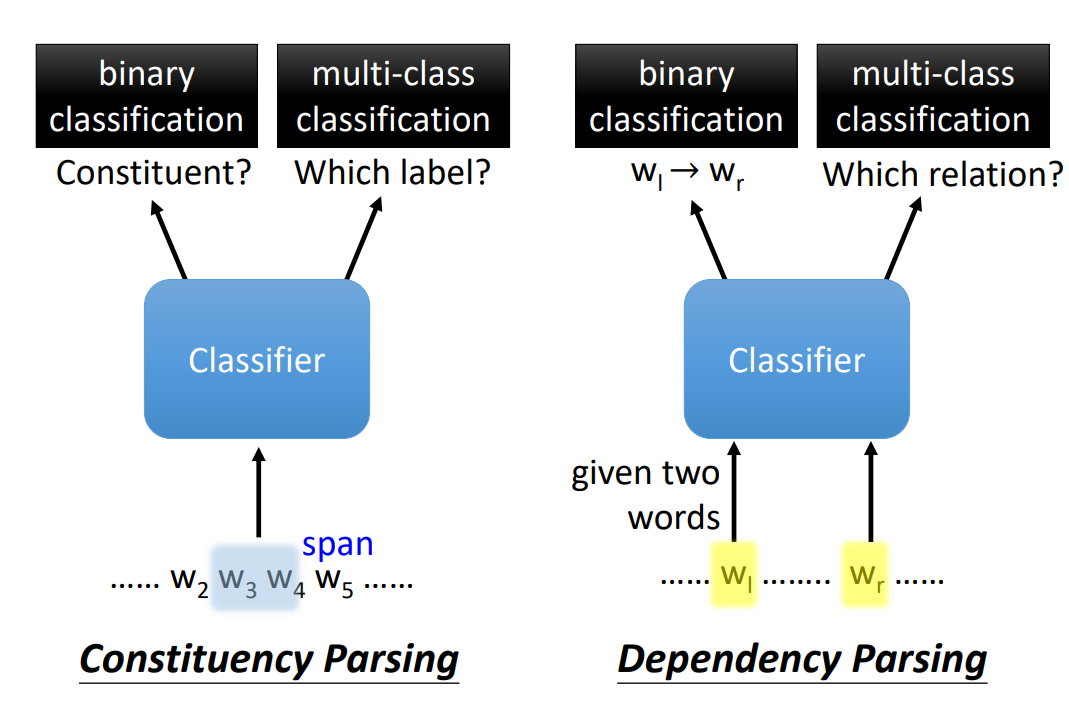
Constituency Parsing
Constituency Parsing 就是:
找出一段 text span 作为 constituents
每一个 constituents 都有一个标签

- 对于每一个单词都是一个 constituent(标签为这个单词的词性)
- 相邻的 constituent 可以组成一个更大的 constituent
- 一句话的所有单词,从底向上,可以组成一棵树
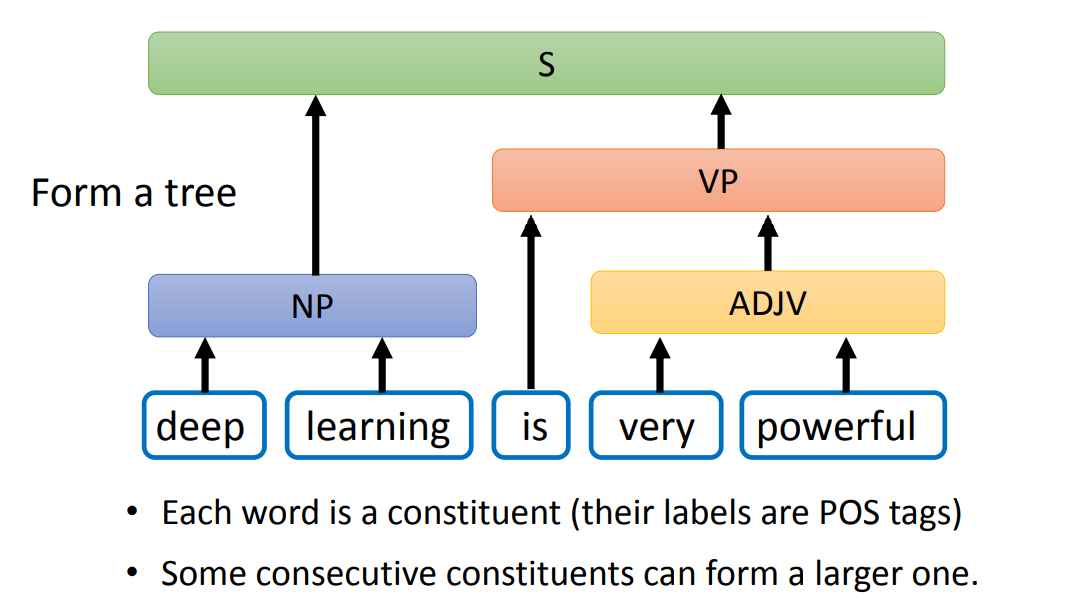
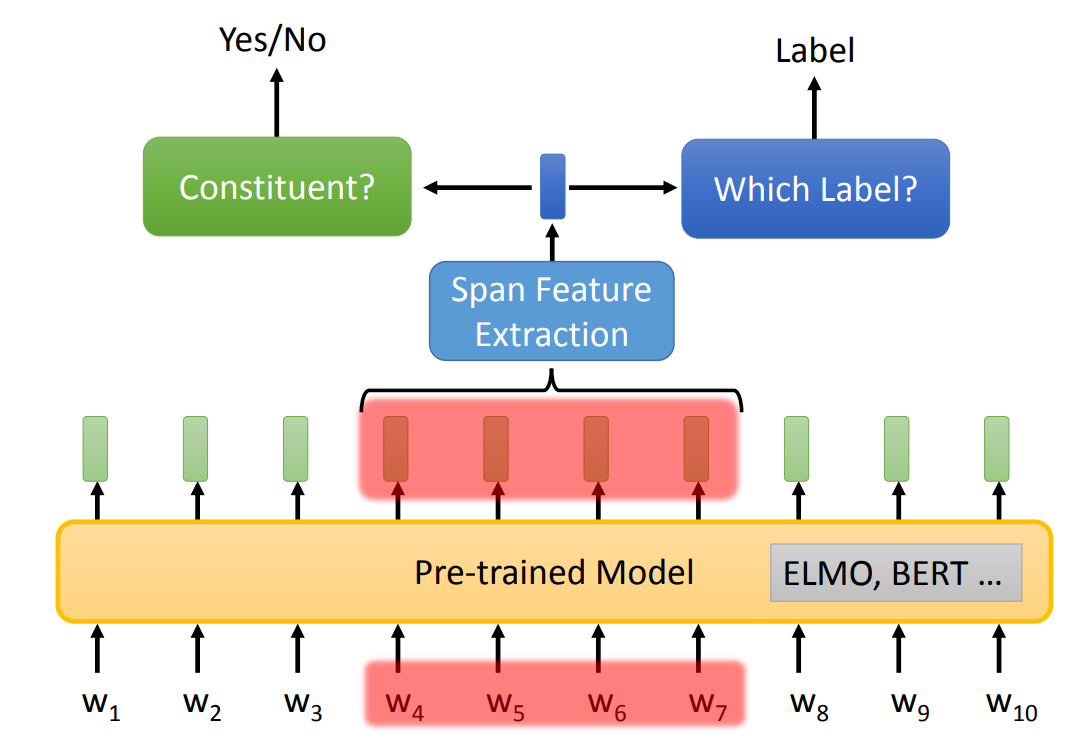
Chart-based
Chart-based 方法实际上就是对每一个 span 进行两次分类:
- 放入二分类:判断是否是 constituent
- 放入多分类:constituent 属于哪一个标签
下图是 Chart-based 的结构,其中 Span Feature Extraction 与 Coreference Resolution 中的一样。
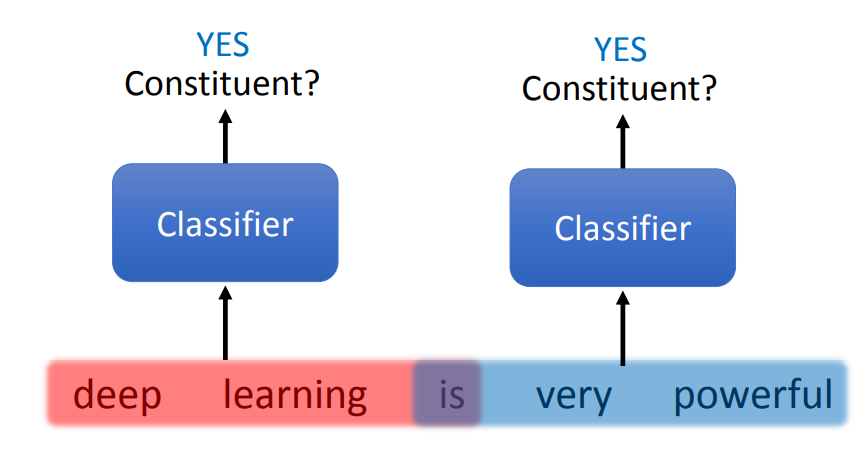
需要注意的是,对于 span 的选择可能会产生矛盾,比如两个重合的 span 都被判断出是 constituent,那么就无法组成一棵树。
解决方法就是,穷举出所有可能性的树,然后对每一棵树进行评分,选取评分最高的树。
Transition-based
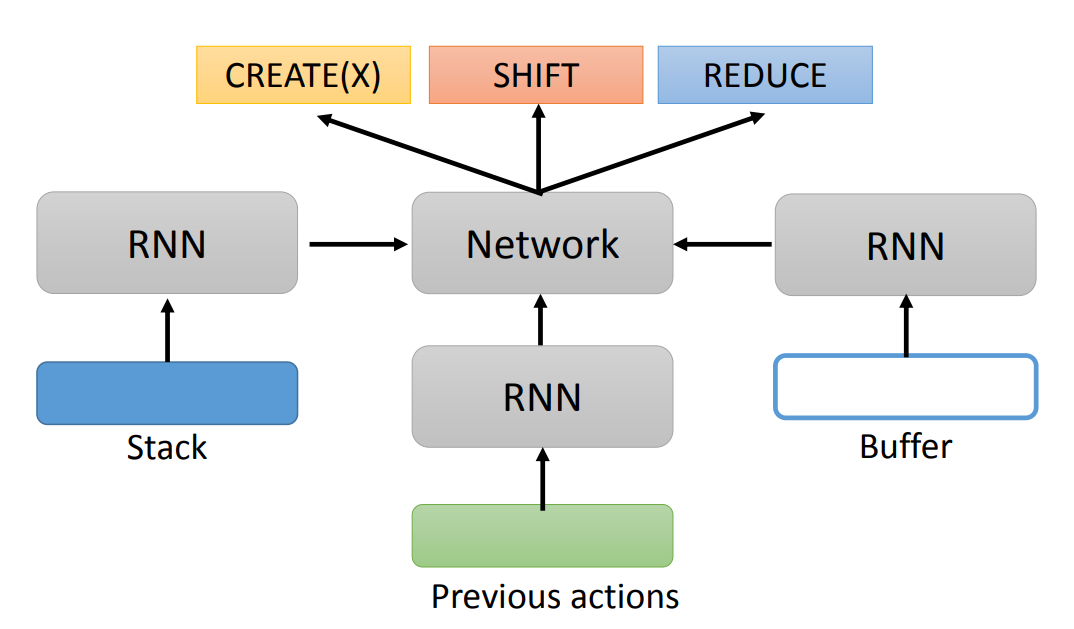
Transition-based 中由三个部分组成:
- Stack:初始为空。
- Buffer:初始存放整个句子。
- Actions:包括三种操作
- NT (X):创建一个带有 X 标签的 constituent
- SHIFT:将一个 token 从 Buffer 移动到 Stack 中
- REDUCE:结束一个 constituent

实际上,我们需要训练一个分类模型,用于输出 Actions。
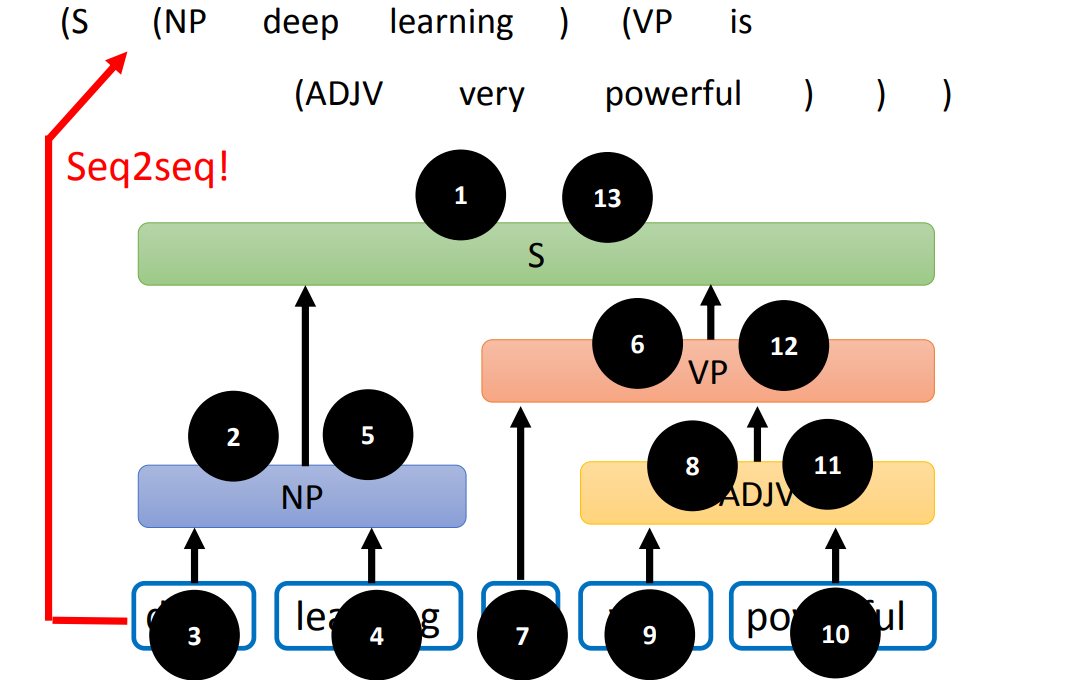
Tree to Sequence
甚至,我们可以利用 Seq2seq Model,将语法树变为一个 Sequence,比如:
对树进行遍历,得到遍历序列,这个遍历序列就是 Sequence。需要注意的是,这个模型不需要输出单词(因为可能会改变输入的句子),可以用 XX 表示输入的一个单词。
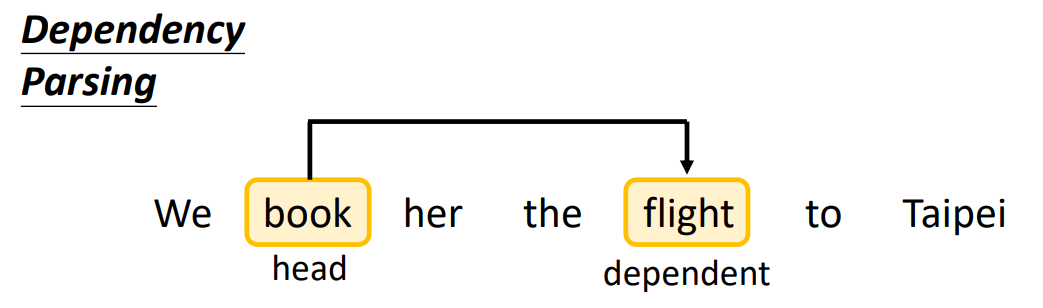
Dependency Parsing
Constituency Parsing 考虑的是一个句子中,相邻单词的关系。
Dependency Parsing 考虑的是任意两个单词(不需要相邻)的关系,用箭头表示这种关系(标签为关系的类别),起始为 head,结束为 dependent。
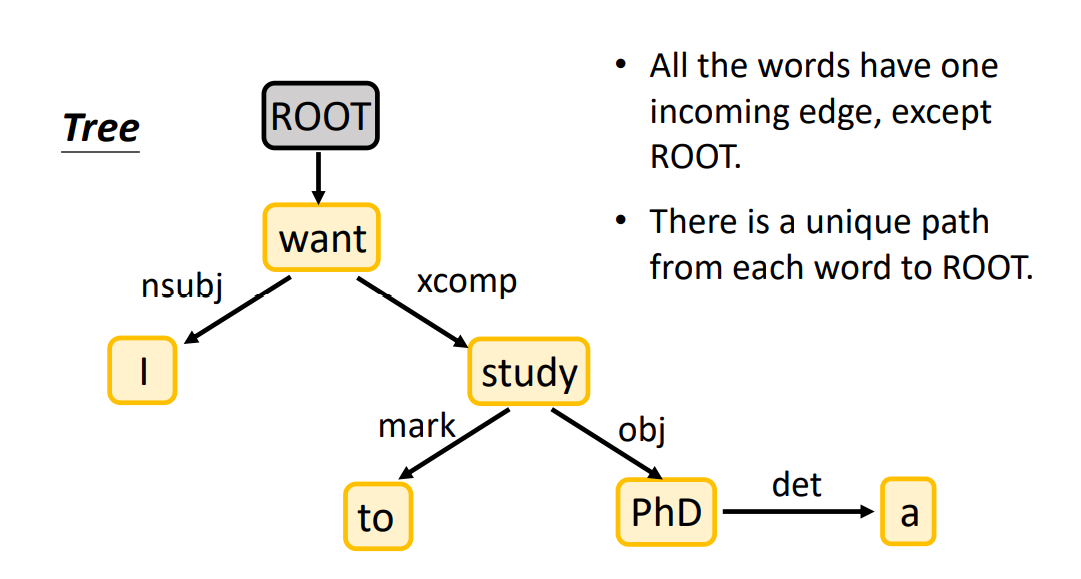
Dependency Parsing就是将一句话变为有向图(Directed Graph,实际上也是一棵树),word 变为 node,关系变为 edge。
- 所有 word 只有一个入边(除去 ROOT)。
- 从每一个 word 到 ROOT 有唯一的一条路径。
核心方法就是:两个分类器,输入是两个 word。
- 判断左边是否指向右边。
- 判断属于哪一种关系。