支持向量机
目标函数
以下是支持向量机SVM的目标函数,其形式于逻辑回归的形式类似,其中需要注意的是:
- 在SVM中,删除了在逻辑回归里第一项中的1/m。因为1/m仅仅是一个常量,因此,你在这个最小化问题中,无论前面是否有这一项,最终所得到的最优值θ都是一样的。
- 对于逻辑回归的目标函数中,有两项:第一个是训练样本的代价,第二个是我们的正则化项,其形式为A+λB。但是在SVM中,我们将使用一个不同的参数替换这里使用的λ来权衡这两项,其形式为CA+B。因此,在逻辑回归中,如果给定λ一个非常大的值,意味着给予B更大的权重。在SVM中,就对应于将C设定为非常小的值,那么,相应的将会给B比给A更大的权重。
- 在逻辑回归中,输出的是y=1的概率。而在SVM中,当θ^Tx大于等于0时,会输出1,否则输出0
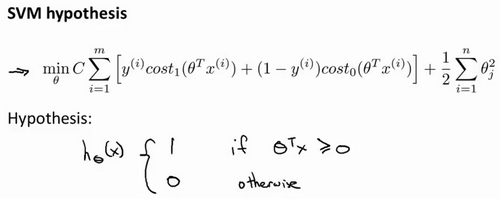
大间距的理解
人们有时将支持向量机看作是大间距分类器。下图为支持向量机的代价函数,为了最小化代价函数:
- 如果你有一个正样本,会希望θ^Tx>=1
- 反之,如果y=0,会希望θ^Tx<=-1
事实上,只需要θ^Tx>0,代价函数就接近0了,可以正确的区分样本。但是,支持向量机的要求更高,不仅仅要能正确分开输入的样本,需要的是比0值大很多,比如大于等于1;也想这个比0小很多,比如希望它小于等于-1。这就相当于在支持向量机中嵌入了一个额外的安全因子,或者说安全的间距因子。

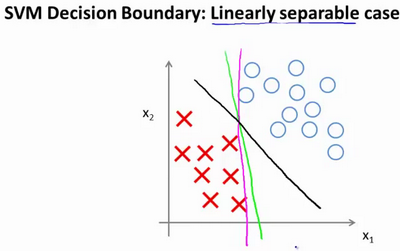
大间距分类器
如果将常数C设置为成一个非常大的值。则最小化代价函数的时候,我们将会很希望找到一个使第一项为0的最优解。因此,让我们尝试在代价项的第一项为0的情形下理解该优化问题。我们已经看到输入一个训练样本标签为y=1,想令第一项为0,需要做的是找到一个θ,使得θ^Tx>=1。类似的,若y=0,想让第一项为0,需要做的是找到一个θ,使得θ^Tx<=-1。当最小化这个关于变量θ的函数的时候,你会得到一个非常有趣的决策边界。
对于一个数据集,其中有正样本,也有负样本。存在很多条直线将正负样本分开。比如红色和绿色的直线就可以将正负样本分开,但是这些决策边界看起来都不是特别好的选择,支持向量机将会选择这个黑色的决策边界。在分离正样本和负样本上它显得的更好,这条黑线有更大的距离,这个距离叫做间距(margin)。支持向量机具有鲁棒性的原因,因为它努力用一个最大间距来分离样本。因此支持向量机有时被称为大间距分类器。
常数C的作用
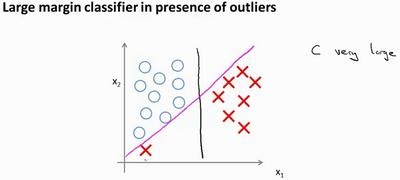
仅仅当常数C很大时,SVM表现为大间距分类器,但是学习算法会受异常点的影响。如下图所示,可能得到的决策边界是粉色的直线。
当C不是很大时,则你最终会得到这条黑线。并且它可以忽略掉一些异常点的影响,得到更好的决策界。
常数C的作用类似于1/λ:
- C较大时,相当于λ较小,可能会导致过拟合/高方差
- C较小时,相当于λ较大,可能会导致欠拟合/高偏差
核函数
选择新的特征
可以使用高级数的多项式模型来解决无法用直线进行分隔的分类问题。
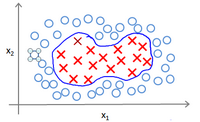
为了获得上图所示的判定边界,我们的模型可能是:
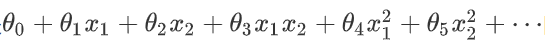
可以用新的特征f来替换模型中得每一项:
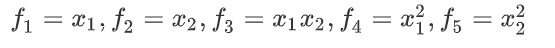
然而,除了对原有的特征进行组合以外,有没有更好的方法来构造f?可以用核函数来计算新的特征。给定一个训练样本x,可以利用x得各个特征与预先选定的地标l(landmarks)的近似程度来选择新的特征f。如
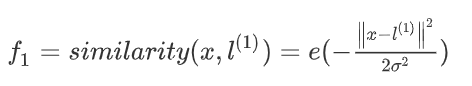
similarity函数就是核函数,具体而言,这里是一个高斯核函数。
地标(landmarks)的作用
- 如果一个训练样本x与地标l之间的距离近似于0,那么特征f近似于1
- 如果x与地标l之间的距离非常远,f近似于0

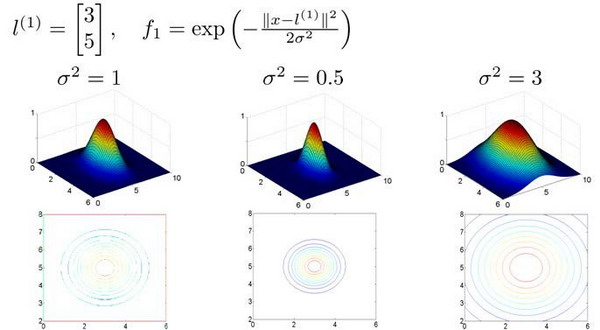
假设训练样本有两个特征x1和x2,给定l与不同的σ:
- 当x与地标l接近时,特征f的数值很大
- 而σ与f的下降速度有关,当σ较大时,尽管x与地标l有一定的距离,但是不会快速下降至0
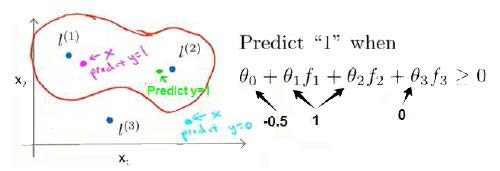
在下图中,当样本处于洋红色的点位置处,因为其离l(1)更近,但是距离l(2)和l(3)很远,因此f1接近于1,而f2和f3接近于0,因此h(x) >0,因此预测y=1。同理可以得到,距离l(2)很近的绿色的点,预测y=1。但是对于蓝色的点,因为其距离l(1)与l(2)距离都很远(因为θ3=0,所以与l(3)的距离无关),预测y=0。
这样,图中红色的封闭曲线所表示的范围就是判定边界的范围,这条曲线的范围之内预测y=0。在预测时,我们采用的特征不是训练样本本身的特征,而是通过核函数计算出的新特征f。
细节
以下是实现SVM的一些细节。
如何选取地标?
我们通常是根据训练集的数量选择地标的数量,即如果训练集中有m个样本,就选择m个地标,并且地标的位置与样本的位置重合。
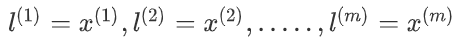
这样做的好处在于:现在我们得到的新特征是建立在原有特征与训练集中所有其他特征之间距离的基础之上的。
正则化项的调整:
前面定义的目标函数为:
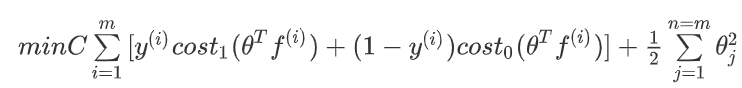
但是在具体实施过程中,我们还需要对最后的正则化项进行些微调整,在计算正则化θ^2=θ^Tθ项时,用θ^TMθ来代替θ^Tθ,其中M是根据我们选择的核函数而不同的一个矩阵,这样做的原因是为了简化计算。
理论上讲,我们也可以在逻辑回归中使用核函数,但是上面使用M简化计算的方法不适用与逻辑回归,因此计算将非常耗费时间。
核函数的选择?
可以使用高斯核函数,需要选择一个参数σ,当特征数量很小,而样本数量很大时可以使用。
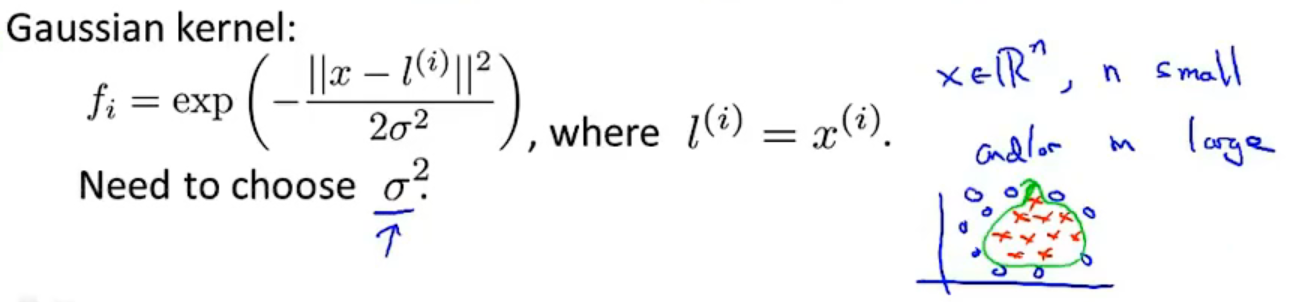
支持向量机也可以不使用核函数,不使用核函数又称为线性核函数(linear kernel),当我们不采用非常复杂的函数,或者我们的训练集特征非常多而样本非常少的时候,可以采用这种不带核函数的支持向量机。
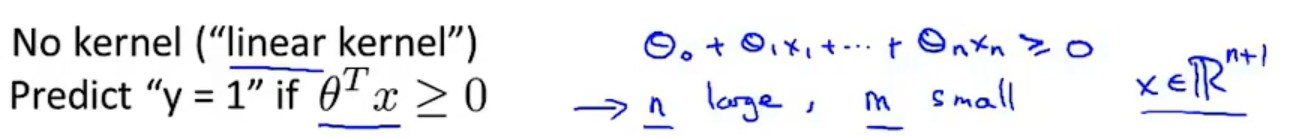
C(相当于1/λ)与σ的影响:
- C较大时,相当于λ较小,可能会导致过拟合/高方差
- C较小时,相当于λ较大,可能会导致欠拟合/高偏差
- σ较大时,可能会导致低方差,高偏差
- σ较小时,可能会导致低偏差,高方差
SVM vs 逻辑回归
- 当特征数量>样本数量时,选择逻辑回归或者不带核函数(线性核函数)的SVM
- 当特征数量很小,样本数量适中时,选择带有高斯核函数的SVM
- 当特征数量很小,样本数量很大时,添加更多的特征,然后选择逻辑回归或者或者不带核函数(线性核函数)的SVM

对于神经网络而言,可能适合大多数情况,但是训练速度很慢。