Self-Attention 机制
将各个向量放入 Self-Attention(可以使用多次) 中,得到与整个句子都相关的另外的向量。
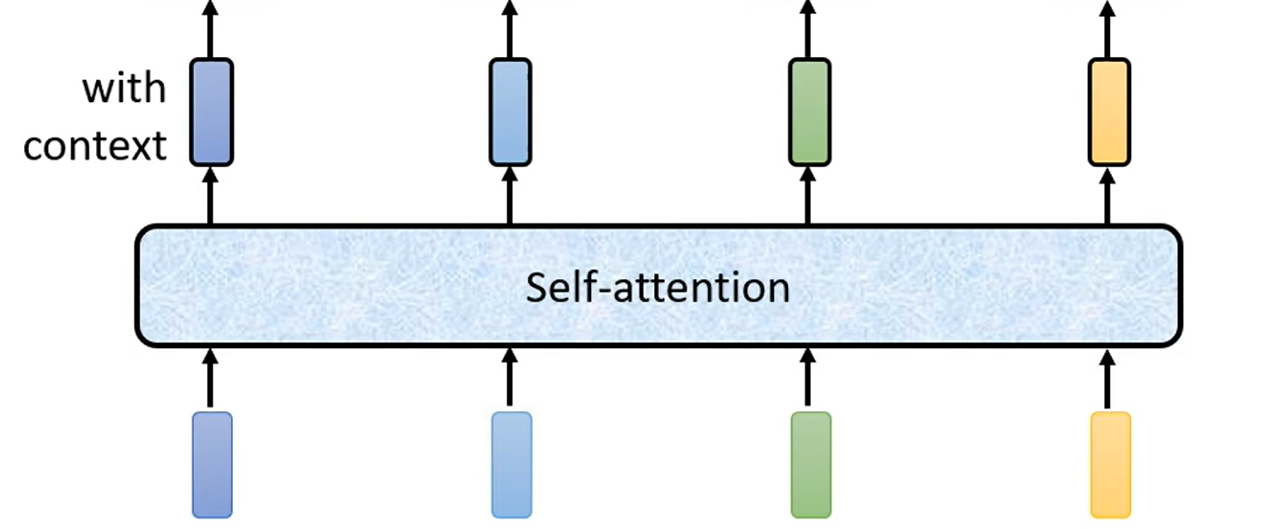
结构
Self-Attention 层,输入一些向量,输出另一些向量。每一个输出的向量与输入的向量都有关系。
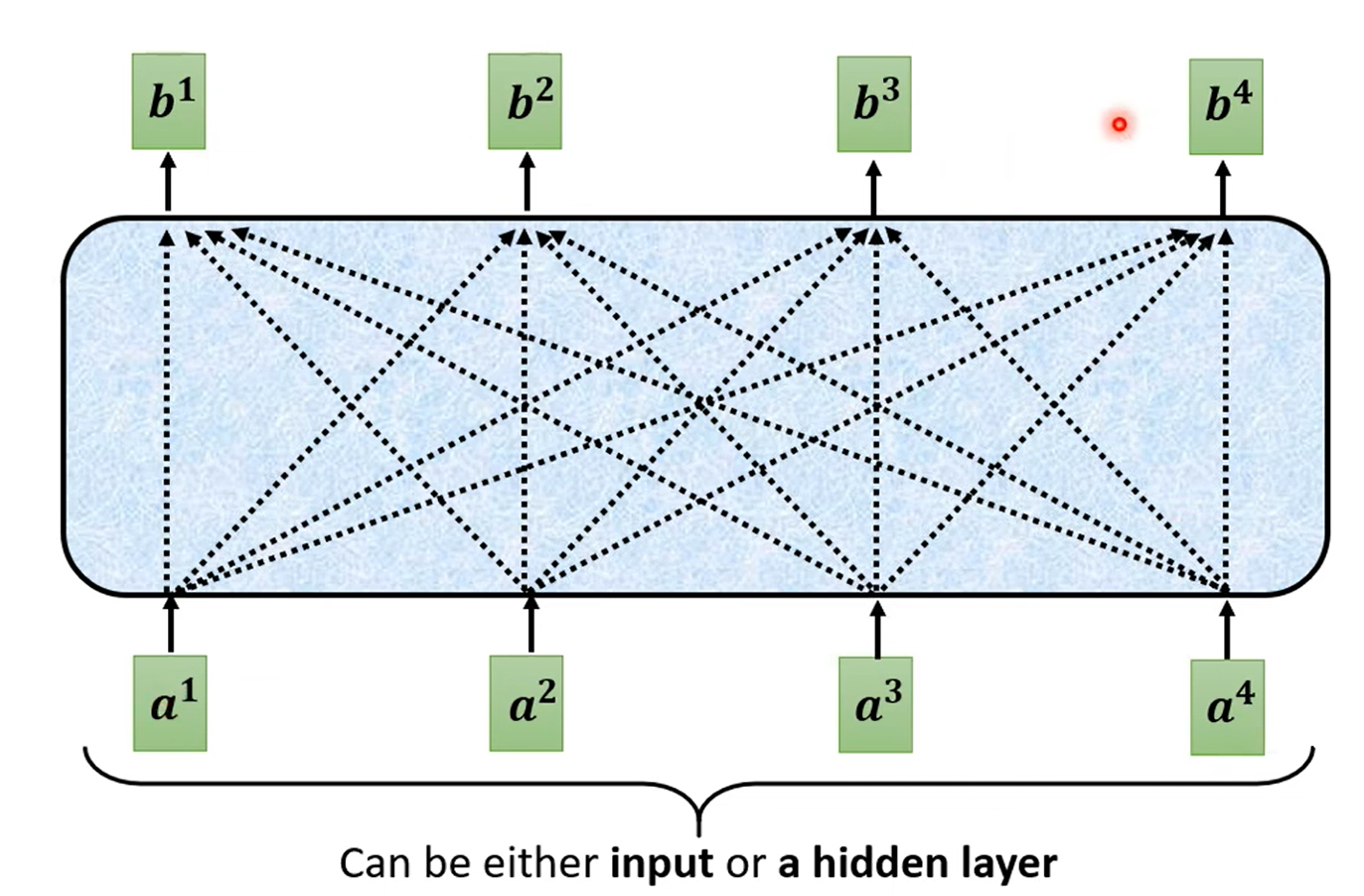
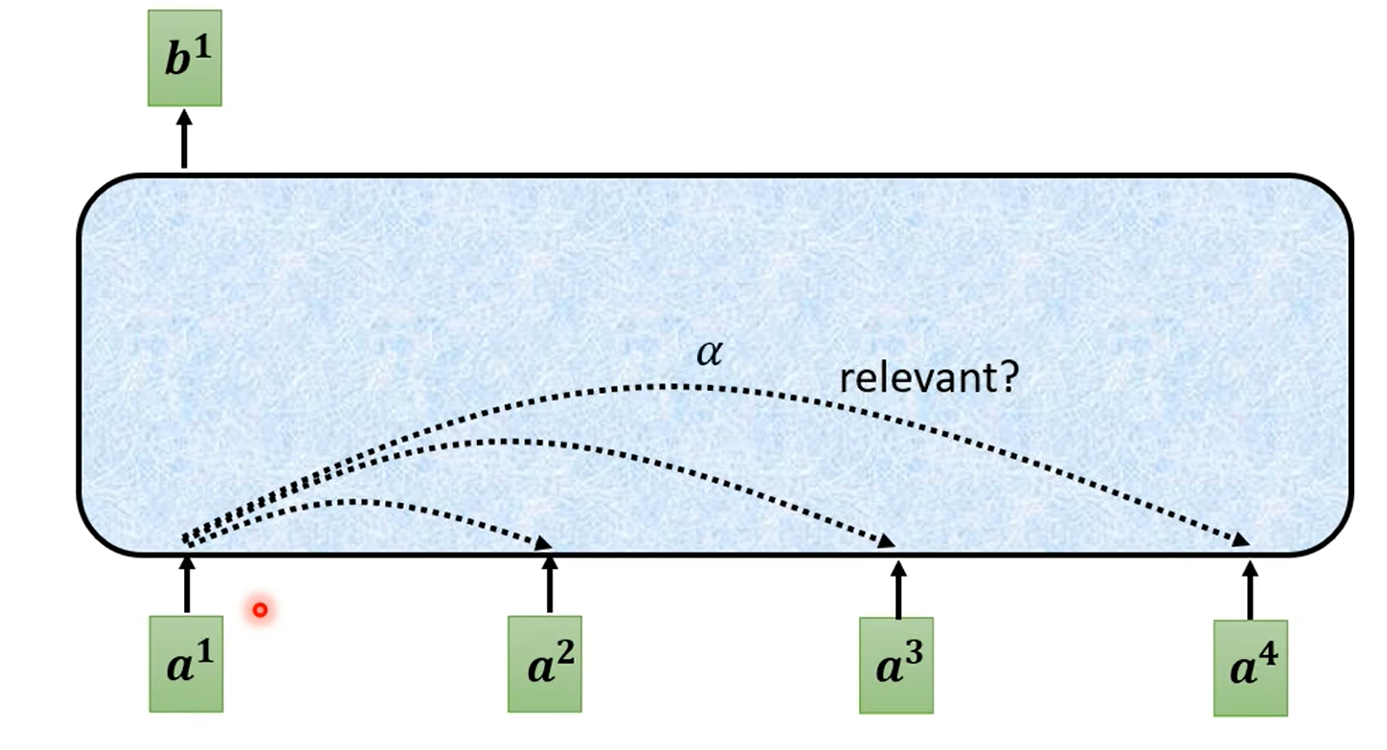
对于如何输出一个向量,实际上是看其他向量是否对应的输入有关系(relevant)。这里的有关系的程度用 α 表示:
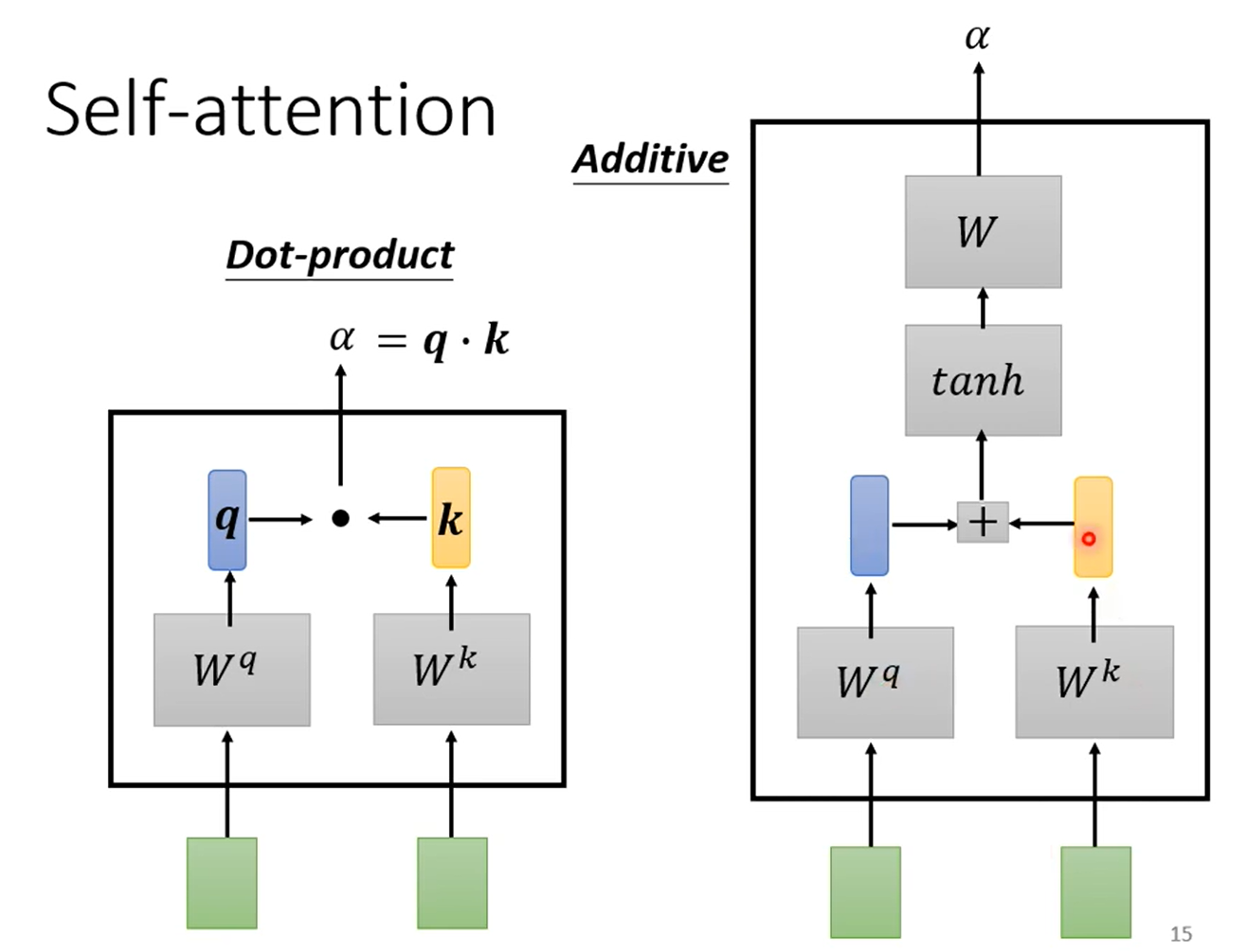
对于如何计算 α,有两种方式:
- Dot-product:输入向量乘以一个矩阵 W,之后再做点乘,点乘结果为 α。(transformer使用)
- Additive:输入向量乘以一个矩阵 W,相加之后进入 tanh,最后经过线性变换得到 α。
过程
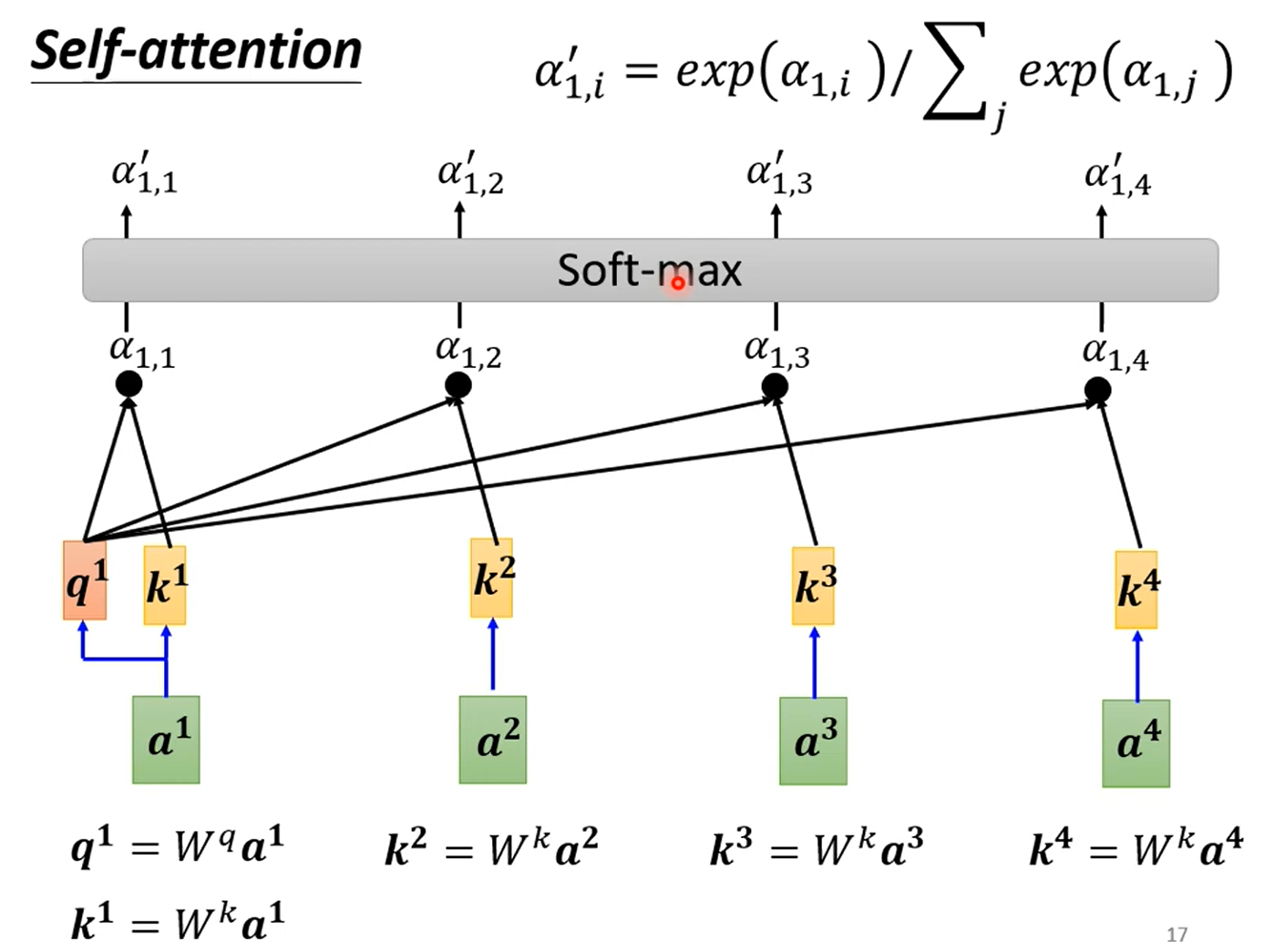
- 得到相关性分数 α:首先输入乘以矩阵得到向量 q 和 k,将 q 和 k 点乘(dot-product)后进入 soft-max(作用是 normalization,也可以用其他的) 层:
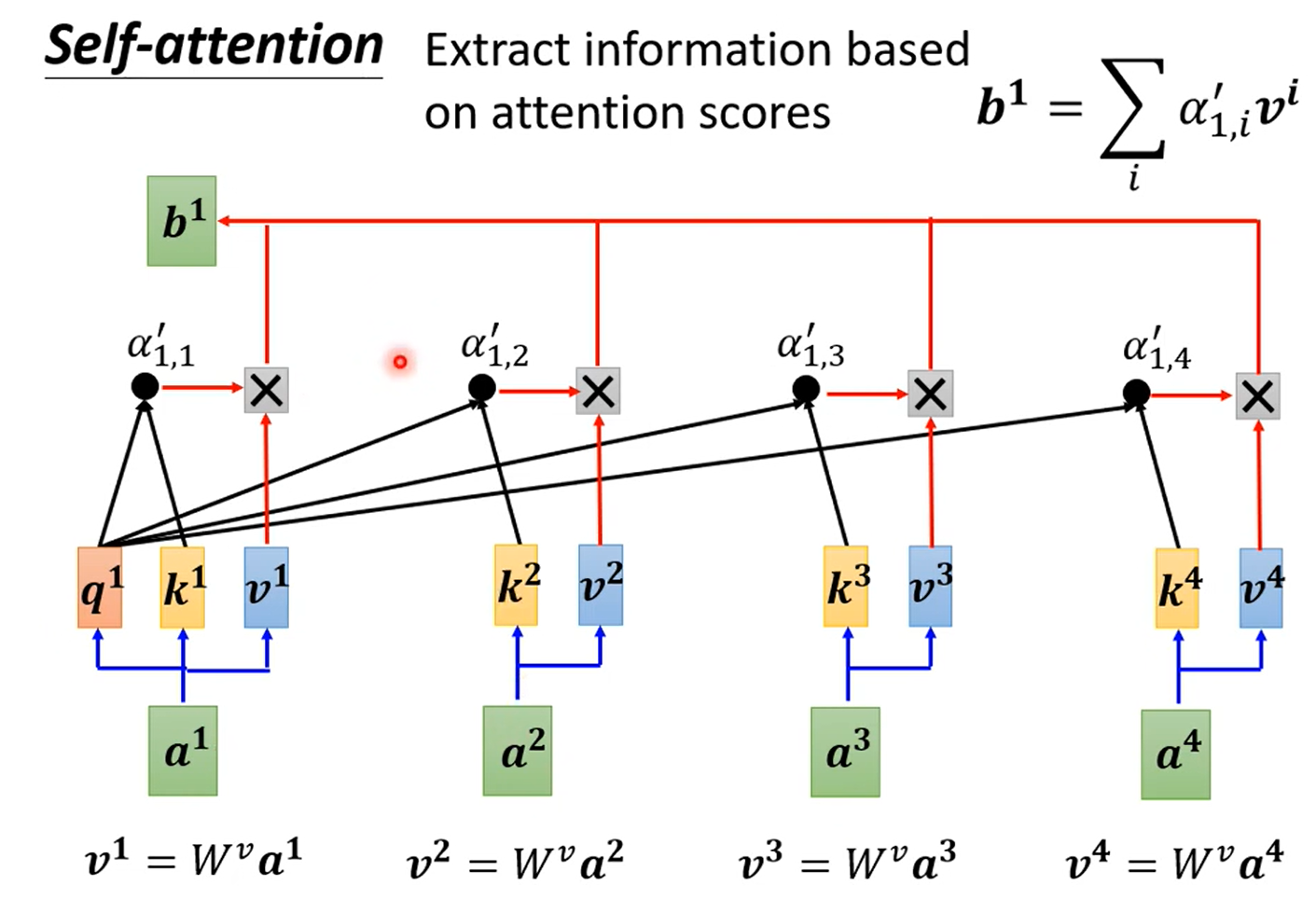
- 根据 α 提取信息:将输入与矩阵相乘得到向量 v,再与 soft-max 的输出相乘并相加得到 Self-Attention 的输出 b。相关性大,则 α 大,所以输出中对应 v 的占比越高。
Multi-head Self-Attention
这是 Self-Attention 的变形,用于计算不同种类的相关性。
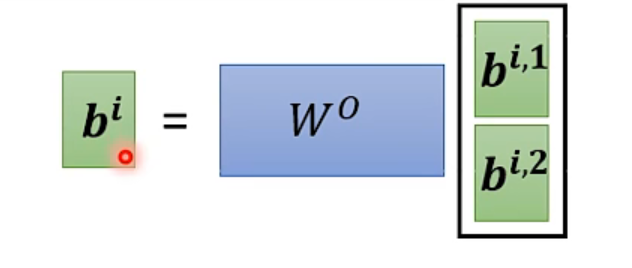
最大的不同就是 q、k、v 三种向量乘以多个矩阵(矩阵的个数就是 head 的数量,即种数)得到不同的种类,每一种单独 Attention 得到每一种对应的输出。
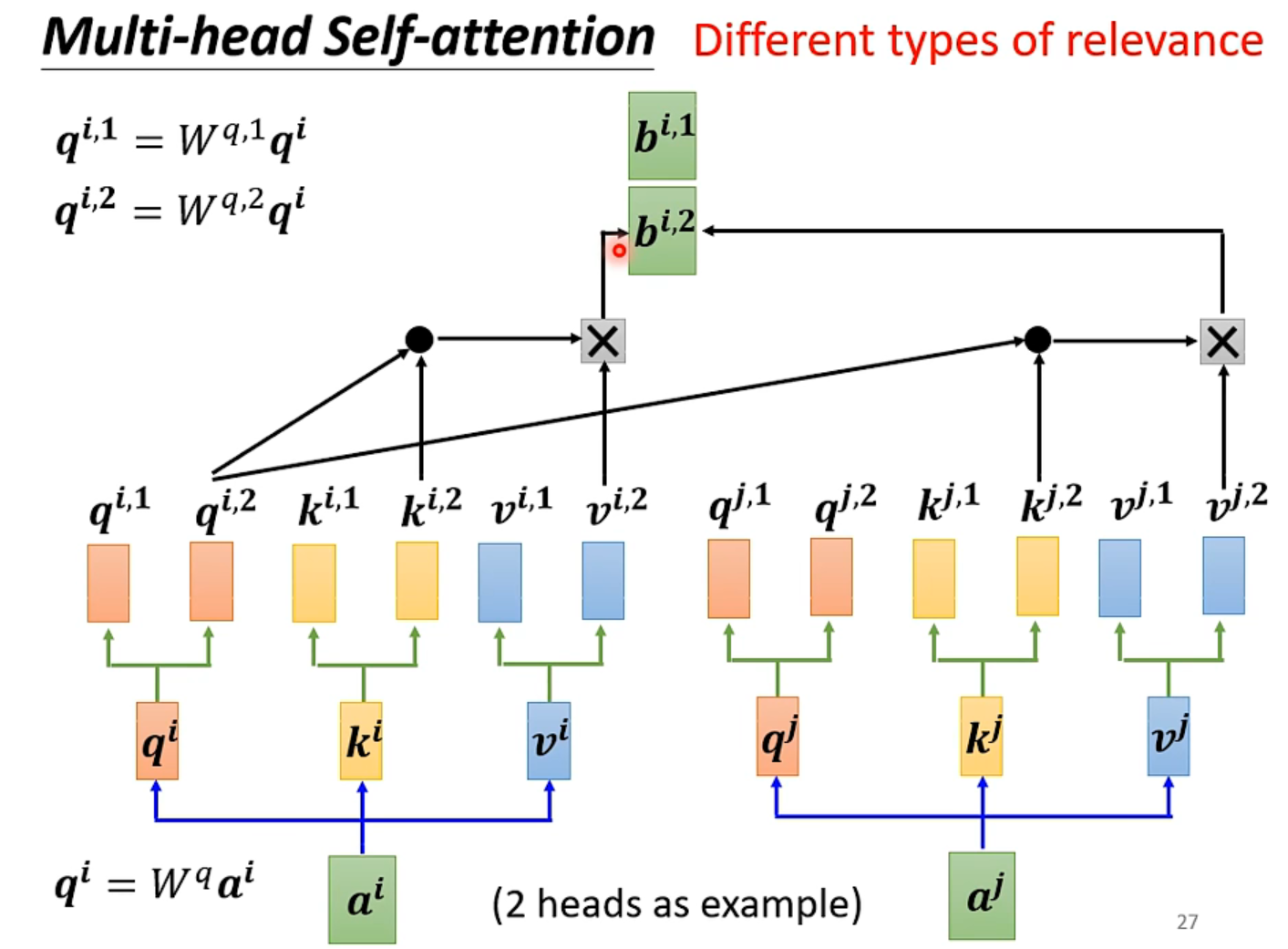
最后将每一种输出乘以一个矩阵,得到最终的输出。
加上位置信息 - Positional Encoding
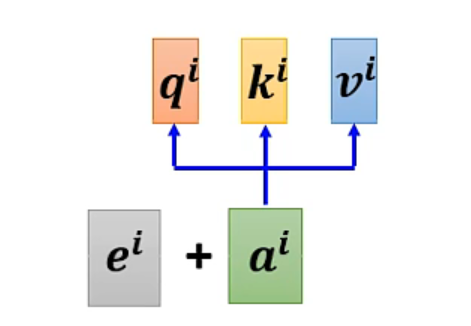
上述的 Self-Attention 中,是没有位置信息的。若需要位置信息,则需要 Positional Encoding。具有工作如下:
- 每一个位置 i,都有一个唯一的位置向量 ei
- 输入加上位置向量之后再 Attention 即可
Transformer
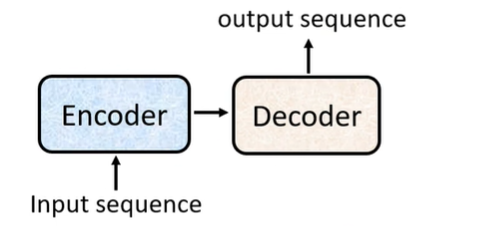
Transformer 是一种 Seq2seq Model(输入一个 sequence,输出一个 sequence)。
Seq2seq 结构
Seq2seq Model 的结构包括一个 Encoder 和一个 Decoder。
Encoder
Encoder 输入一排向量,输出另外一排向量。
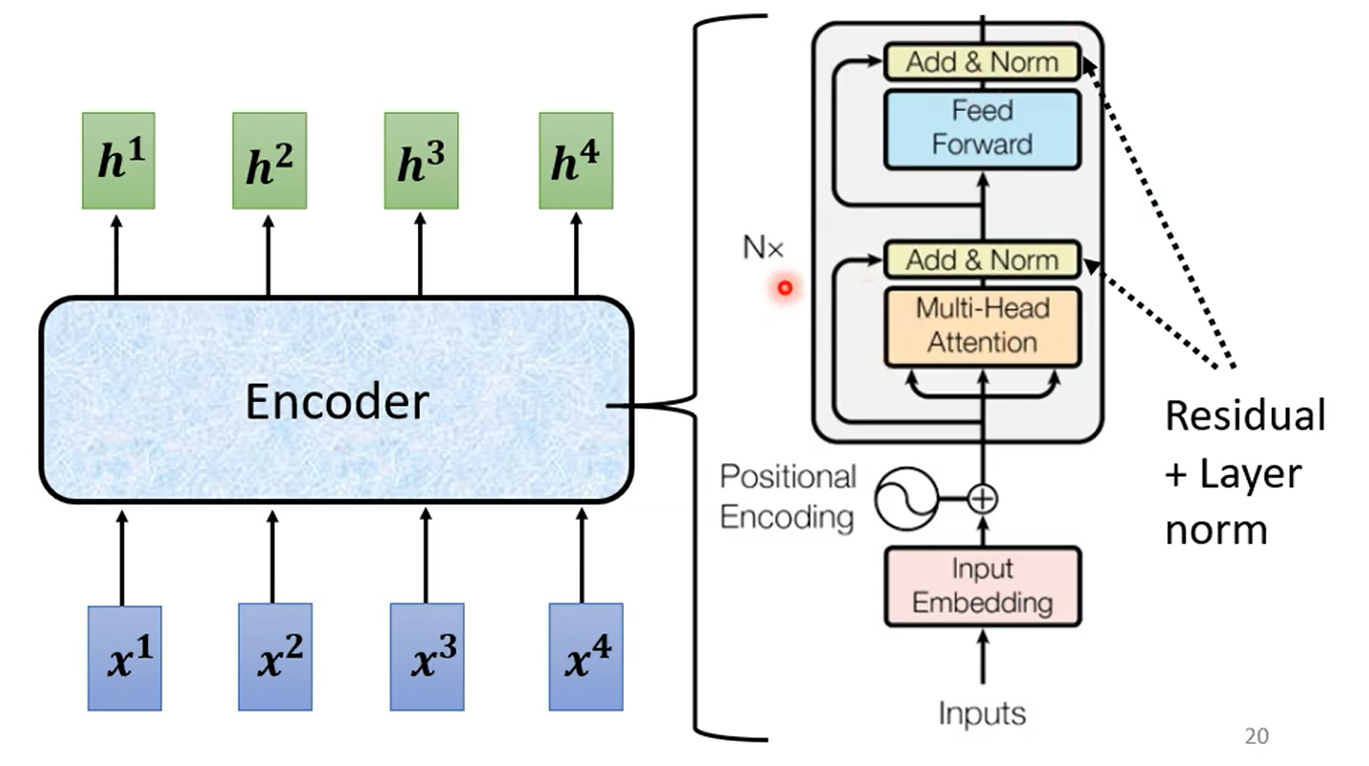
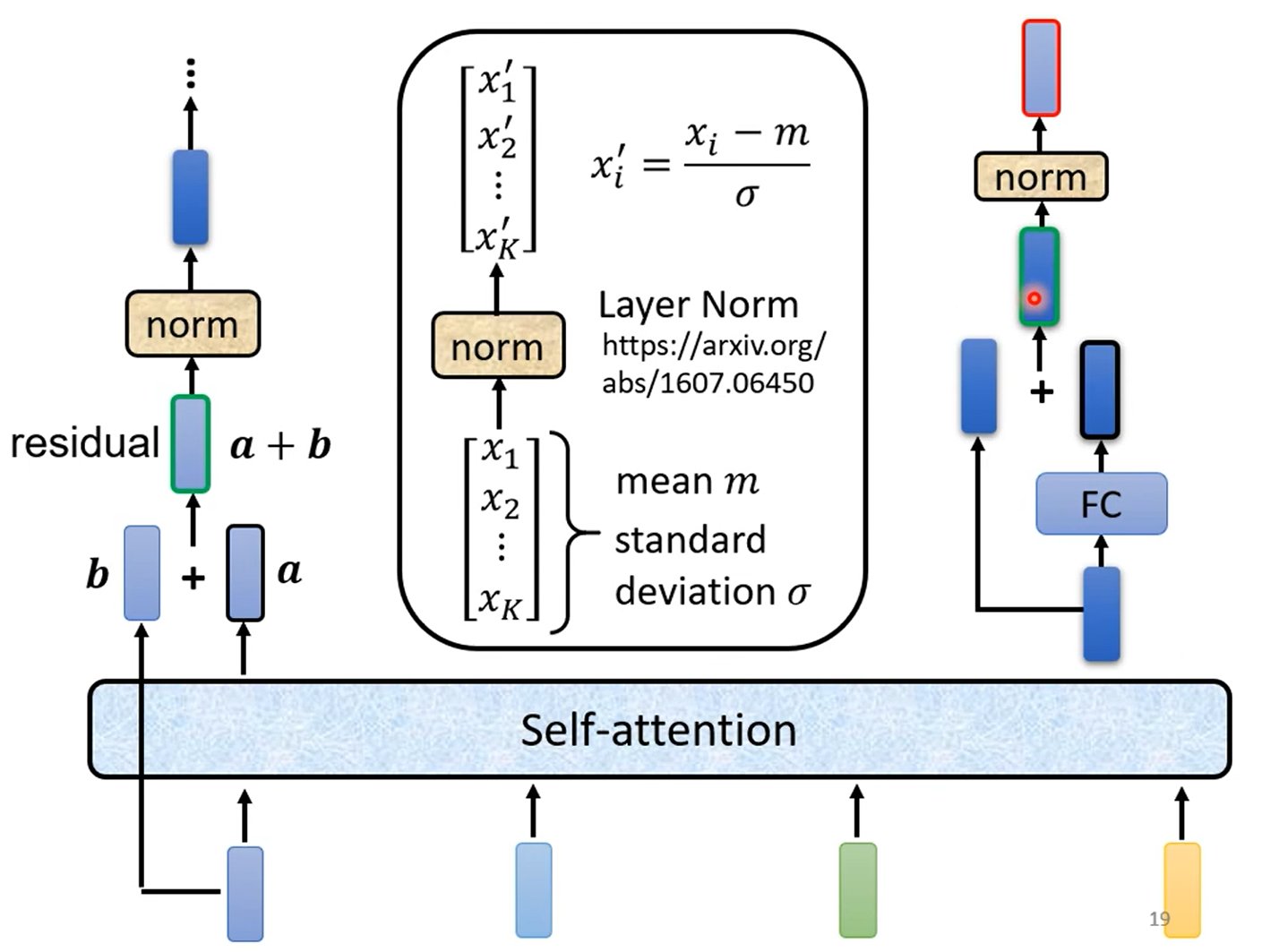
其中 Encoder 是 N 个 block 的重复,每一个 block 的结构如下:
- Self-Attention
- Residual + Norm
- 全连接层(上图中 Feed Forward)
- Residual + Norm
Decoder
Autoregressive(AT)
Autoregressive 就是在输出时,从左到右依次输出。其最显著的特点就是,每一个 Decoder 的输出作为下一次 Decoder 的输入。
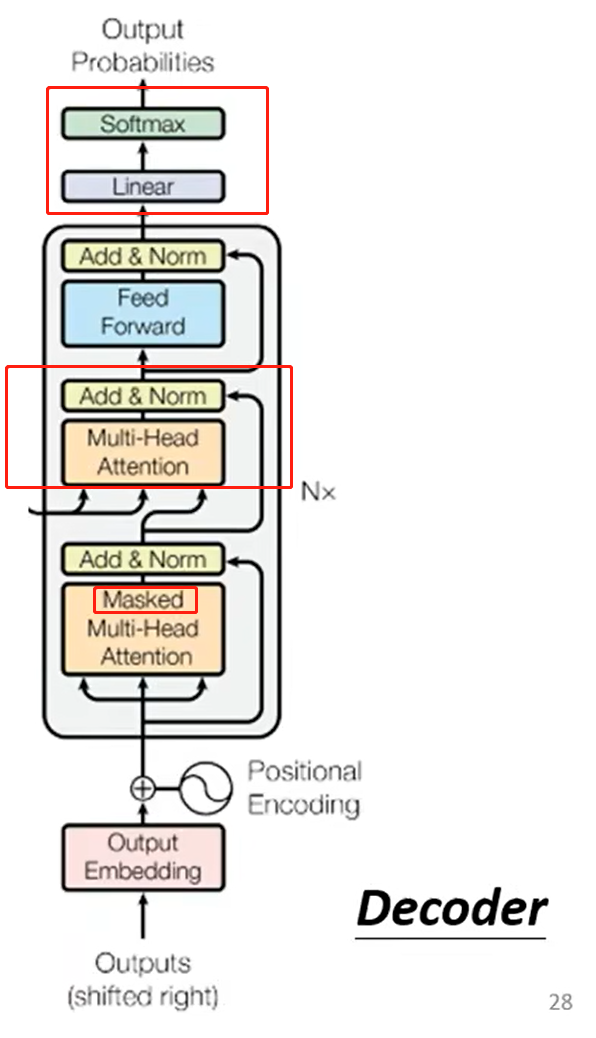
Decoder 和 Encoder 的结构比较类似,区别在于:
- 第一个 Attention 变为了 Masked Multi-Head Attention(Encoder中为 Multi-Head Attention):Mask 的含义就是每一次 Attention,只看前面的向量,不看后面的向量。

- 增加了一层 Multi-Head Attention 和 Add & Norm
- 最后一个 block 的输出进入线性层和 soft-max 层,输出的是最大可能性对应的结果(将这个输出放入下一次 Decoder 的输入)。
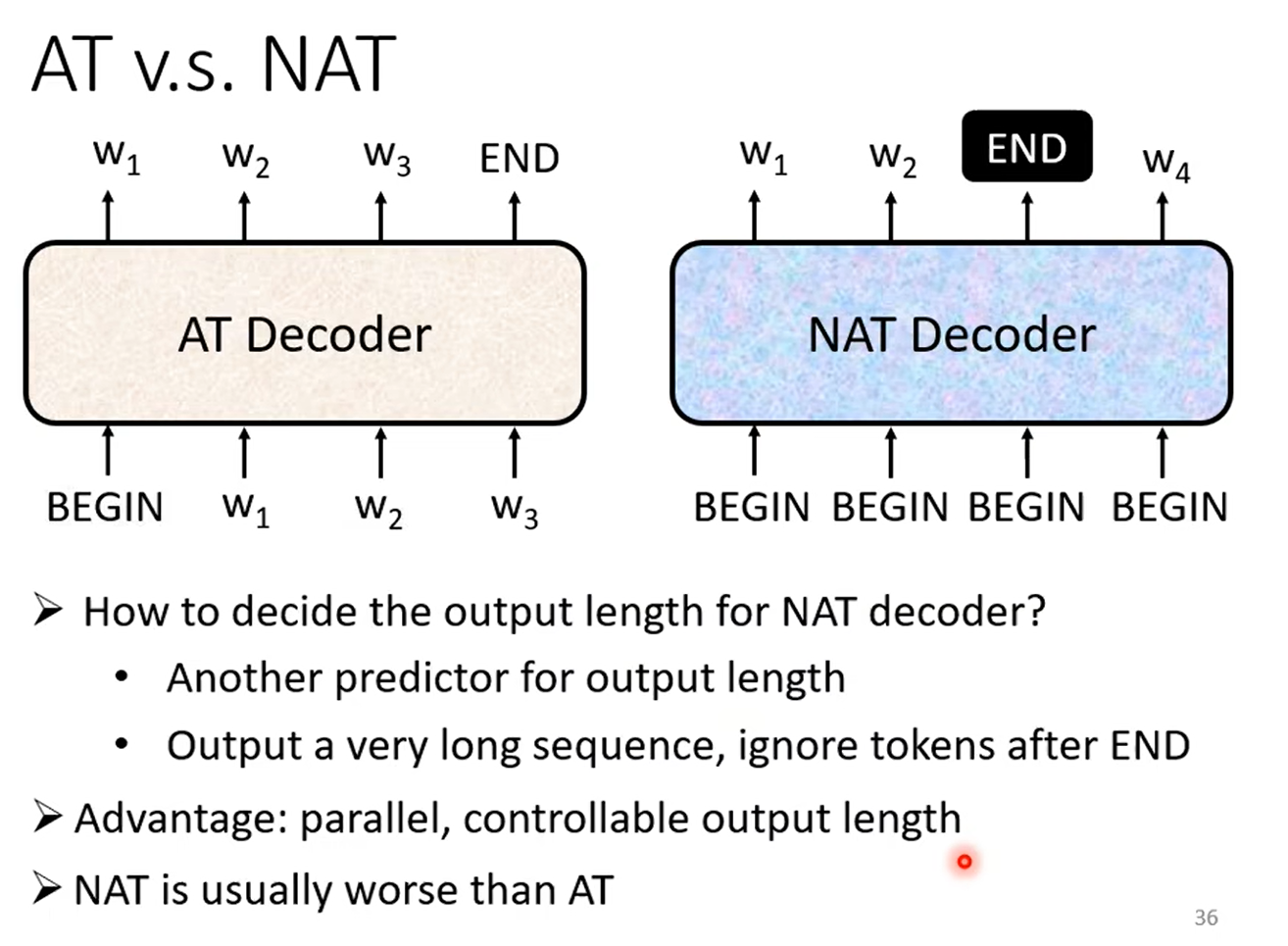
Non-autoregressive(NAT)
AT 和 NAT 的比较:
- AT 将 Decoder 的输出作为下一次 Decoder 的输入;NAT 输入的只有 BEGIN token,输入不会进入 Decoder 的输入。
- 如何得到 NAT 的输出长度?(Seq2seq 输出长度是不确定的)
- 训练一个 Model 进行输出长度的预测。
- 输出一个很长的 sequence,忽略 END token 之后的东西。
- NAT 的优点:
- 可以并行化计算,因为不用等待上一个 Decoder 的输出。
- 可以控制输出长度。
- NAT 通常比 AT 表现更差。
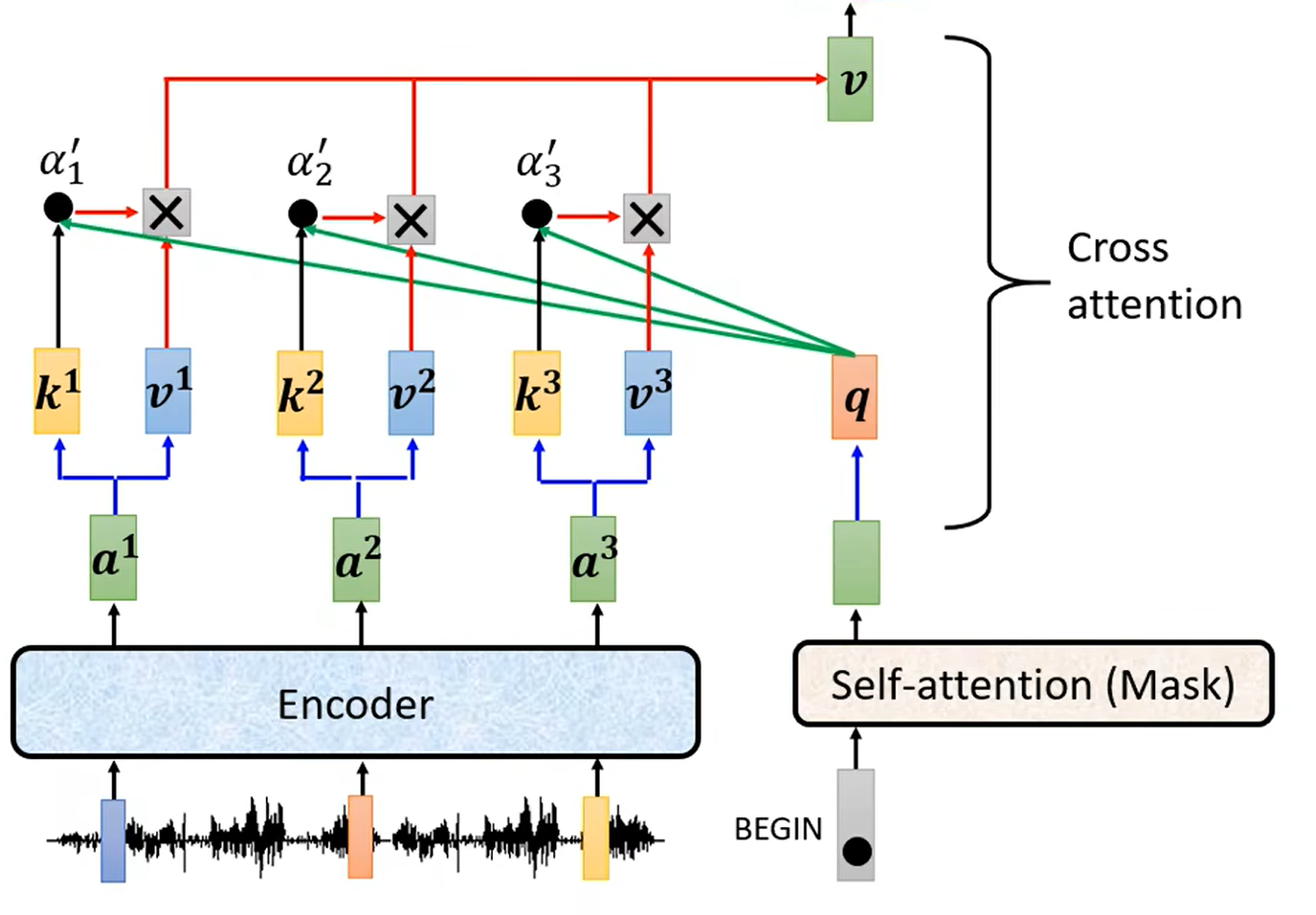
Encoder-Decoder 之间的连接部分
实际上,Decoder 中多出的一层 Multi-Head Attention 和 Add & Norm,就是用于连接 Encoder 和 Decoder。
这一部分被称为 Cross Attention。
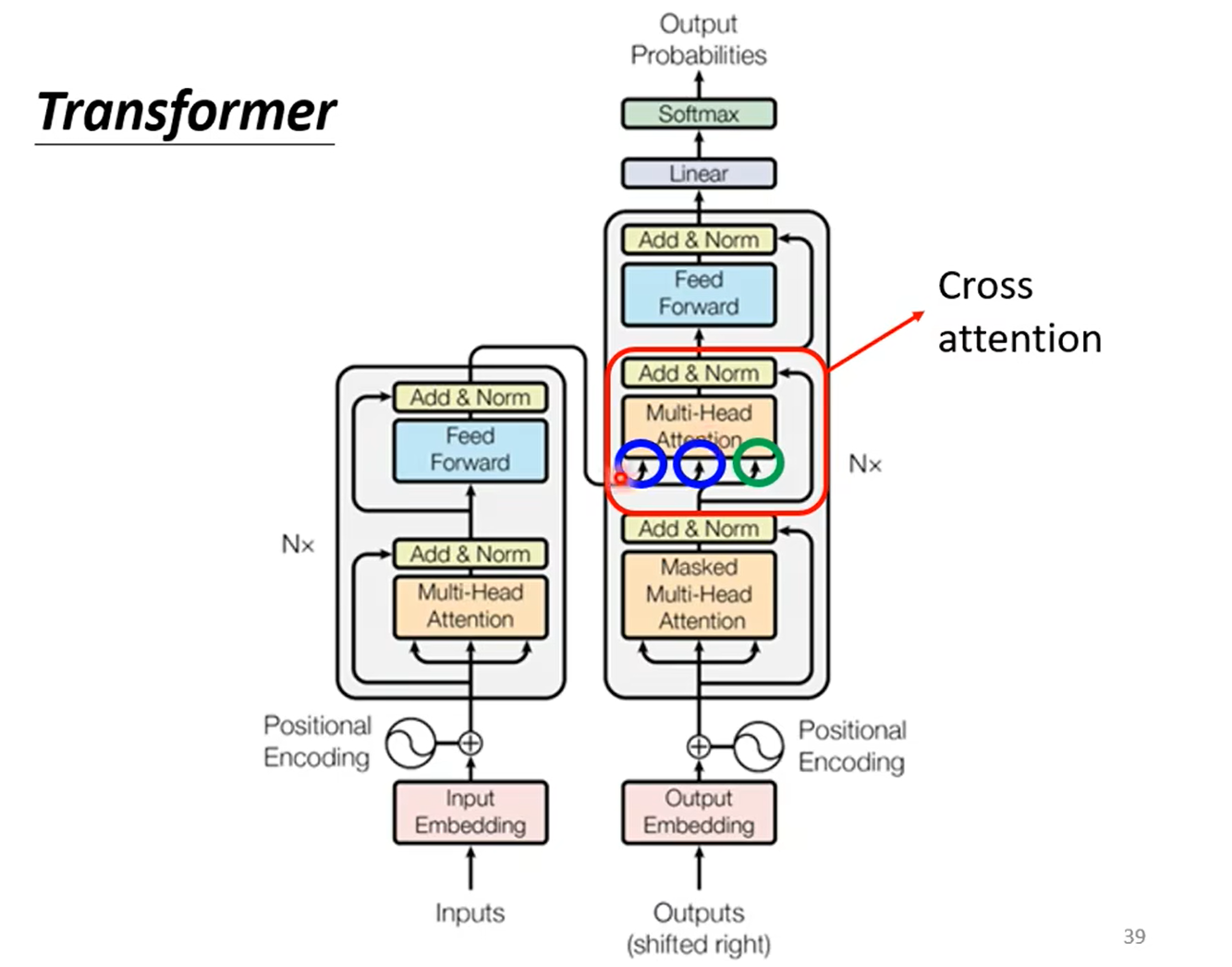
Cross Attention 的详细结构如下,计算 Decoder 中 Masked Multi-Head Attention 的输出向量与 Encoder 的输出之间的相关性(Attention)。
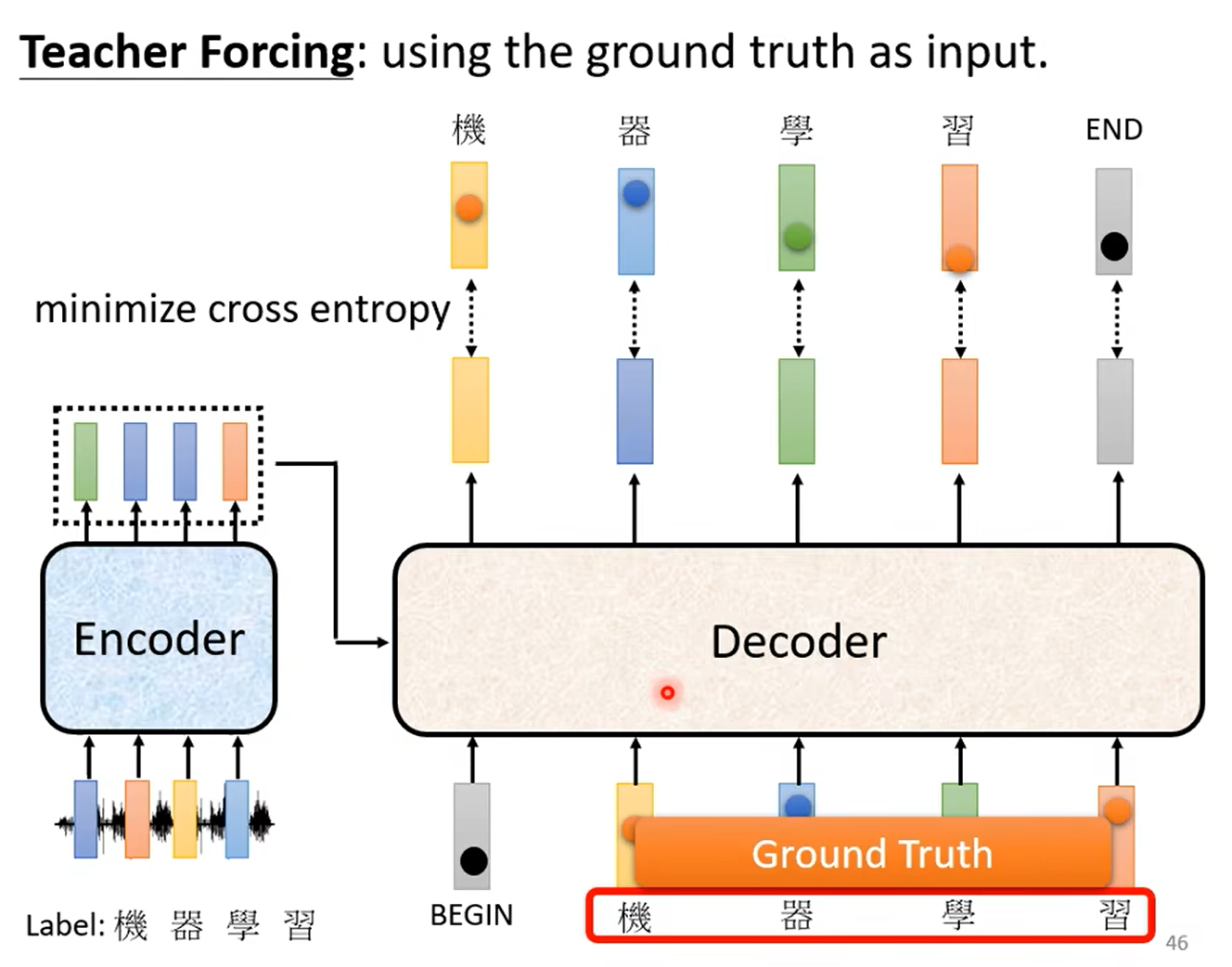
如何训练
训练时,采用强制学习(Teacher Forcing):每一次向 Decoder 的输入并不是上一次 Decoder 的输出,而是正确的结果。