论文
Classifying Relations by Ranking with Convolutional Neural Networks
发布年份:2014
会议:ACL
作者:Cicero Nogueira dos Santos, Bing Xiang, Bowen Zhou
机构:IBM
贡献:提出了一种新的 CNN 结构,Classification by Ranking CNN(CR-CNN)用于解决关系分类问题。经实验表明,CR-CNN比CNN加上简单的softmax分类的效果要好。
数据集:SemEva 2010 task 8 dataset,这个数据集包括 10717 个examples,有 9 个不同的类别和 1 个人工关系 Other。8000 个训练用例和 2717 个测试用例。
创新点:
- 提出了新的 loss function,pairwise ranking loss function。
- 忽略了 SemEval 2010 task 8 中的 Other 类。
模型结构
模型结构示意图如下,模型的输入是一个句子(带有两个目标词),CR-CNN为每一个关系类型计算出一个分数。
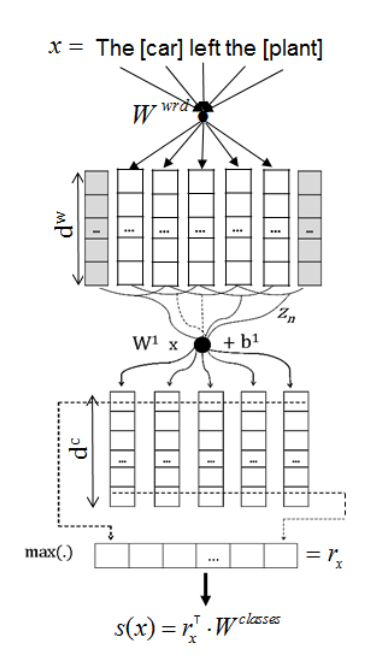
Word Embedding & Word Position Embedding
CNN 的输入由 Word Embedding 和 Word Position Embedding 拼接而成。
Word Embedding 使用 skip-gram 预训练模型。
Word Position Embedding 使用与目标词的相对距离作为位置向量,与两个目标词的相对位置会生成两个位置向量,将这两个位置向量拼接起来形成最终的位置向量。
Sentence Representation
通过 CNN ,经过卷积层后进行 max-pooling 操作,最终得到一个 Sentence Representation。其中,卷积核的数量等于 sentence representation 的维度。
Class embedding and Scoring
训练一个关系类型 embedding,与 sentence representation 相乘后,得到每一个类型相应的分数。
分数最大的即为预测结果。
Training Procedure(创新点)
提出了新的损失函数 pairwise ranking loss function,每一个 training step,都有两个不同的类别标签 y+ 和 c-(y+ 是正确的类别,c- 是错误的类别)。pairwise ranking loss function 的形式如下:
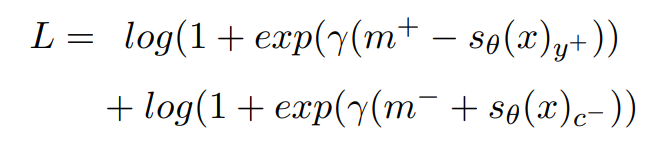
其中,m+ 和 m- 是边界(在论文中 m+ 被设置为 2.5,m- 被设置为 0.5),γ 用于放大分数与边界之间的差异(在论文中被设置为 2)。
因为在训练过程中需要最小化损失,所以**正确分类的分数会逐渐大于 m+,错误分类的分数会逐渐小于 m-**。
对于 c- 的选择,可以直接选取错误类别中得分最高的:
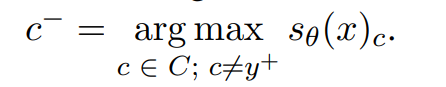
Special Treatment of Artificial Classes(创新点)
在 SemEval 2010 task 8数据集中,Other 表示二者的关系不属于任何一类,因此 Other 类非常 noisy,这些关系很可能没有共同点。
在 CR-CNN 中,忽略了 Other 类的 embedding,当一个句子的真实分类为 Other 时,训练时将 pairwise ranking loss function 的第一项置为 0。
在预测时,只有当所有自然类的分数都为负时,才会将一个关系归类为 Other,否则选择得分最高的自然类(人工类下只有 Other 类,除了 Other 类剩余的类别都是自然类)。
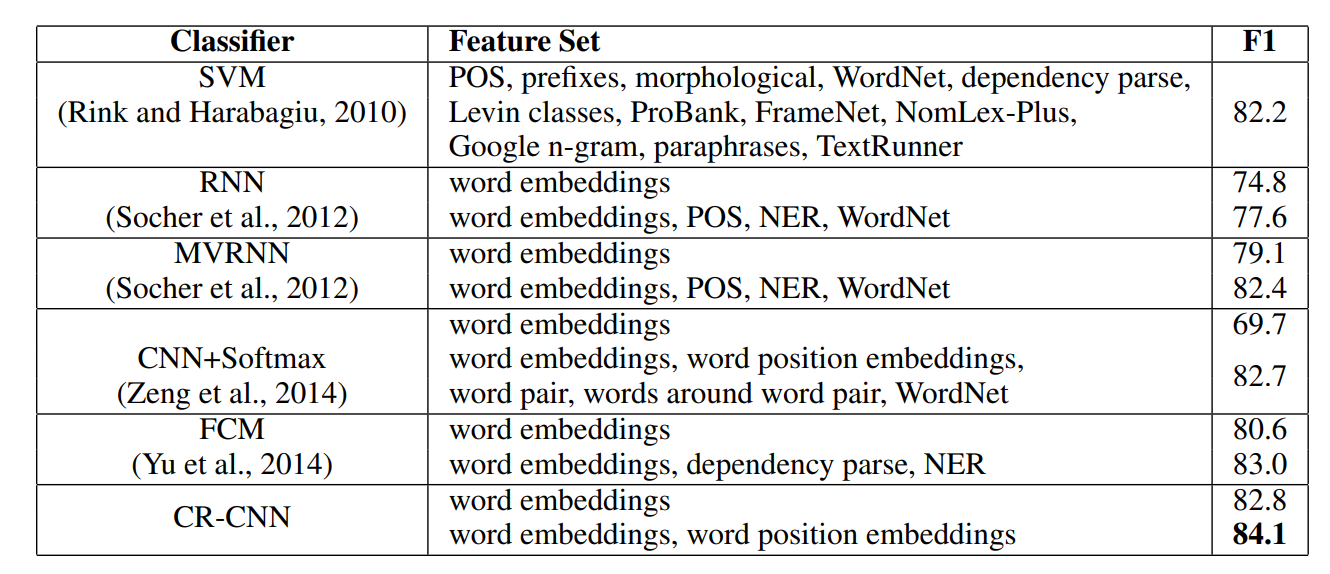
实验结果
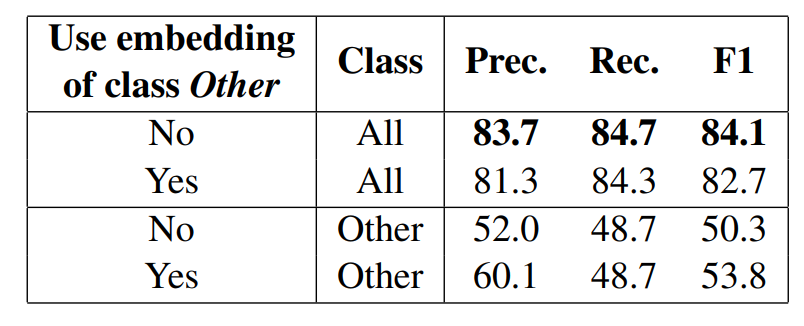
不对 Other 进行 embedding 的情况下,F1 值从 82.7 提升到了 84.1:
不同模型的对比,需要注意的是 CR-CNN 的效果要比 CNN+softmax 的效果好: