线性回归
线性回归是一种监督学习算法,我们需要对数据进行预测,以得到一条线性的假设函数h。其中定义函数J为代价函数(Cost Function,也叫代价函数),用于表示对于预测的参数,每一个样本输入值x和它所对应的结果值y之间的差距。我们的目标就是,尽量的优化参数,使得代价函数最小。

梯度下降
梯度下降(Gradient Descent)不仅可以最小化代价函数J,也可以最小化其他函数。
关于如何最小化函数J,一个可行的思路是:
- 初始化所有的参数(通常初始化为0)
- 不断改变参数(关于如何改变参数,就是梯度下降所做的工作),使得函数J减小,直到函数J达到最小值或者局部最小值

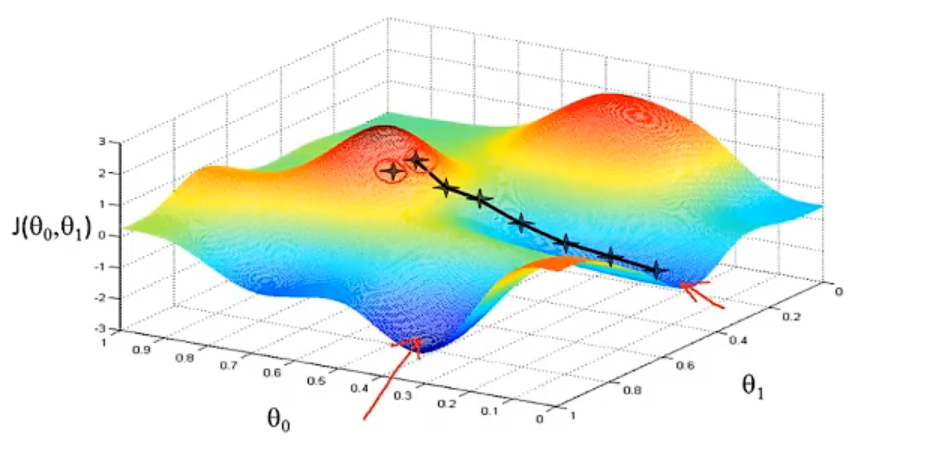
梯度下降最直观的理解就是,假设有两个参数分别作为x和y轴,而相关的代价函数J作为z轴(高度),可以得到有高低起伏的三维图像。
想象这样一种情景,把这个三维图型看为山地,你刚开始站着山上的某一点(初始化的值),每走一步都朝着下山最快的方向(梯度方向)行动,最终一定会到达山地的某个最低点,即函数J的局部最小值(起始点不同,最后找到的局部最小值可能也不同)。
以下是梯度下降算法的具体定义,其中α为学习率,它与移动的步长有关。
- α越小,移动的步长越小,梯度下降的速度越慢
- α越大,移动的步长越大,但是可能在接近最小值时会直接越过最小值
对于多个参数而言,梯度下降对每个参数同步更新。梯度下降可以保证到达一个局部最小值,即使学习率α固定。因为当接近最小值时,偏导数(斜率)会变小,所以下一次梯度下降时移动的步子会更小。因此,这种情况下可以一点点的逼近局部最小值。

这样一种梯度下降算法,也叫做批量(Batch)梯度下降算法:每一次梯度下降时,都会使用到所有的训练数据。
线性回归的梯度下降
对于线性回归的梯度下降算法公式为:

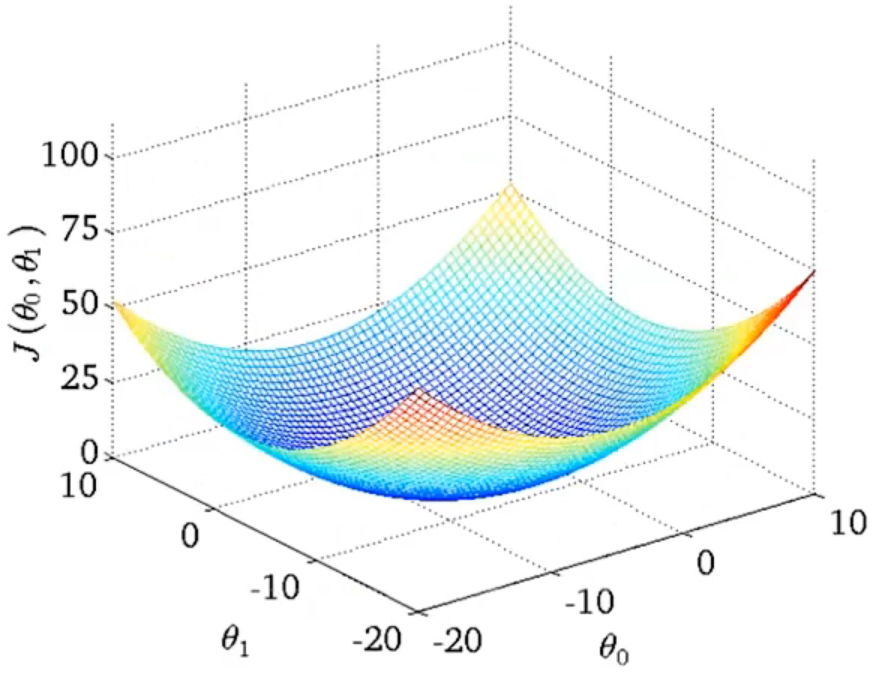
在线性回归问题中,代价函数J总是碗型的,所以不论选取的初始点在哪里都会到达全局最优(不会因为初始点的不同,到达不同的局部最优点)。
多元线性回归的梯度下降
多元线性回归的假设函数h(可以使用向量的乘法表示,规定x0=1)以及代价函数J如下:
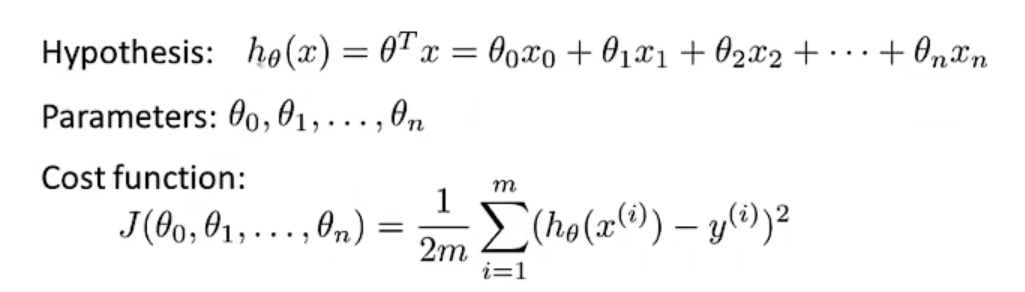
梯度下降:

代价函数J的偏导数展开得到:

常用技巧
特征缩放
确保各项特征在相似的范围内:
- 如果特征的范围相差巨大,会使等高线呈现出细长椭圆的形状,梯度下降速度慢
- 特征的范围相似(归一化处理),等高线此时更圆,梯度下降速度快
可以使用的方法:
- 特征值除以最大值(最大值-最小值),尽量使每个特征值的取值范围接近-1与1之间;
- 均值归一化,确保样本的均值接近0:

学习率
- 如果学习率过小:一定使得代价收敛于局部最小值,但是梯度下降速度缓慢
- 学习率过大:每一轮梯度下降后,代价函数可能不会减小,甚至不会收敛
正规方程
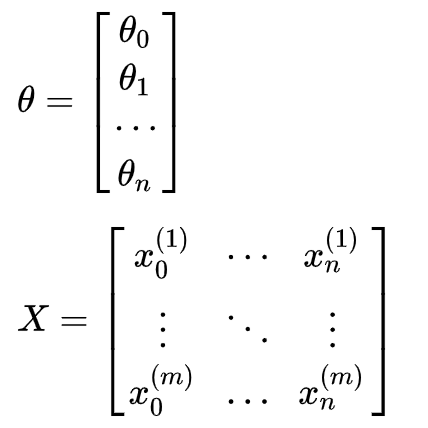
正规方程是一种与梯度下降不同的,无需迭代的求得参数θ的方法。训练集中共有m个样本,每个样本有n个连续型特征,和一个标签值y。对于训练集矩阵为X(规定x0=1)。
利用正规方程(Normal Equation)解出参数θ:
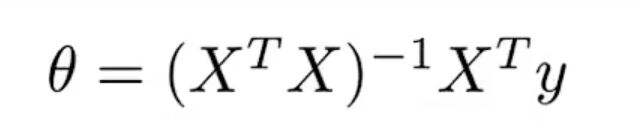
上述公式需要求矩阵的逆,那么如果矩阵不可逆怎么办?
- 查看是否有冗余的特征(特征之间产生了线性相关)
- 是否有过多的特征(如m < n):可以删除一些特征,或者规范化
正规方程 vs 梯度下降
训练集中共有m个样本,每个样本有n个连续型特征。
梯度下降:
- 需要选择学习率α
- 需要多次迭代
- 当n很大时,梯度下降也能有效工作
正规方程:
- 不需要选择学习率α
- 不需要多次迭代计算
- 需要计算矩阵相乘以及矩阵求逆(这个时间复杂度接近
O(n^3)),当n很大时,计算速度缓慢
总的来说,梯度下降算法适用于数据集特征很多、且算法复杂的场景中。