Coreference Resolution
Coreference Resolution,即代指消解,识别出代指的相同的东西。
需要识别出代指的一段文字(如他、它的 XX 等),称为 mention。代指消解的结果就是将同一个代指的 mention,放入同一个 cluster 中。
步骤
- 识别出 mention:需要一个二分类器,输入一个 span,判别是否是一个 mention。若有 N 个 token 的句子,需要运行
N(N-1)/2次。

- 识别哪些 mention 需要放在同一个 cluster 中:同样需要一个二分类器,输入为两个 mention,输出判断是否属于同一个 cluster。若有 K 个 mention,需要运行
K(K-1)/2次。

或者可以直接输入两个 span 到二分类器中,判断这两个 span 是否代指同一个实体。若有 N 个 token,则有 K=N(N-1)/2 个 span,需要运行 K(K-1)/2 次。
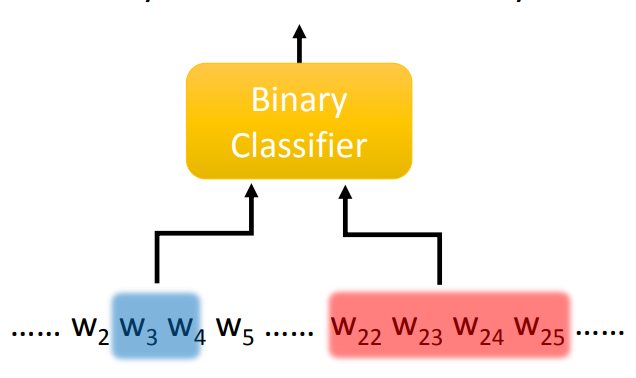
训练二分类器
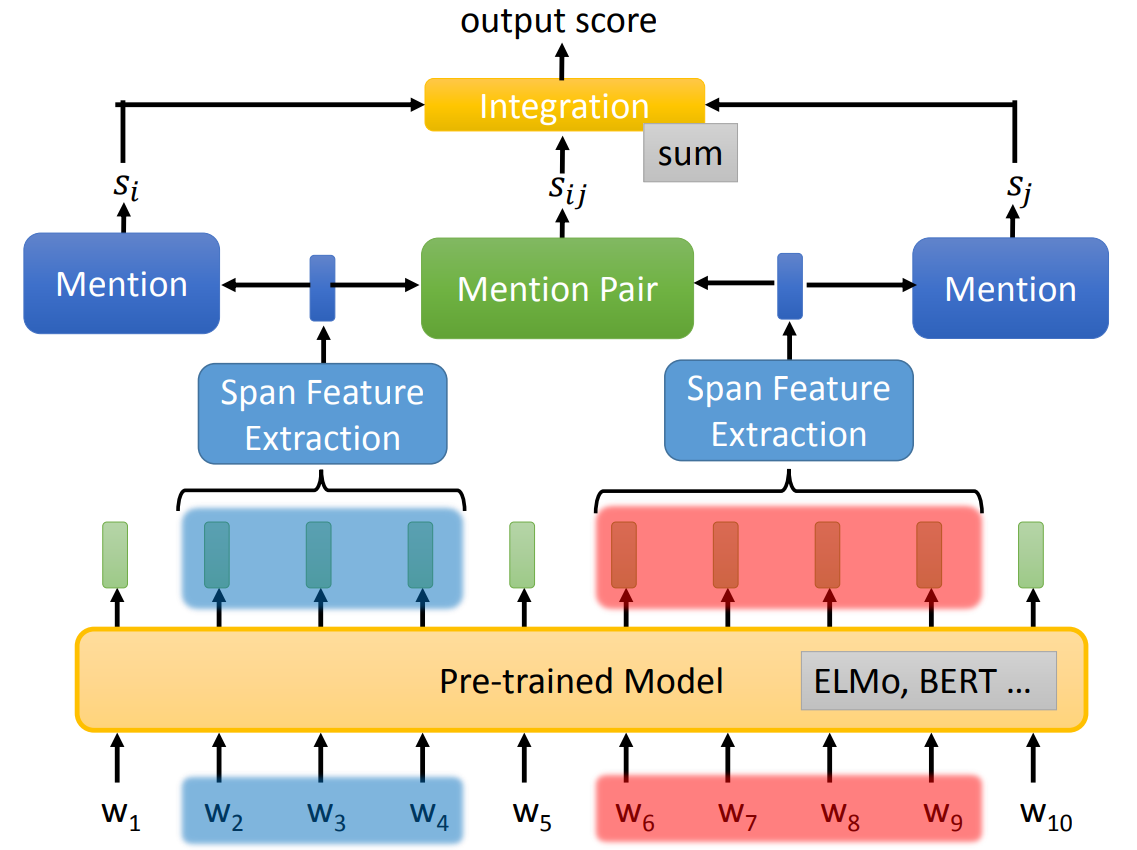
一个通常的用于 Coreference Resolution 二分类器如下:
将句子中的所有 token 输入预训练模型中,得到 embedding。
将 embedding span 输入 Span Feature Extraction,得到两个向量(每一个 Span Feature Extraction 将 embedding 汇聚成一个 embedding)。
判断两个向量是否是 mention、是否属于同一个 cluster,最终输出一个分数。
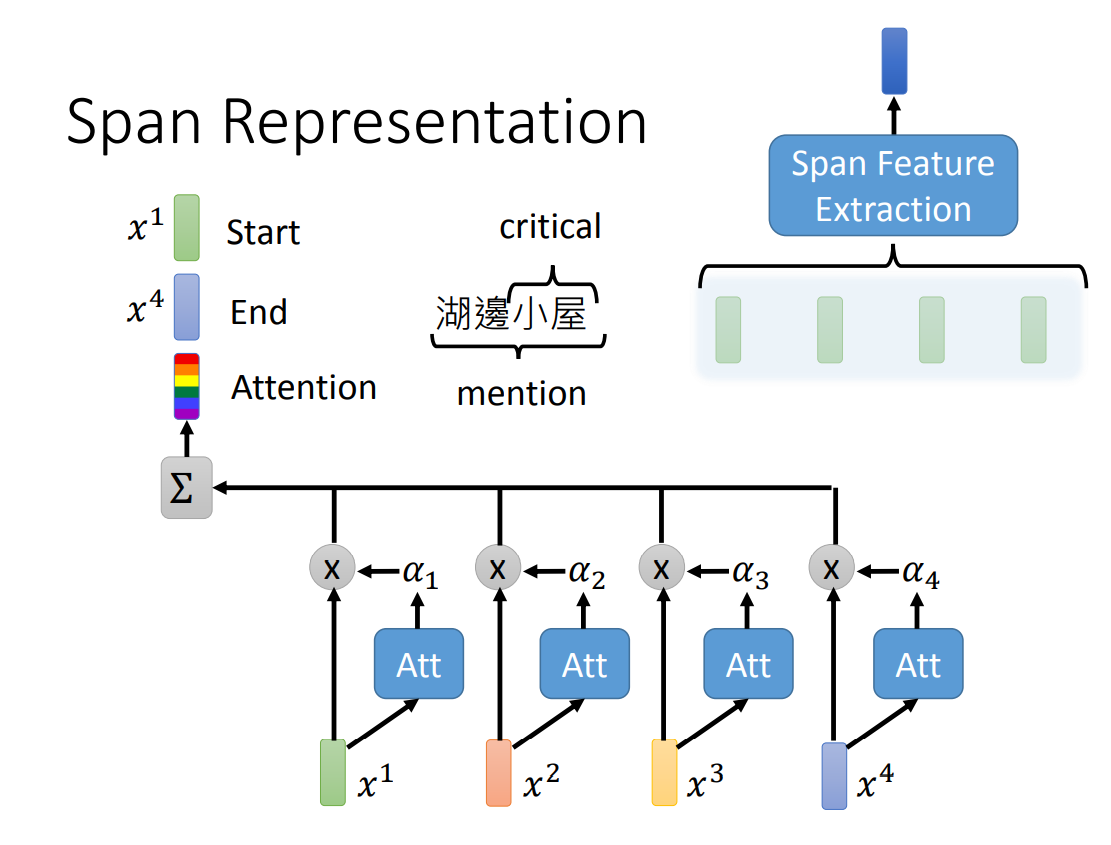
对于 Span Feature Extraction,结构如下。将 embedding span 进行 Attention,得到一个 Attention 向量,再把 span 中起始 embedding 和最后一个 embedding 与 Attention 向量相加,得到 Span Feature Extraction 的输出向量。
上述是有监督模型,那么是否可以训练一个无监督模型呢?
答案是可以的,把 mention Mask 起来,这样模型的输出就是相关的代指实体。
