定义
一个经典的机器学习定义如下:
A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E.
比如对于一个垃圾邮件分类程序而言:
- T,识别一封电子邮件是否是垃圾邮件
- E,用户对于邮件的标记是否是垃圾邮件
- P,对垃圾邮件识别的准确率
机器学习算法分类
对于机器学习算法,可以分为:监督学习和非监督学习。简而言之,监督学习就是人为的去教计算机学习一些东西。非监督学习,就是让计算机自己去学习。
监督学习
在监督学习中,对于数据集中的每个样本都带有“正确答案”
- 回归(regression):预测连续值的输出。
- 分类(classification):预测离散值的输出。
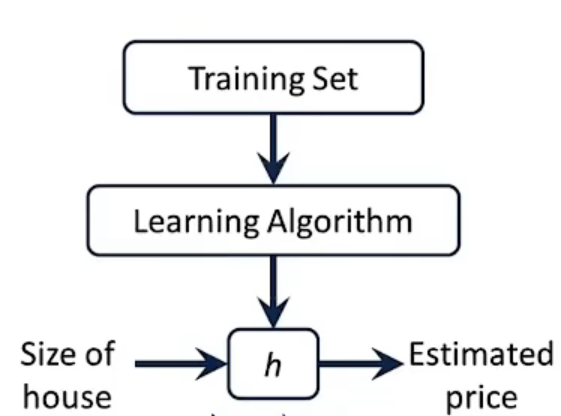
一个监督学习的基本框架如下:将训练集输入到学习算法中,接着学习算法输出一个假设函数h,假设函数h的作用就是表达x与预测值y的映射关系(在图中,x为房屋的面积,y为预测出可以卖出的价格),简而言之就是进行预测的函数:
无监督学习
在无监督学习中,数据集中的每个样本都没有“正确答案”,要求算法找出数据的类型结构。
- 聚类(cluster):在无标签的数据集中,其中的样本会天然的呈现出分类的结构,交给无监督学习算法就是去将这些样本自动的划分为不同的类别。