BERT 介绍
我们将一些不带标注的文章,先预训练,得到一个 Model,这个 Model 可以看作是能够理解文字内容。
接着用一些带标注的特殊语料,进行 Fine-tune(微调),训练出可以完成特殊任务的 Model。
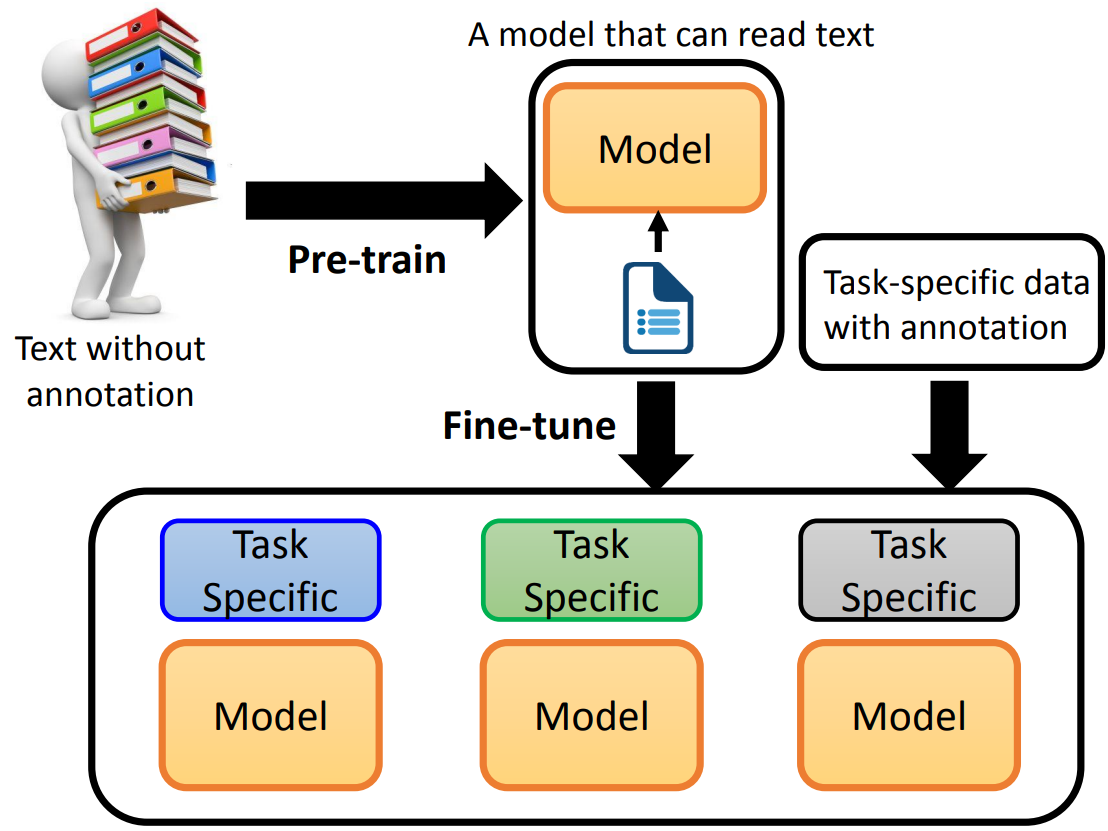
什么是预训练
早期预训练模型
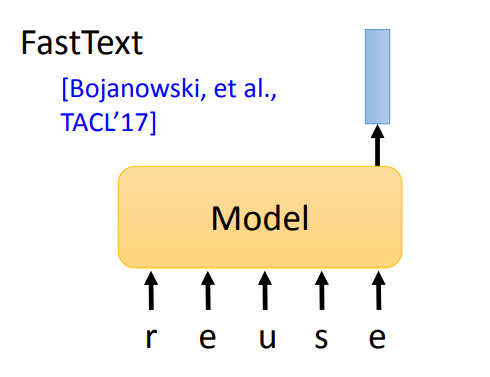
- 早期的预训练模型,可以看作是输入 token(一个英文字母为一个 token),输出为每一个 token 对应的词嵌入。如 Word2vec、Glove。
- 或者输入一个英文单词的各个字母,输出一个词嵌入,这种情况下可以识别新词。如 FastText。
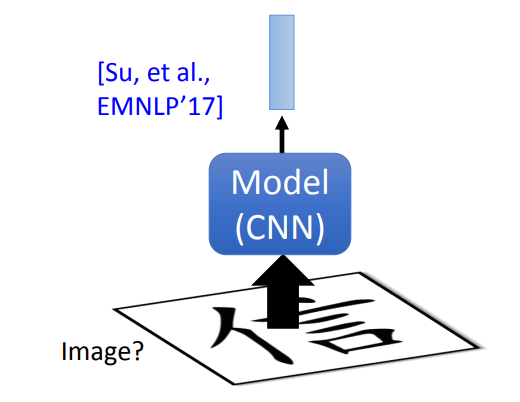
- 类似的对于中文,可以输入中文图片到 CNN 中,可以期待 CNN 学会中文的偏旁部首信息。
这种预训练模型的一个缺点就是,不考虑上下文。对于相同的 token,一定输出相同的词嵌入,尽管相同的 token 在不同的上下文中的含义可能有所不同。
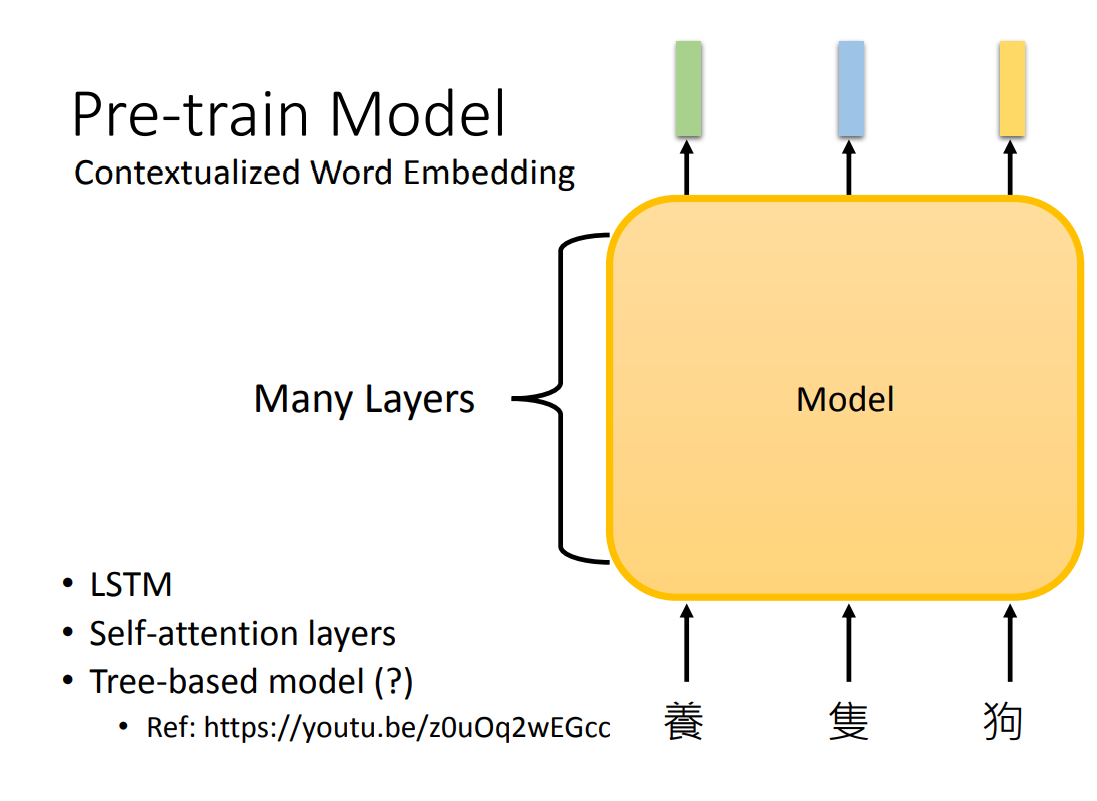
Contextualized 词嵌入
可以训练考虑上下文的词嵌入,输入整个句子到一个深层网络中,输出为每一个 token 的词嵌入。网络架构可以是:
- LSTM
- 自注意力层
- Tree-based 模型(文法结构很清楚时可用)
如何微调(fine-tune)
NLP 任务分类
根据输入:
- 一个句子
- 多个句子:句子之间用
SEP分隔符分隔。
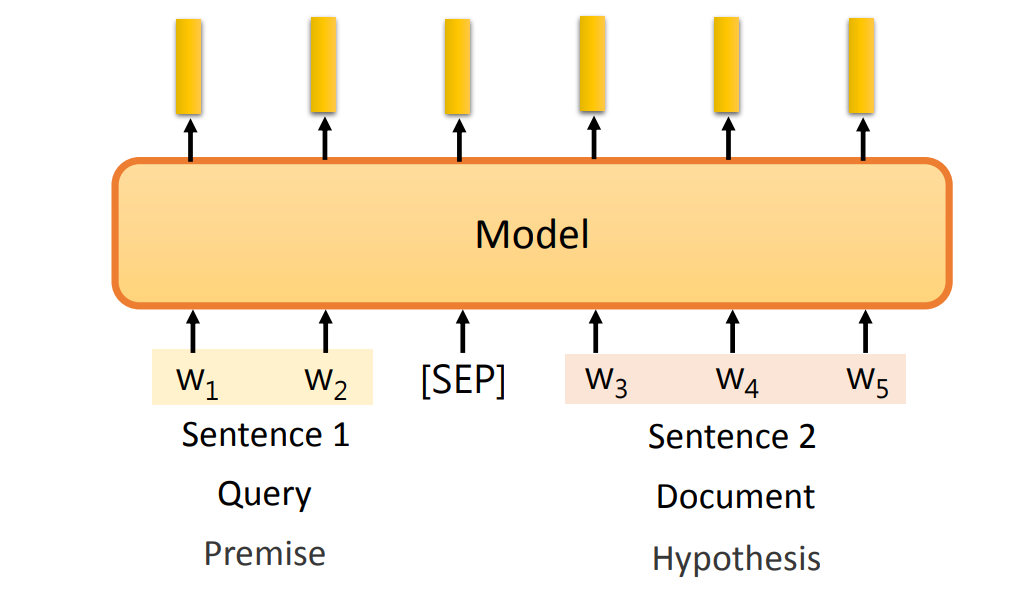
根据输出:
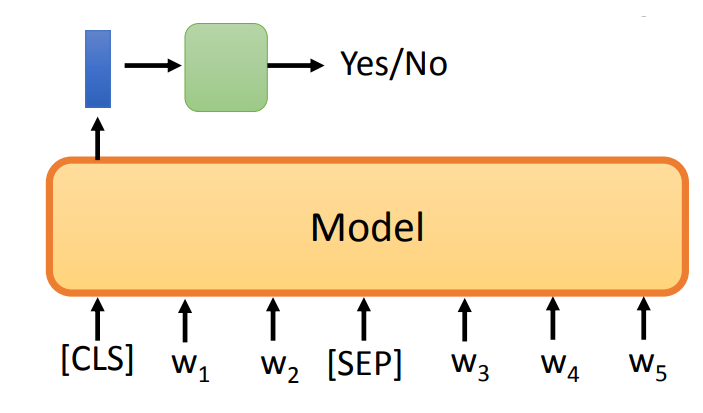
- 输出一个类别 class:
- 输入时,第一个 token 为
CLS作为标记,表示输出与整个句子有关的词嵌入。 可以将与整个句子有关的词嵌入,放入另一个模型中。 - 或者可以可以没有
CLS,将预训练模型的所有输出作为另一个模型的输入,这个模型只输出一个类别。
- 输入时,第一个 token 为
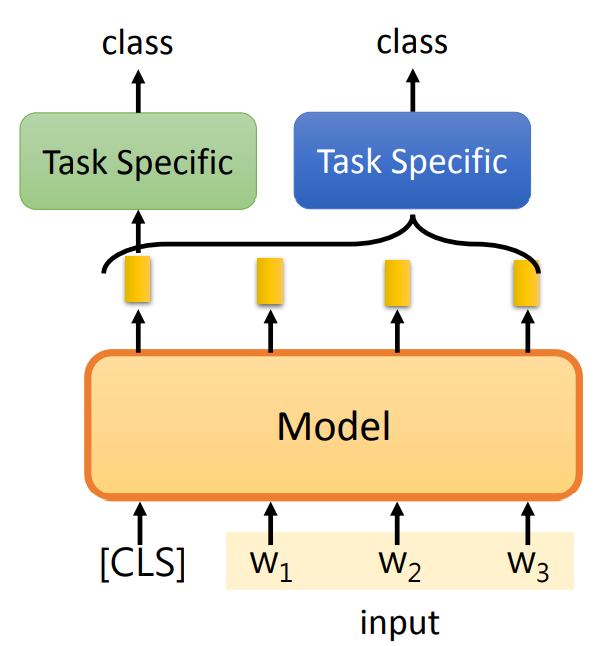
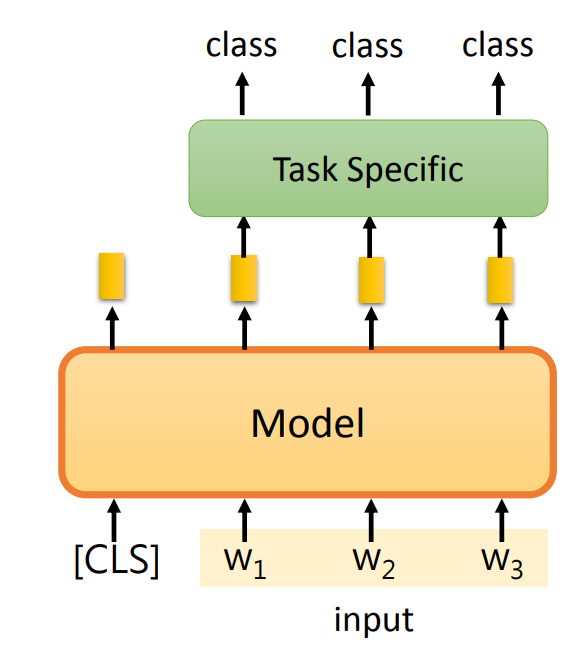
- 每一个 token 都输出一个类别 class:第一个输入为
CLS,将每一个输出作为另一个模型的输入,这个模型为每一个输入都生成一个类别。
- 复制输入的某部分作为输出:输出开始位置、结束位置。
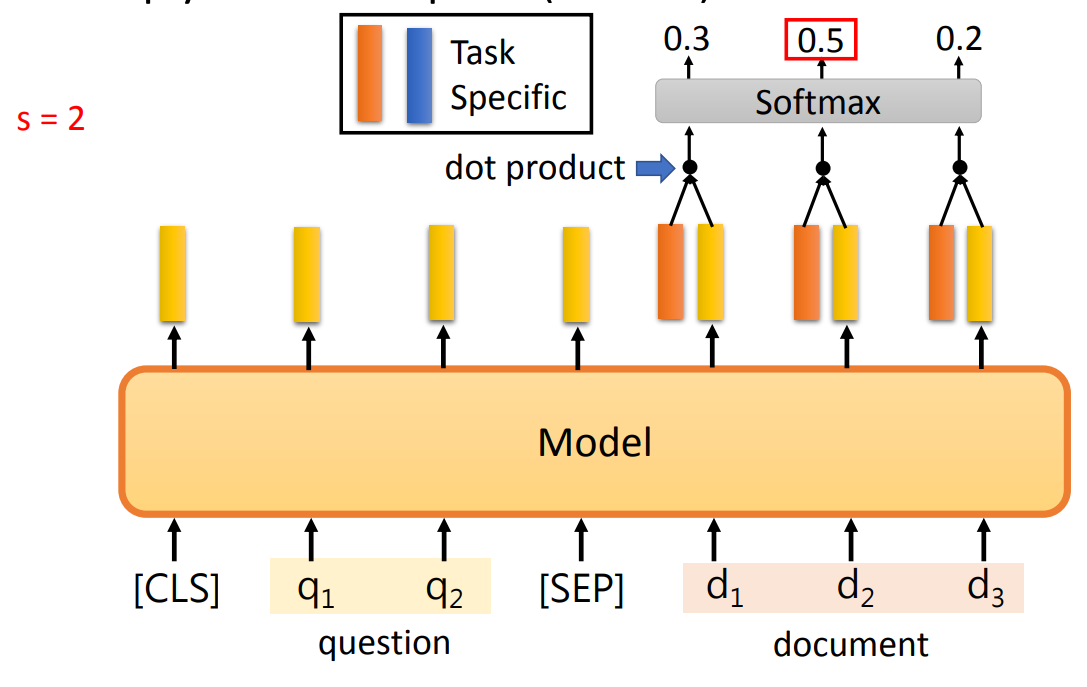
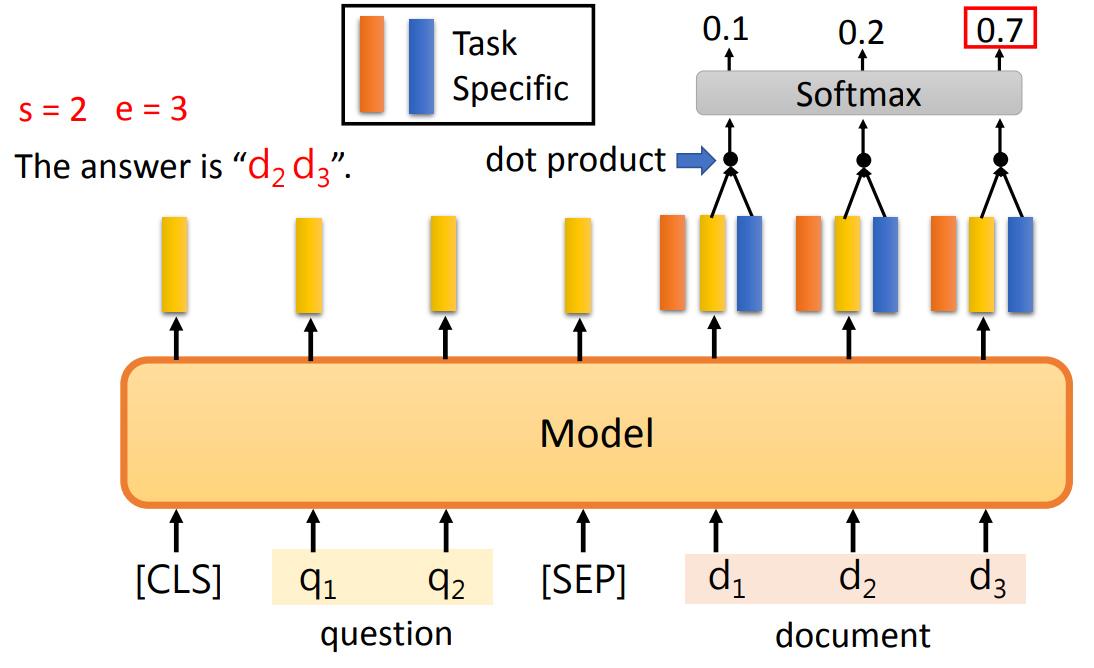
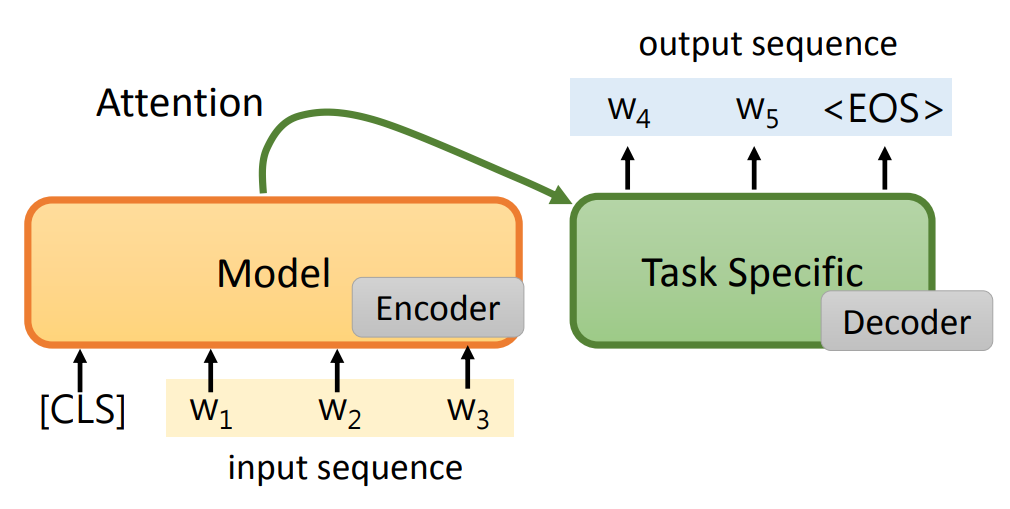
生成一个句子:
- 预训练模型作为 Encoder,再经过 Attention、Decoder 生成一个句子。
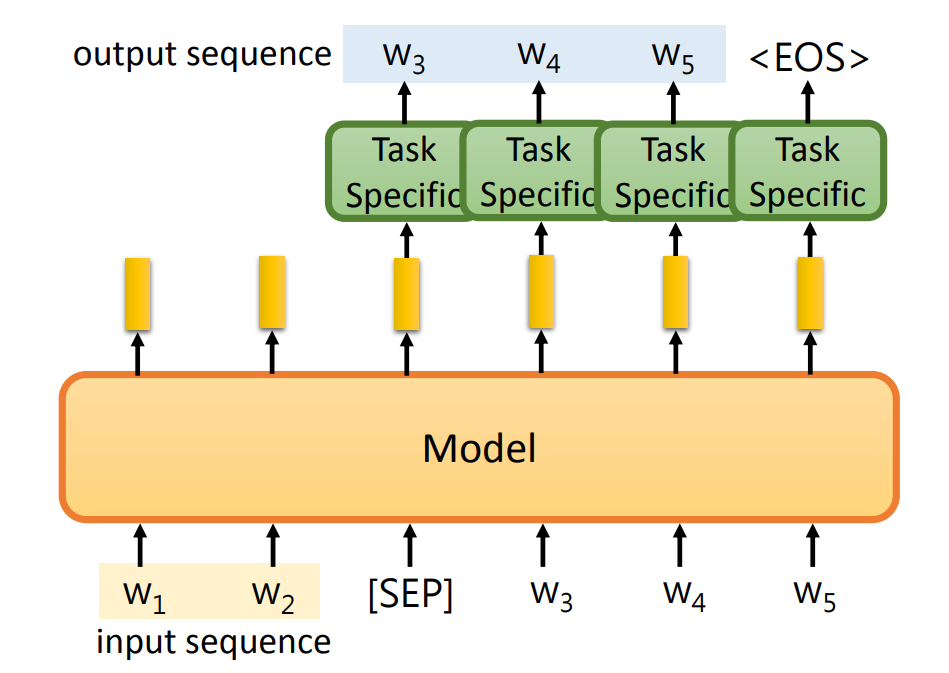
- 将输入的最后一个字符
SEP在 Task Specific Model 中所对应生成的 token 作为新的输出。
- 输出一个类别 class:
微调 fine-tune 的方法
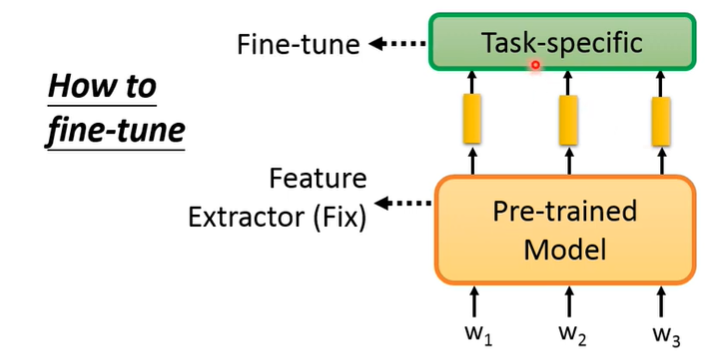
- 方案一:在微调时,将预训练模型的参数固定,只训练 Task Specific Model 的参数。
- 方案二:同时训练预训练模型和 Task Specific Model 的参数。(效果更好)
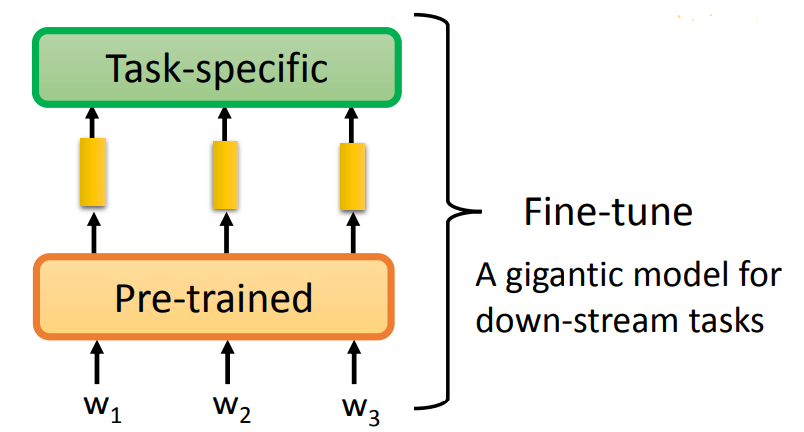
方案二 同时训练预训练模型和 Task Specific Medel 的参数的问题:每一次微调都会产生一个完全新的模型。
解决方法:Adapter,在预训练模型中加入一些 Layer,称为 Adapter。在微调时,只训练预训练模型中 Adapter 的参数。
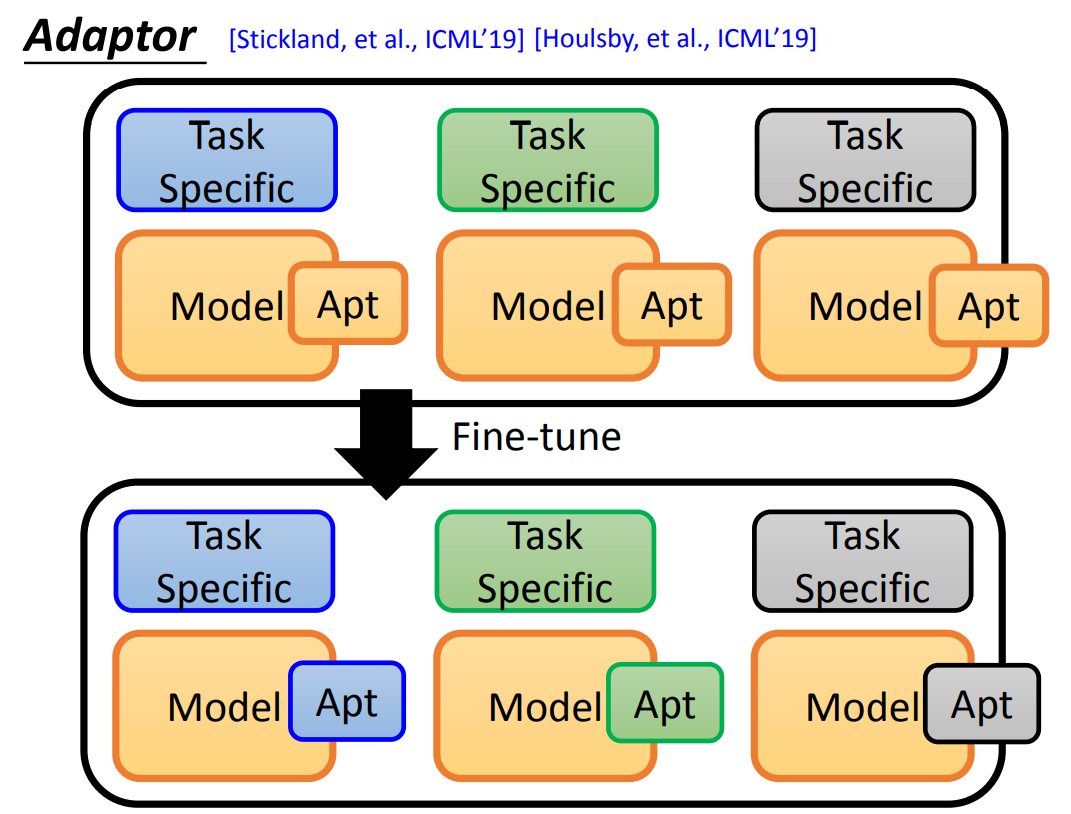
Weighted Features
在上文中,只是将预训练模型中最后一层的输出作为 Task Specific Model 的输入。
其实,在预训练模型中,每一层的信息可能是不一样的,所有可以将每一层的输出加权(权重可以训练或者固定)合并起来作为 Task Specific Model 的输入。
如何预训练
可以将翻译作为预训练模型的任务,其中 Encoder 就是预训练模型。因为翻译需要尽可能的表示一句话中每一个单词的意思,所以 Encoder 生产的词嵌入可能会准确的表示每一个输入的意思。
但是这样有一个问题,就是所有的训练数据都需要是有标注的。
解决思路:自监督学习,通过无标注的数据自动生成输入和标签:
- 预测下一个 token
- Masking Input(BERT的做法)
- XLNet
- MASS / BART
- UniLM
- Replace or Not
- Sentence Level
预测下一个 token(语言模型 LM)
可以通过预测下一个 token 来进行预训练,需要注意的是:不能将一句话的所有 token 都同时输入,这样预训练模型可能会学习到,每一个 token 预测的输出为输入的下一个 token。
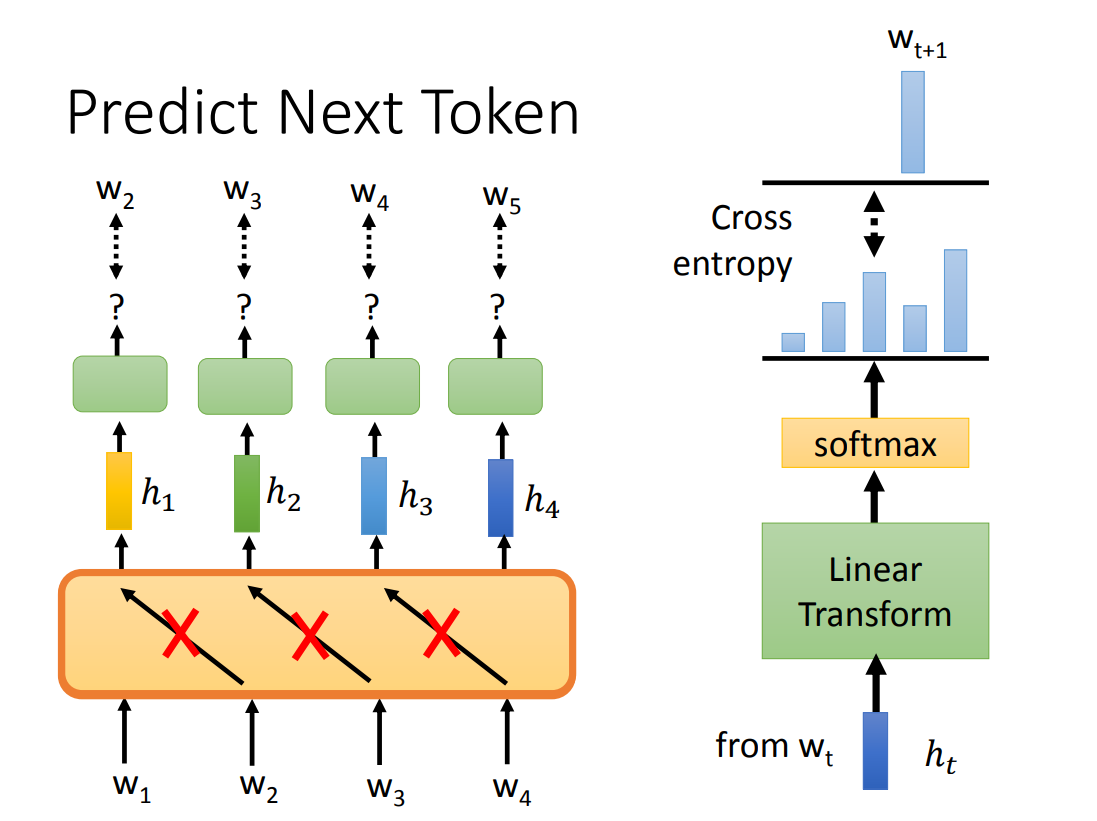
网络模型可以使用:
- LSTM:ELMo、ULMFiT
- Self-Attention:GPT、GPT-2
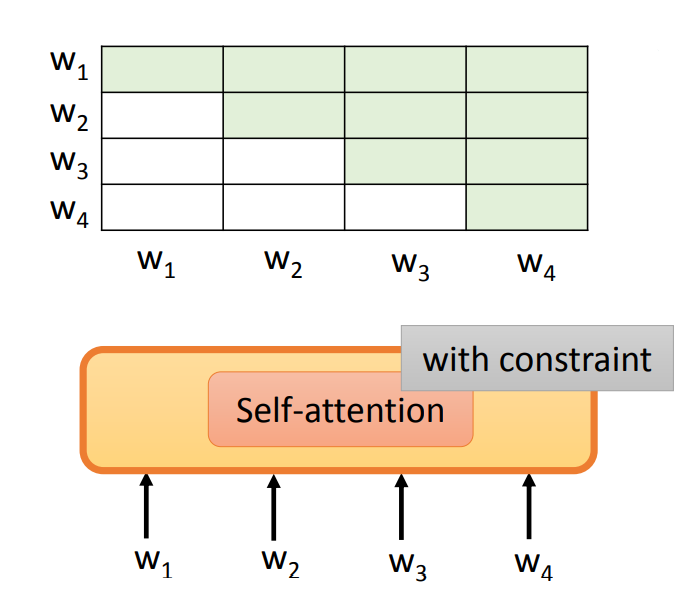
需要注意的是,当使用 Self-Attention 时,是有限制(with constraint)的 Attention,即每一次只能 Attention 到之前的输入。
ELMo 使用了双向的 LSTM,即从前向后、从后向前两个方向的结果拼接起来,得到词嵌入。
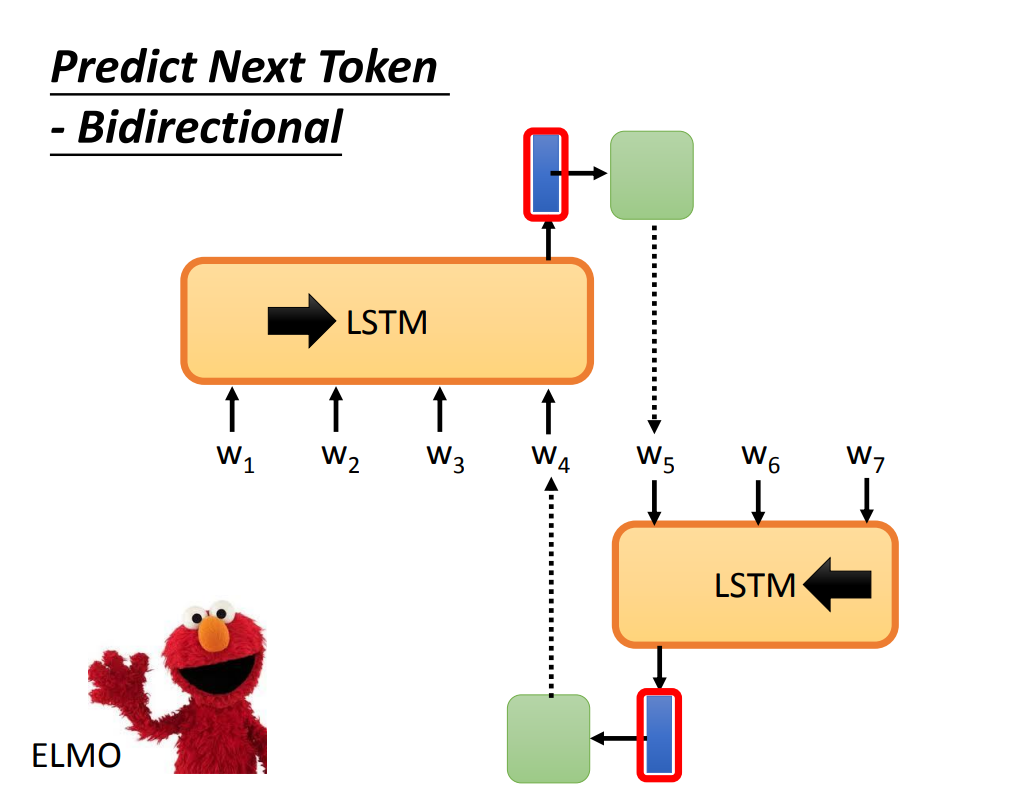
即使是双向的LSTM,依然有一个问题:
正向 LSTM 没有考虑到后面的单词,反向 LSTM 没有考虑到前面的单词。由此引入 Masking Input 的方法。
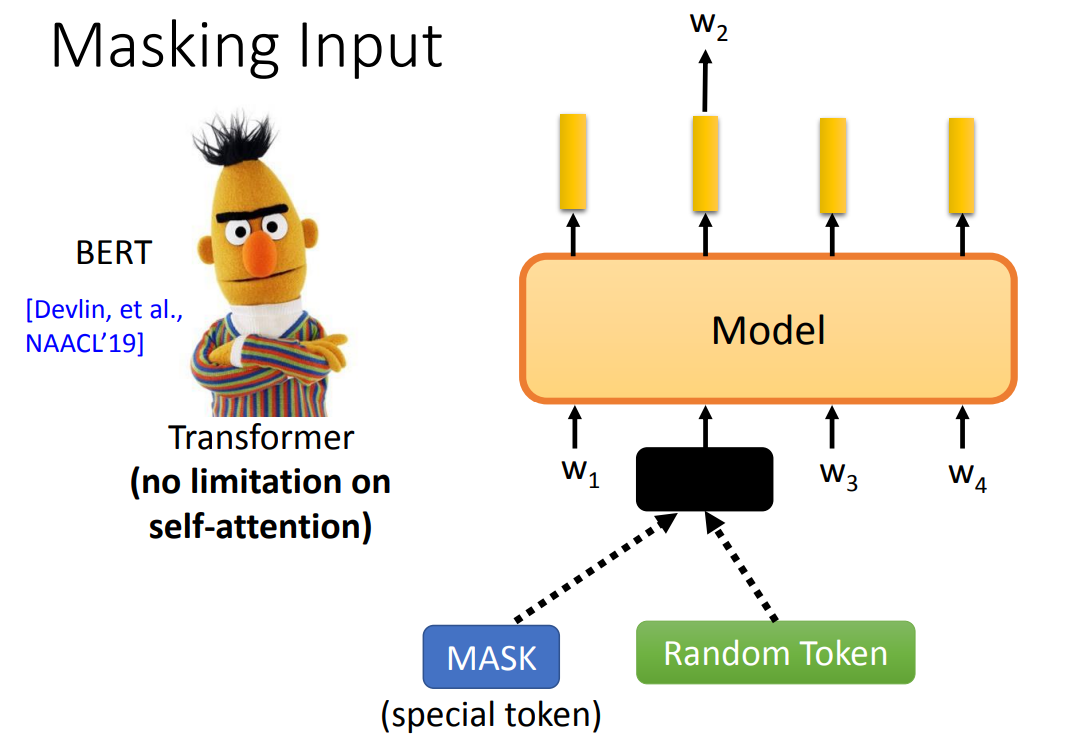
Masking Input
Masking Input 就是“盖住”一部分输入,预测被盖住的 token。
盖住:可以用一个特殊的 token 替换;也可以替换为一个随机的 token。
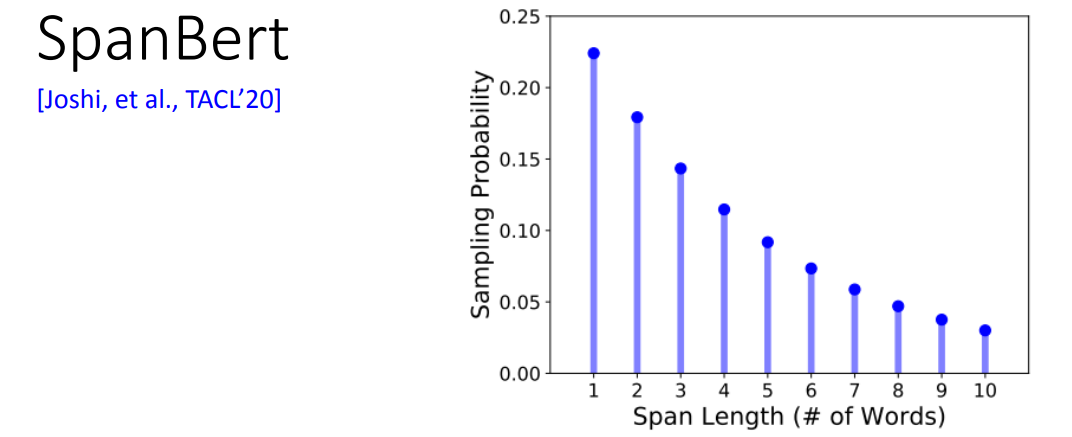
Masking 的长度:
- **Whole Word Masking (WWM)**:不仅仅盖住一个 token,而是盖住整个单词/词语(一个单词/词语可能由多个 token 组成)
- Phrase-level & Entity-level:盖住短语,或者是一个实体。
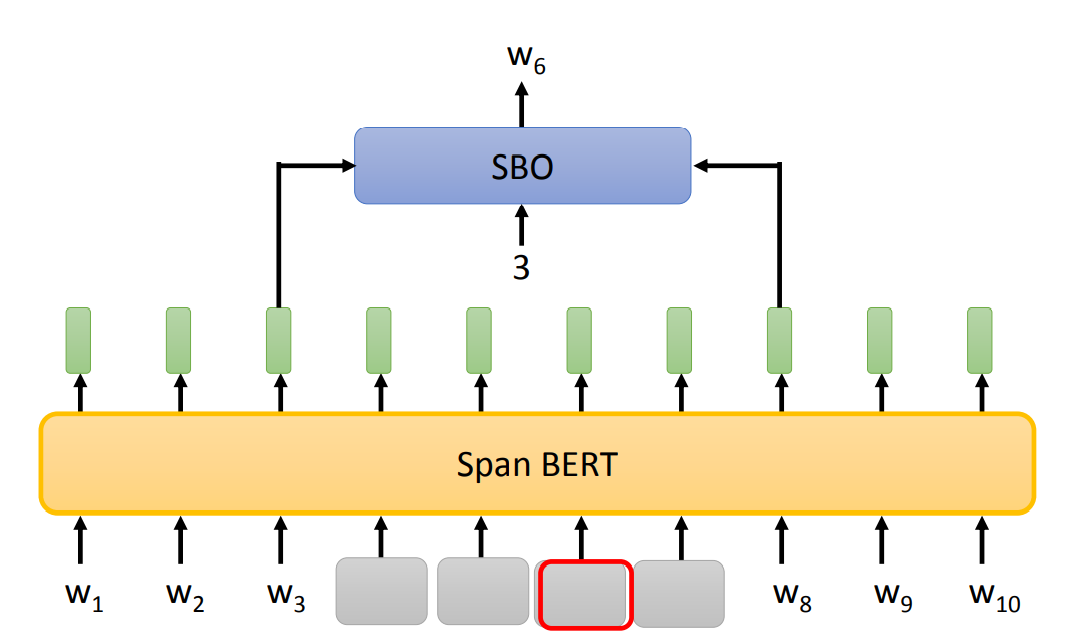
- SpanBert:随意的盖住一段范围内的 token,长度随机,长度越长,概率越小。
SpanBert 提出了 Span Boundary Objective(SBO),是一个小型的 Model,根据 Masking 部分的前一个和后一个词嵌入预测 Masking 的第 x 个 token。
SBO 期待一个 span 左右两边的 embeding 包含整个 span 的信息。
XLNet
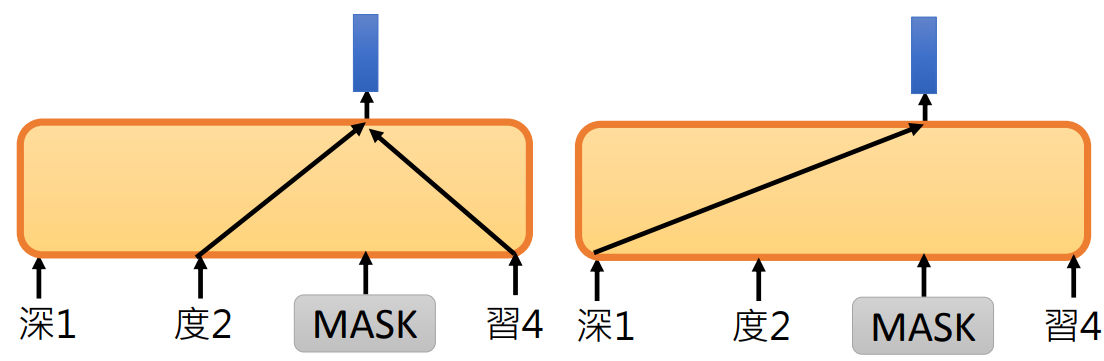
XLNet,即 Transformer-XL,它不想 BERT 输入 Masking 周围的所有 token,而是根据任意的 token(token的顺序也会被打乱),来预测 Masking 的 token。
这样做的目的是:可以更好的挖掘 token 之间的联系信息。
MASS / BART
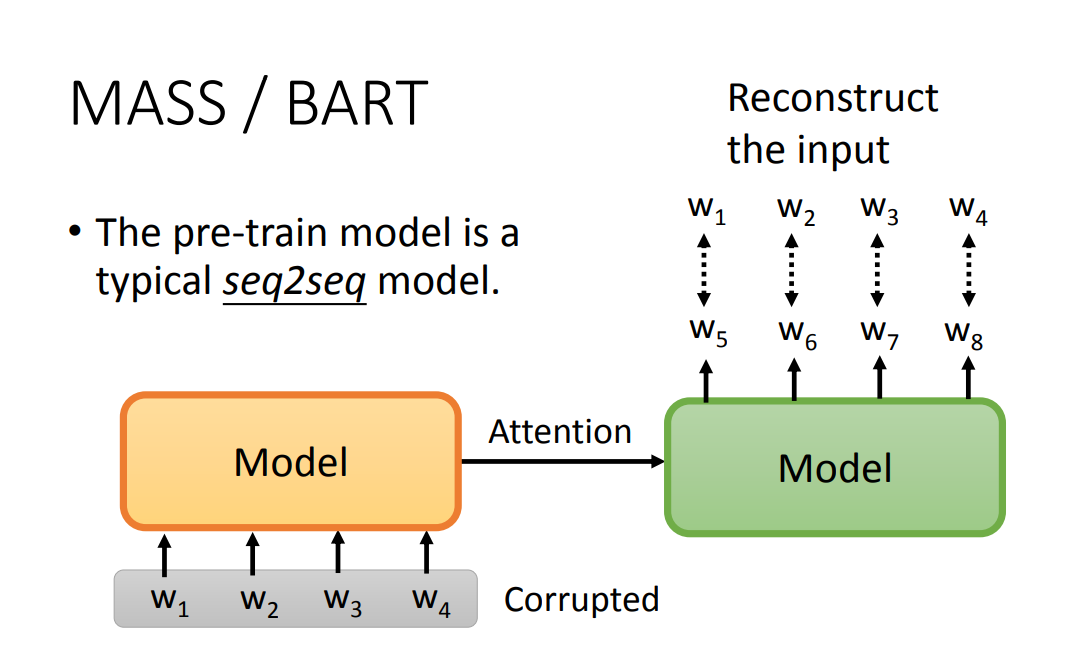
在 autoregressive model(从左到右依次生成句子) 中,BERT ”不善言辞“,不善于去做生成句子的任务,因为 BERT 会”看到“ Masking 前后的 token。
MASS / BART 提出了解决方案,即通过输入被破坏(corrupted)的 token,输出是原来正确的句子,来训练一个 seq2seq 模型。
关于如何 Corrupted,有如下方案:
- MASS:遮盖住一个 token
- Delete:删除一个 token
- Permutation:打乱句子间的顺序
- Rotation:对所有句子进行循环移位
- Text Infilling:随机插入 MASK、随机遮盖多个 token
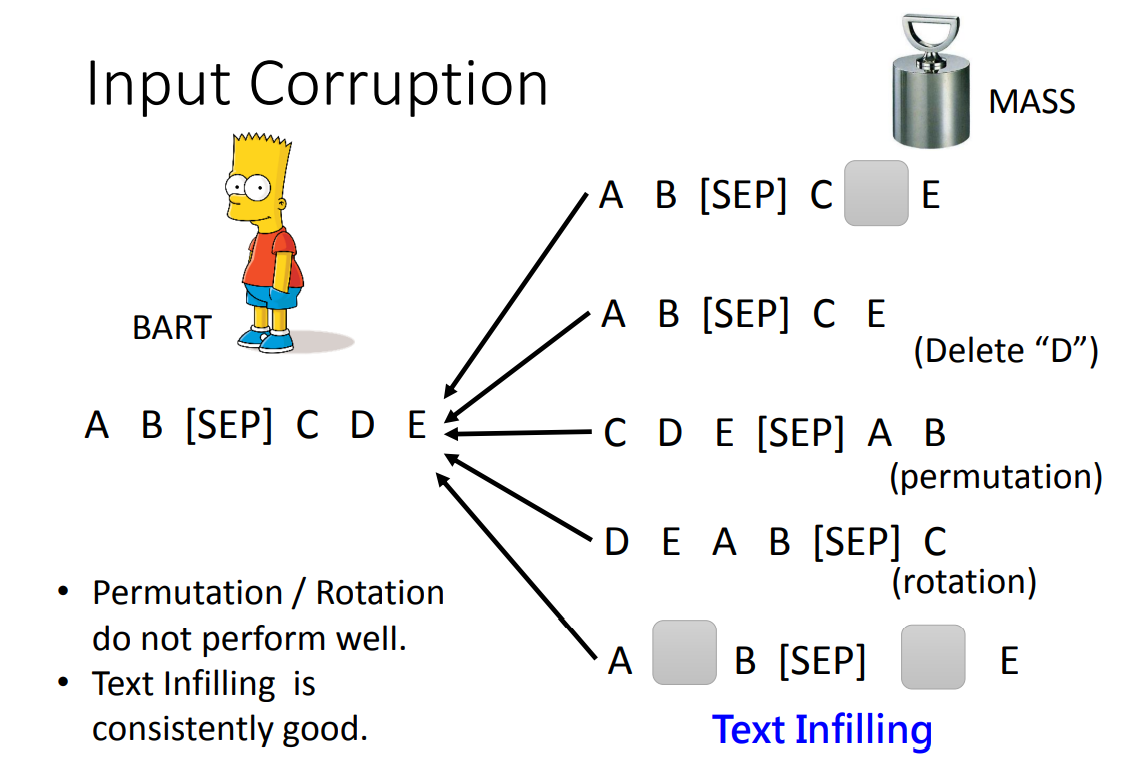
最终 BART 得到结论:
Permutation 和 Rotation 效果不好,Text Infilling 效果最好。
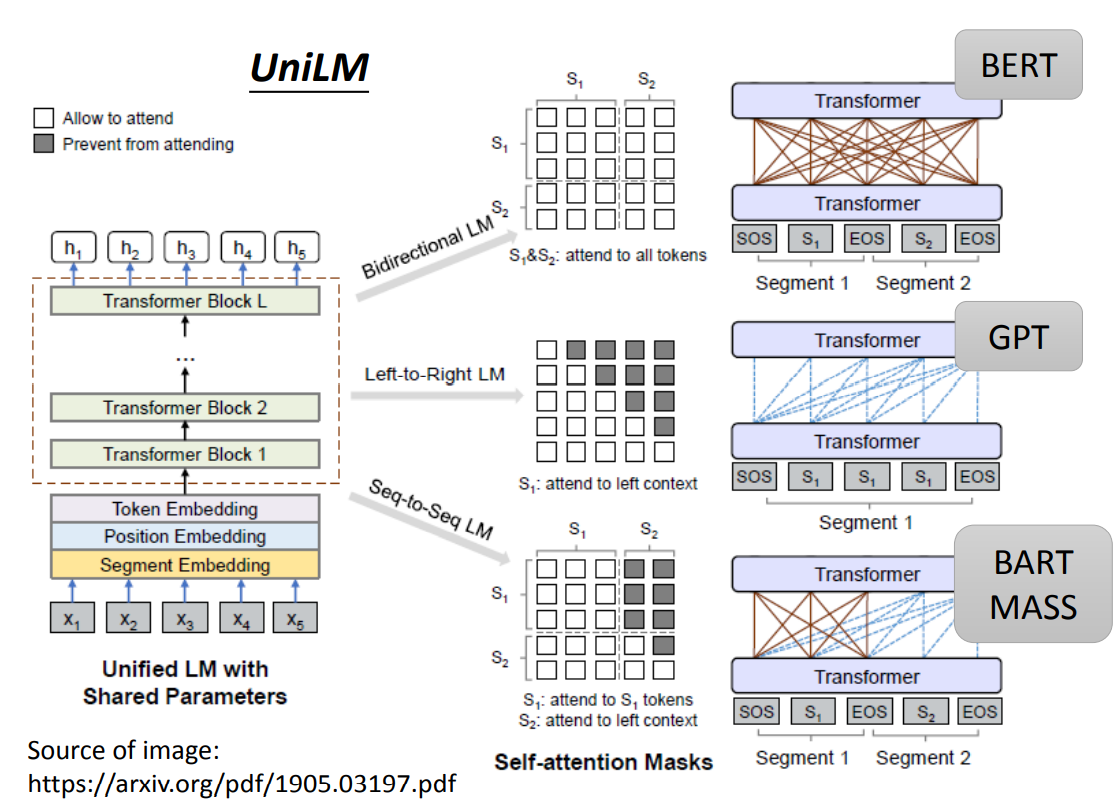
UniLM
UniLM 提出了一个方案,可以使得同一个 Model,同时是 Encoder、Decoder 和 Seq2seq。
- 当作为 Encoder 时,就是一个 BERT,会注意到所有的 token。
- 当作为 Decoder 时,就是一个 GPT,只会注意之前的 token。
- 当作为 Seq2seq 时,将 Model 分为两个部分,前一个部分是全连接会注意到第一部分所有的 token,后一个部分 只会注意到之前的 token。
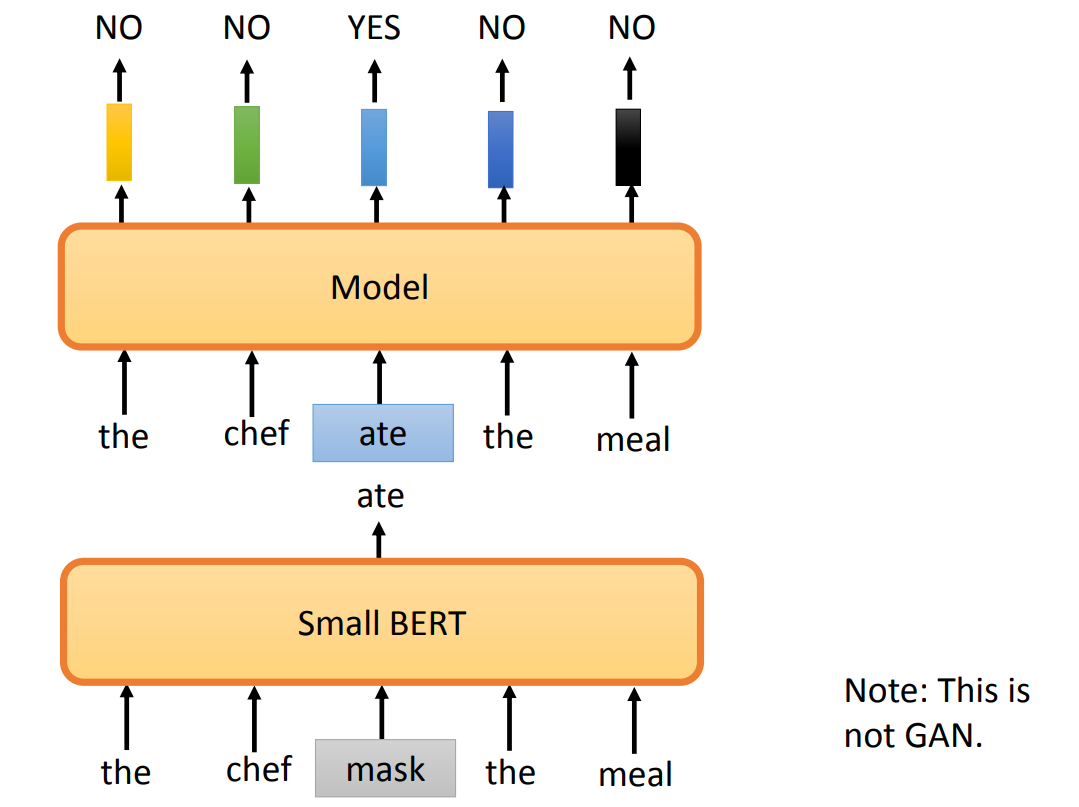
Replace or Not
Efficiently Learning an Encoder that Classifies Token Replacements Accurately(ELECTRA)提出了一个新的预训练方法:判断输入中是否有 token 被替换。
可以用一个 BERT 去生成一个被替换的 token。
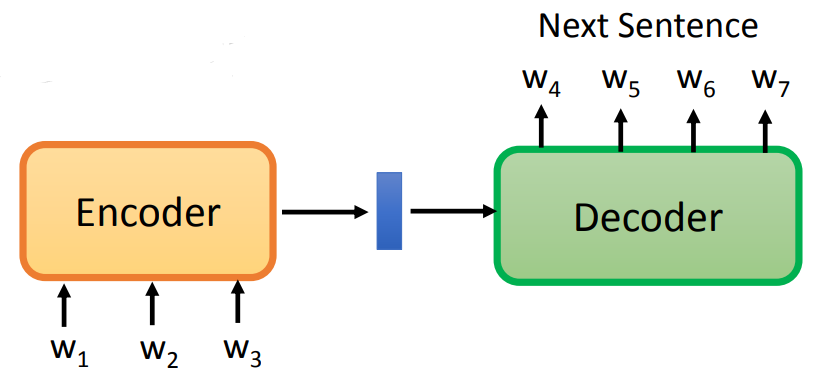
Sentence Level
对于生成一整个句子的 embeding,有如下方法:
- Skip Thought:Encoder 生成一个句子的 embeding,再放入 Decoder,生成下一个句子。对于 Decoder 生成两个相同句子 的输入,使他们的 embeding 越接近越好。
- Quick Thought:对于两个相邻的句子,使他们的 embeding 越接近越好。
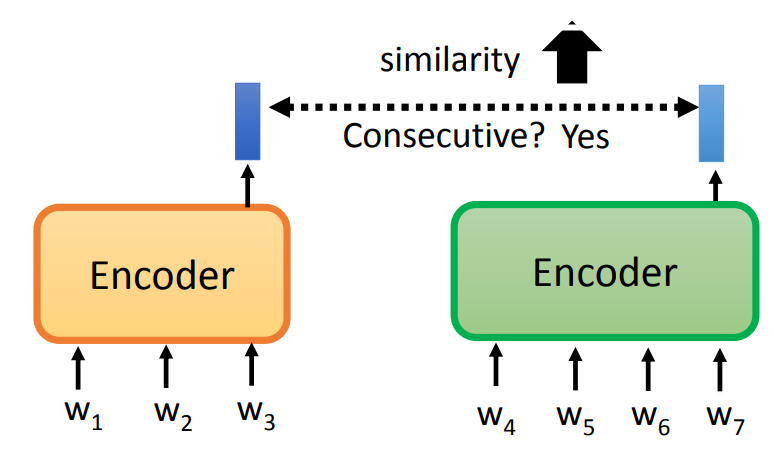
- 在 BETRT 中,就是对于整个句子的 embeding,放入一个二分类器中,使之输出 yes/no。可以分为两种任务:
- NSP(Next Sentence Prediction):输入两个句子,若第二个句子可以接在第一个句子后,则输出 yes。
- SOP(Sentence Order Prediction):输入多个句子,若这些句子顺序正确,则输出 yes。
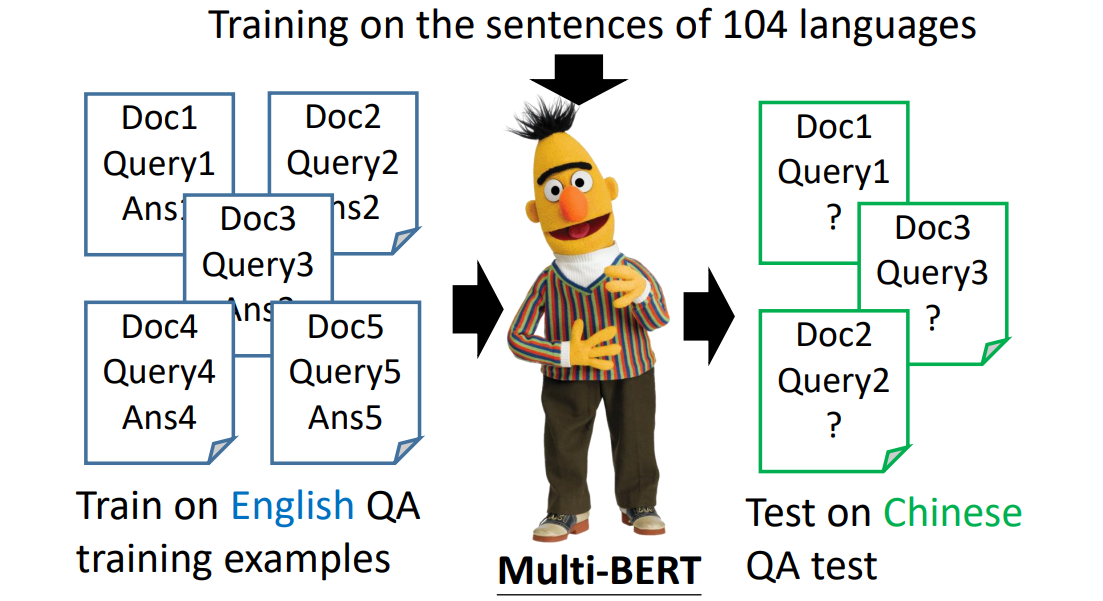
Multi-lingual BERT
多语言 BERT 模型,可以将各种语言都放入 model 中训练。
跨语言学习:可以拿多种语言进行预训练,再用中文或者英文的训练资料进行 fine-tune,微调后的 model 可以运行在中文语言上。(训练在一个语言上,测试在另一个语言上)
这样的多语言模型,可以进行跨语言学习,实际上生成的 embedding 中是含有语言信息的:
在 Multi-BERT 中,训练时是输入什么语言,输出什么语言的,不会混在一起。所以在 Multi-BERT 生成的 embedding 中,一定是含有语言信息的。