Controller
什么是Controller
在Kafka中,需要有一个管理者,称为Controller,它在ZooKeeper的帮助下管理和协调整个Kafka集群。Controller本身也是一台Broker节点,只不过需要负责一些额外的工作(追踪集群中的其他Broker,并在合适的时候处理新加入的和失败的Broker节点、Rebalance分区、分配新的leader分区等)。
Kafka集群中始终只有一个Controller Broker。
如何被选举出来
Broker 在启动时,会尝试去 ZooKeeper 中创建/controller的临时序号节点,获得的序号最小的那个broker将会作为集群中的controller。
Controller作用
Controller的作用:
- 当集群中有broker新增或减少,controller会同步信息给其他broker
- 当集群中有分区新增或减少,controller会同步信息给其他broker
处理下线的Broker
Controller可以依据ZooKeeper的Watch机制,来监听Broker的变化。
每个 Broker 启动后,会在zookeeper的/Brokers/ids下创建临时znode。当Broker宕机或主动关闭后,该Broker与ZooKeeper的会话结束,这个znode会自动删除。
ZooKeeper的Watch机制会将节点的变化情况推送给Controller,这样Controller就知道某个Broker宕机了,可以采取行动决定哪些Broker上的分区成为leader分区(选择isr列表中最靠前的作为新的leader)。然后,它会通知每个相关的Broker。
处理新加入到集群中的Broker
大部分情况下,Broker的失败很短暂,这意味着Broker通常会在短时间内恢复。所以当节点离开群集时,与其相关联的元数据并不会被立即删除。
当Controller注意到Broker已加入集群时,它将使用Broker ID来检查该Broker上是否存在分区,如果存在,则Controller通知新加入的Broker和现有的Broker,新的Broker上面的follower分区再次开始复制现有leader分区的消息。为了保证负载均衡,Controller会将新加入的Broker上的follower分区选举为leader分区。
脑裂问题
如果controller Broker 挂掉了,Kafka集群必须找到可以替代的controller,集群将不能正常运转。这里面存在一个问题,很难确定Broker是挂掉了,还是仅仅只是短暂性的故障。但是,集群为了正常运转,必须选出新的controller。如果之前被取代的controller又正常了,他并不知道自己已经被取代了,那么此时集群中会出现两台controller。
比如,某个controller由于GC而被认为已经挂掉,并选择了一个新的controller。在GC的情况下,在最初的controller眼中,并没有改变任何东西,该Broker甚至不知道它已经暂停了。因此,它将继续充当当前controller。现在,集群中出现了两个controller,它们可能一起发出具有冲突的命令,就会出现脑裂的现象。
epoch number
Kafka种,使用使用epoch number(纪元编号)来避免脑裂问题。epoch number只是单调递增的数字,第一次选出Controller时,epoch number值为1,如果再次选出新的Controller,则epoch number将为2,依次单调递增。
每个新选出的controller通过Zookeeper获得获得一个全新的、数值更大的epoch number 。其他Broker 在知道当前epoch number 后,如果收到由controller发出的包含较小epoch number的消息,就会忽略它们。
HW机制
LEO(Log End Offset)是某个副本最后消息的消息位置。
HW(High Watermark)高水位,是指已完成同步的位置。消费者最多只能消费到HW所在的位置。
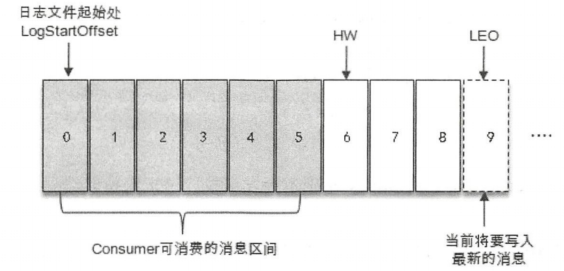
另外,每一个leader和follower各⾃负责更新自己的HW的状态。对于leader新写⼊的消息,consumer不能立刻消费,leader会等待该消息被所有ISR中的副本同步后更新HW,此时消息才能被consumer消费。这样就保证了如果leader所在的broker失效,该消息仍然可以从新选举的leader中获取。