本节实现了一致性哈希,最终代码结构如下:
1 | lru/ |
一致性哈希
为什么使用一致性哈希
使用一致性哈希的原因如下:
- 对于分布式缓存来说,若一个节点收到请求但是该节点没有对应的缓存数据。那么应该从谁那里获取数据?假设一共有 10 个节点,随机获取数据。假设第一次从节点 1 处获取数据,那么第二次只有十分之一的概率再次从节点 1 处获取数据。因为每一次可能都会从一个新的节点获取数据源,这样的操作不仅耗费时间(新的节点可能本身没有数据,需要从其他节点或者调用回调获取数据源),而且浪费空间(数据会冗余存储)。
- 当某一个节点失效(节点增加也是同理)了,若使用简单的取余操作来选择节点,比如之前的
hash(key)%10变成了hash(key)%10,会使几乎所有缓存对应的节点都发生了改变。即所有缓存值都失效了,造成缓存雪崩:缓存在同一时刻全部失效,造成瞬时DB请求量大、压力骤增,引起雪崩。
原理
一致性哈希算法将 key 映射到 2^32 的空间中,将这个数字首尾相连,形成一个环。
- 计算机节点的哈希,放置在哈希环上。
- 计算 key 的哈希值,放置在环上顺时针寻找到的第一个节点就是对应的计算机节点。
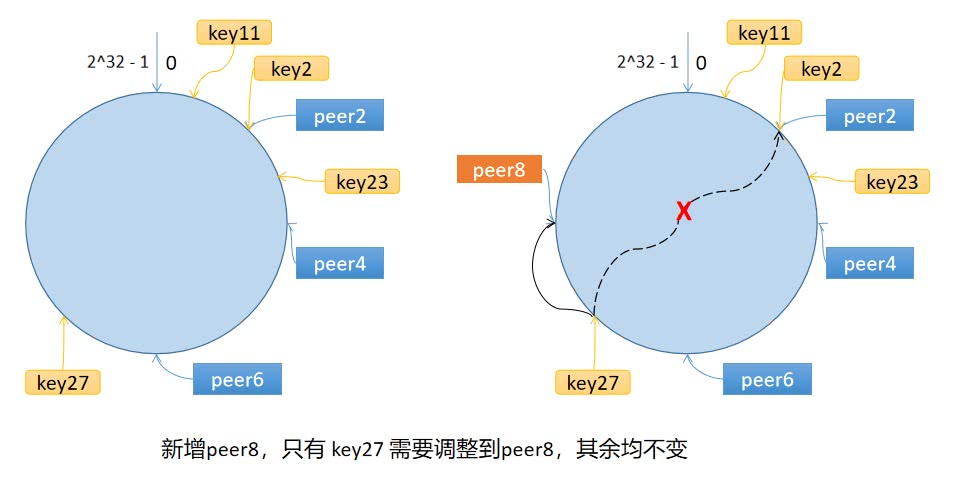
下图左图中,key27、key11、key2 对应于节点 peer2;key23 对应于节点 peer4。
下图右图中,新增节点 peer8,但是只有 key27 对应的节点从 peer2 变成了 peer8,其余均不变。
数据倾斜
当节点数目较少时,容易出现数据倾斜问题。就是 key 的映射关系不均匀,可能很多的 key 映射到了 peer1,只有很少甚至没有 key 映射到 peer2。
为了解决这个问题,引入虚拟节点的概念,一个真实节点对应多个虚拟节点。
虚拟节点与真实节点一样,将哈希值防止在哈希环上。计算 key 的哈希值,放置在环上顺时针寻找到的第一个(虚拟)节点就是对应的节点。
实现一致性哈希
consistenthash.go
一致性哈希主体结构
首先定义一致性哈希的主体结构体 Map:
- hash 表示使用的哈希函数。
- replicas 表示一个节点加上其虚拟节点的数量。
- keys 表示哈希环,有序存储所有的节点。
- hashMap 存储所有节点与真实节点映射关系。
1 | type Hash func(data []byte) uint32 |
添加真实机器
添加真实机器的方法 Add,一次允许添加多个真实机器。每一个机器对应 m.replicas 个虚拟节点:
1 | func (m *Map) Add(keys ...string) { |
获取 key 对应的机器
获取 key 对应的机器 Get 函数:
- 首先计算 key 的哈希。
- 再顺时针找到最近的虚拟节点。
- 查询虚拟节点对应的真实机器。
1 | func (m *Map) Get(key string) string { |