊本地磁盘后向leader发送ACK
- leader收到所有的follower的ACK之后向⽣产者发送ACK(ACK为
all时)
消费者
消息消费模型
消息的消费模型有两种:推送模型和拉取模型。
推送模型
基于推送模型(push)的消息系统,由消息代理记录消费者的消费状态。消息代理在将消息推送到消费者后,标记这条消息已经消费,但这种方式无法很好地保证消费被处理。
如果要保证消息被处理,消息代理发送完消息后,要设置状态为“已发送”,只要收到消费者的确认请求后才更新为“已消费”,这就需要代理中记录所有的消费状态。
缺点:
- 标记为消费后,其他消费者则不可以再消费了。
- 很难适应消费速率不同的消费者,因为消息发送速率是由broker决定的
拉取模型
基于拉取(pull)模型的消息系统,由消费者自己记录消费状态,每个消费者互相独立地顺序拉取每个分区的消息。
优点:消费者可以按照任意的顺序消费消息。
Kafka就是采用了拉取模型。
消费者消费分区的策略
如果没有显式的指明分区,消费者消费分区有3种策略:
- 通过公式来计算消费者消费哪一个分区
- 消费者轮询消费分区
- sticky:在触发rebalance机制后,在消费者消费的原分区不变的基础上进行调整
Rebalance机制
消费者没有指明分区消费,当消费组⾥消费者和分区的关系发⽣变化,那么就会触发rebalance机制。
优点:
- 给消费者组带来了高可用性和伸缩性
缺点:
- 再均衡期间消费者无法读取消息,整个群组有一小段时间不可用
- partition被重新分配给一个消费者时,消费者当前的读取状态会丢失
提交offset机制
消费者无论是⾃动提交还是手动提交,都需要把所属的消费组+消费的某个主题+消费的某个分区及消费的偏移量,这样的信息提交到集群的_consumer_offsets主题⾥⾯。
自动提交
消费者poll消息下来以后就会⾃动提交offset。
自动提交可能会丢失消息。因为消费者在消费前提交offset,有可能提交完后还没消费时消费者就宕机了。
手动提交
手动提交是指消费完成后提交offset,分为同步和异步的方式:
- 同步:在集群返回ACK之前阻塞
- 异步:提交offset后,不需要等待集群返回的ACK