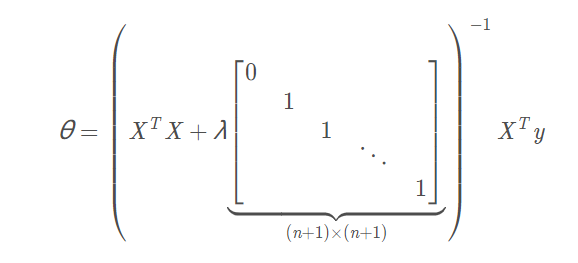欠拟合和过拟合
欠拟合
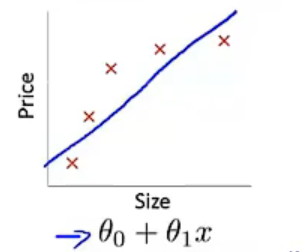
高偏差:对于样本集,没有很好的拟合训练数据。
过拟合
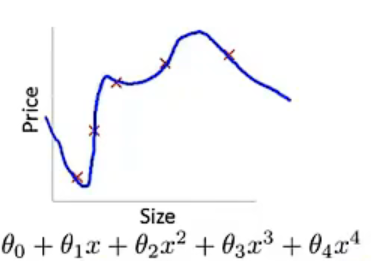
高方差:如果拟合训练数据过于完美,代价函数J≈0,但是不能很好的预测新的样本,不具备泛化能力。
解决方法:
减少特征的数量,但也同时丢失了关于问题的一些信息:
- 人工的选择保留一些合适的特征
- 模型选择算法
正则化:
- 保留所有的特征,减少参数θ的数量级或者大小
代价函数
可以对训练的参数加入惩罚项,要使得代价函数尽量小,那么就需要令预测出得参数小一点。使之在假设函数多项式中的系数(也就是预测的参数)尽量接近0,可以简化假设函数(如三次多项式中的三次系数非常接近0,可以将这个多项式看成是二次多项式),从而解决过拟合的问题。
线性回归的代价函数:
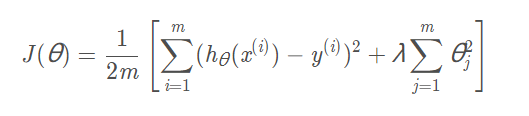
logistic回归的代价函数:
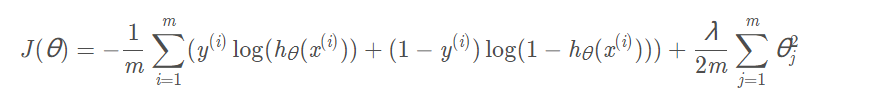
λ为正则化参数,用于平衡两个目标,即更好的去拟合数据集的目标,和将参数控制的更小的目标从而保证拟合函数尽量的简单,防止过拟合。如果λ被设置的太大,那么会导致欠拟合。
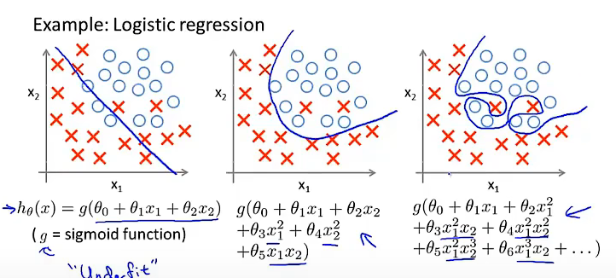
线性回归和逻辑回归的正则化
梯度下降
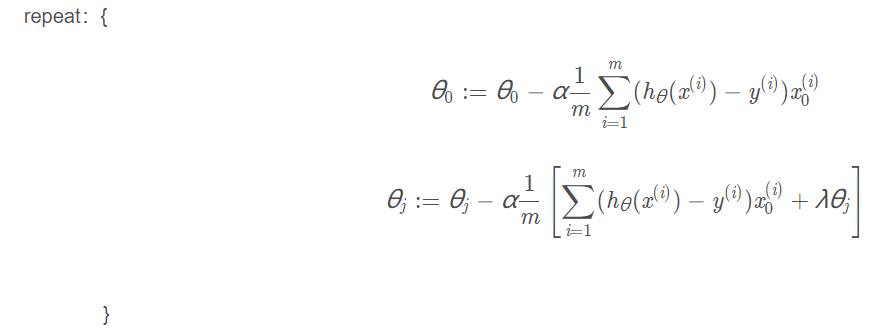
等价于:
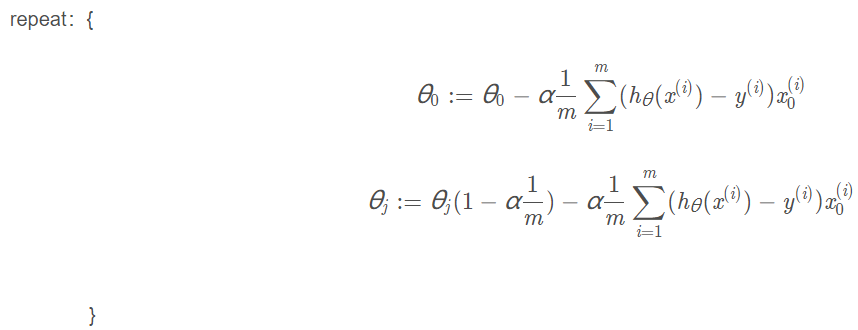
正规方程
只要λ>0,那么括号内的矩阵一定是可逆的,所以不用担心是否可逆的问题。