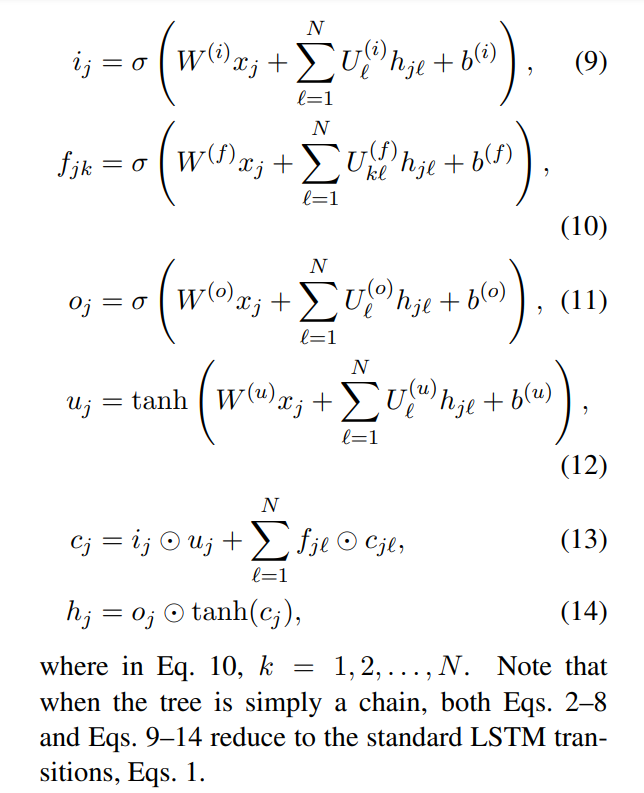论文
End-to-End Relation Extraction using LSTMs on Sequences and Tree
发布年份:2016
会议:ACL
作者:Mokoto Miwa, Mohit Bansal
机构:Toyota Technological Institute
贡献:
- 这是深度学习联合(Joint)模型的开篇之作。
- 在训练种加入两个功能,这些功能缓解了训练早期阶段实体检测性能低的问题,并允许实体信息进一步帮助下游关系分类任务。
- 实体预训练 entity pretraining:预训练实体检测模型。
- 预定抽样 scheduled sampling:在一定概率的情况下用 gold labels 来代替预测的实体标签。
数据集:ACE05 和 ACE04 用于关系提取;SemEval-2010 Task 8 用于关系分类。用 ACE05 和 ACE04 去训练整个模型,用 SemEval-2010 Task 8 去评估关系分类模块。
传统的关系抽取将该任务看作是有两个子任务的 pipeline,两个子任务依次是命名实体识别(NER)和关系分类。
- pipeline 型的关系抽取的两个子模块非常灵活,并且是可以替换的。
- 但是其缺点在于忽略了 NER 与关系分类之间的依赖关系,研究表明 NER 的效果极大程度上的影响了关系分类的效果。除此之外,还会受到错误传播的影响。
端到端的模型(End-to-End,Joint)不同于 pipeline 任务,将两个子任务合并,同时输出实体和其关系。
- joint 的优点在于它通常比 pipeline 的表现更好,因为实体和关系之间存在依赖关系。
模型结构
模型主要分为以下几个部分:
- Sequence Layer:作为 Entity Detection 的低层结构,与 Entity Detection 共享 BiLSTM 的参数。
- Entity Detection:实体检测,产生 entity embedding。
- Dependency Layer:树型 BiLSTM 结构,用于产生 Relation Classification 的输入。
- Relation Classification:关系分类。
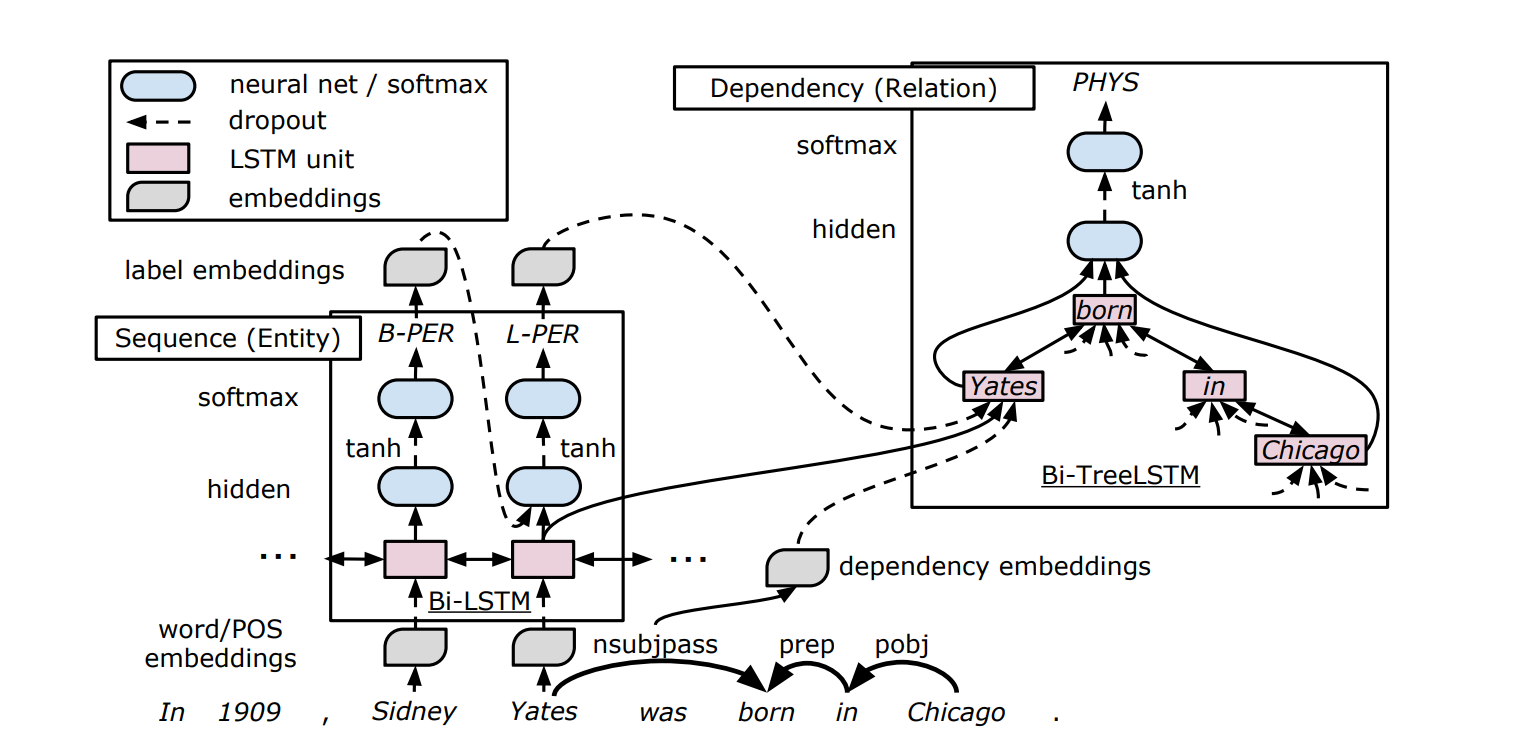
Embedding Layer
使用四种 embedding,v(w)、v(p)、v(d)、v(e),分别代表 word、POS(词性标注)tags、dependency types、entity labels(通过 Entity Detection 学习)。
Sequence Layer
输入为 word 和 POS embedding:
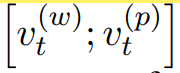
Sequence Layer 的输出 st 为双向 LSTM 输出的拼接:
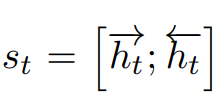
Entity Detection
把实体检测看作是一个序列标注任务,用 BILOU(Begin、Inside、Last、Outside、Unit)进行标注。
将 Entity Detection 放在 Sentence Layer 的上层,所以 Entity Detection 的输入为 Sequence Layer 的输出 st 和 entity embedding。经过一个隐藏层和 softmax 层输出实体标签 yt,这就是 v(e)。
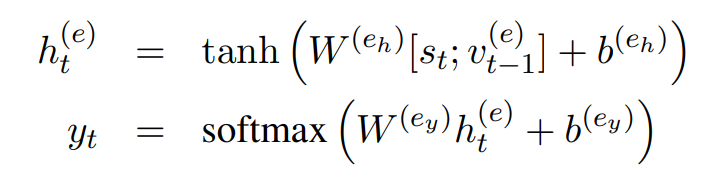
Dependency Layer
针对 Child-Sum Tree-LSTM 与类型无关(参数都是一样的)、N-ary Tree-LSTM 要求固定数量的孩子节点的缺点,论文提出了一种新的 Tree-LSTM。
这种 LSTM 的输入为 sentence layer 的输出 st、依存 embedding、实体类型 embedding(Entity Detection 的输出)这三个向量的拼接:
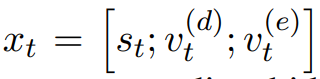
这种新的 Tree-LSTM,对于每种相同类型的孩子共享参数 U,并且允许可变的孩子数量。

在论文中使用了三种树形结构:
- SPTree(Shortest Path):就是两个目标词在依存树中的最短路径。
- SubTree:两个目标词的最低公共祖先的整棵子树。这比 SP-Tree 提供了提供额外的更多信息。
- FullTree:整个依存树,这获取了全部句子的上下文信息。
并且论文还定义了两种节点类型:在最短路径上的节点和其他节点(对于 SP-Tree 只有一种节点类型即在最短路径上的节点,对于其他两种结构则有全部的两种节点类型)。
Relation Classification
实体分类的输入由三个向量构成,分别是两个目标词的最低公共祖先的 Dependency Layer 输出 hpA、两个目标词的 Dependency Layer 输出 hp1 和 hp2:
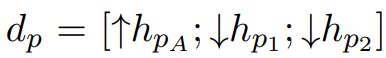
接着输入两层神经网络之中,最后输入 softmax 得到关系分类结果 yp:
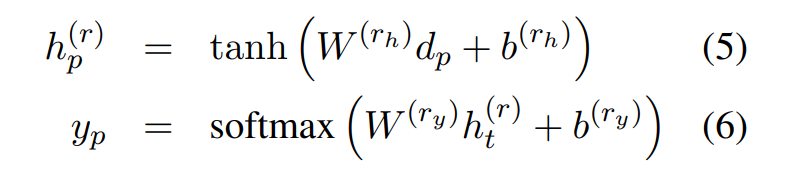
Training
在训练之中,增加了两个功能:
实体预训练 entity pretraining:用训练数据预训练实体检测。
预定抽样 scheduled sampling:在一定概率的情况下用 gold labels 来代替预测的实体标签。概率与第 i 个 epoch 和超参数 k 有关,计算公式如下。其中 k 越大,表示越经常使用 gold labels 作为实体检测的输出。
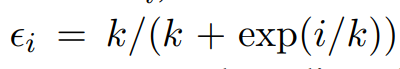
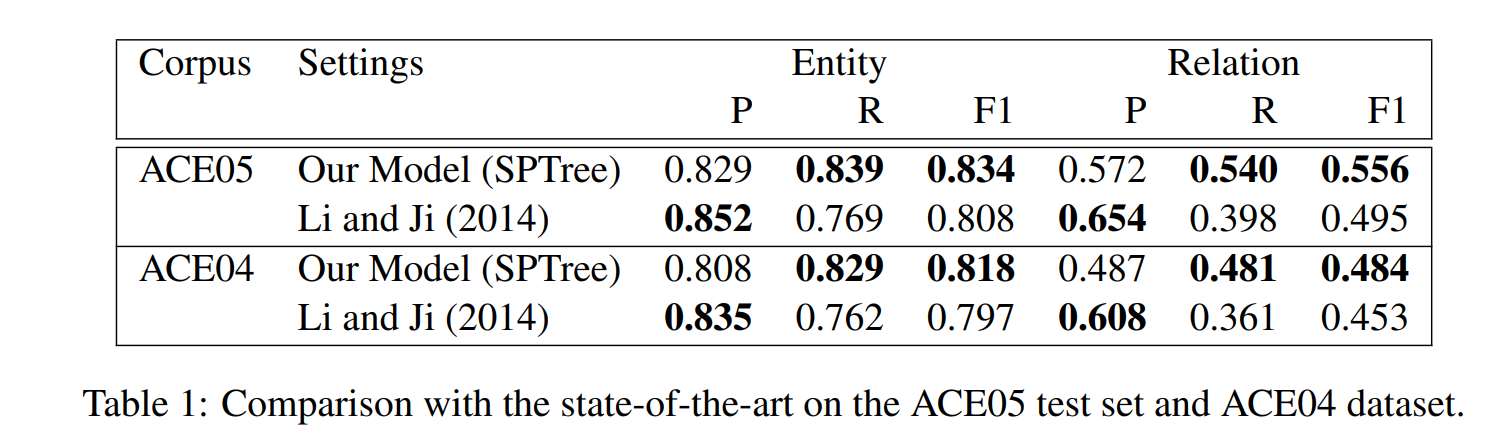
实验结果
比较了论文提出的模型与 state-of-the-art 的基于特征工程的方法,在 ACE05 和 ACE04 上的表现,本文模型效果更好。
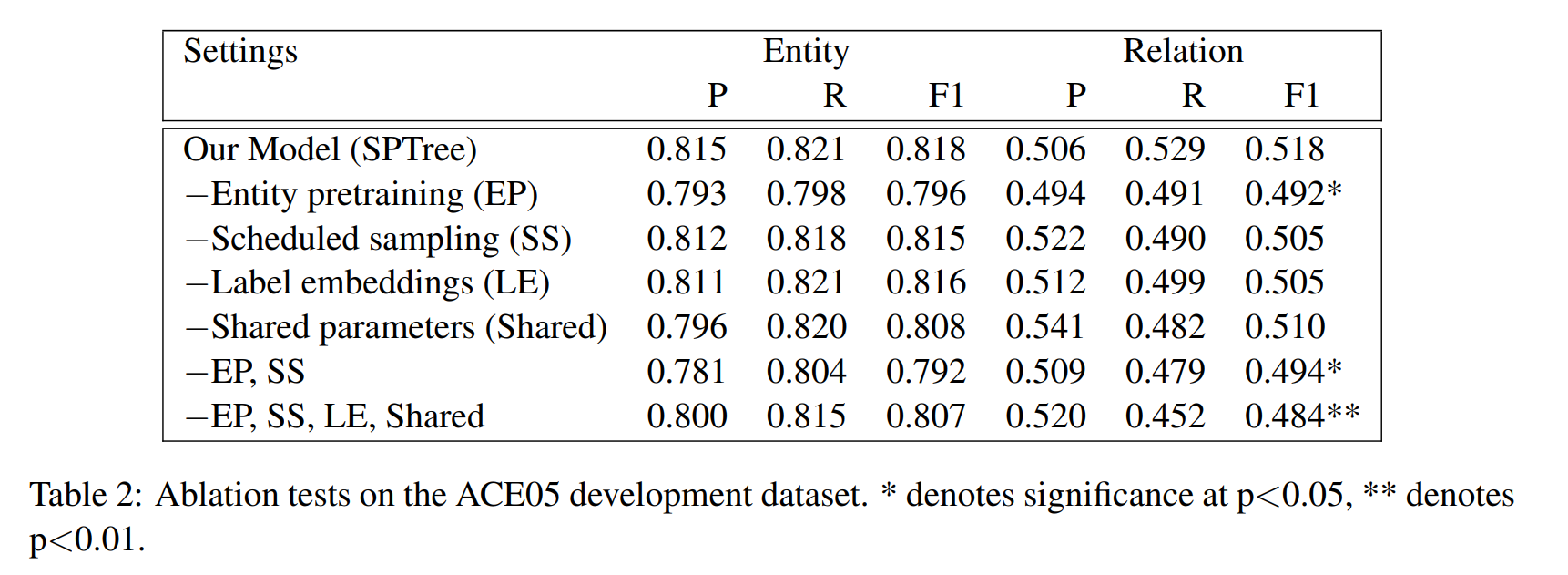
消融实验
为了更好的探究模型中各个组成部分的作用,在 ACE05 数据集上进行了消融实验(Ablation Test)。
- 当去除 Scheduled sampling 时效果轻微的下降,而去除 Entity pretraining 或者二者都去除时效果大幅度下降。因为只有当两个实体被全部正确的发现时,对于 Relation Classification 的训练才是有效果的。如果去除这些增强,可能得到正确实体的时间太晚,导致发现关系的时机太晚。
- 去除 Label embeddings(Entity Detection 的输出,即实体 embedding)后,Relation Classification 的召回率下降较多,说明实体的标签信息对于关系分类有帮助。
- 接着去除 Shared parameters(即 embedding layer 和 sequence layer 被 entity detection 和 relation classification 所共享),方法就是独立的训练 entity detection 和 relation classification,看作是 pipeline 模型。结果就是 entity detection 和 relation classification 的效果均有轻微的下降。
- 移除所有的增强,即 Entity pretraining、Scheduled sampling、Label embedding、Shared parameters,效果显著的降低了。
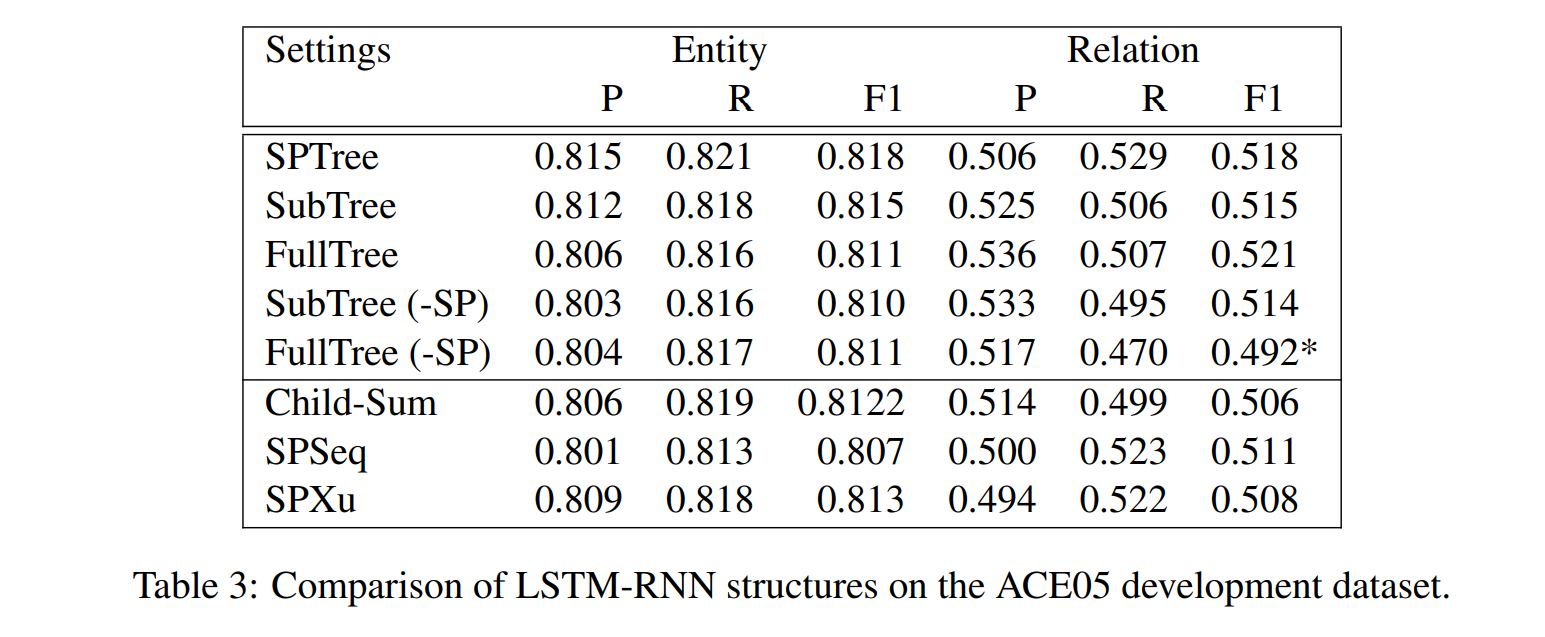
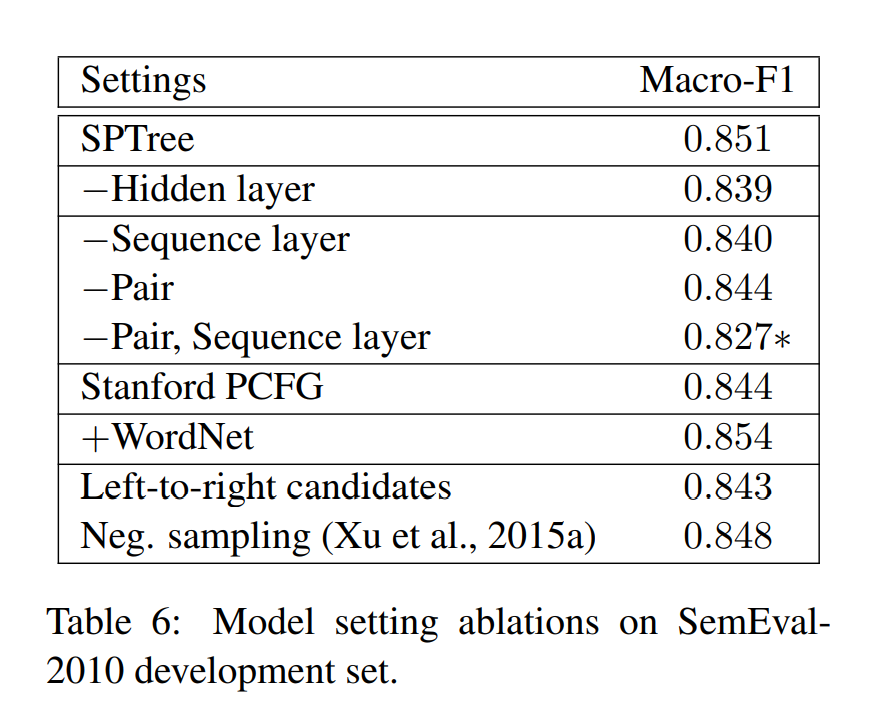
dependency layer 中不同的 LSTM 结构
接着在 dependency layer 中又探究了不同的 LSTM 结构:
- 首先探究三种树型 LSTM(SPTree、SubTree、FullTree):
- 当区分两种节点类型时,即在/不在最短路径上,三种结构的效果类似。
- 当不区分节点类型(-SP)时,即去除了最短路径的信息,FullTree(-SP)的效果显著降低。
- 接着又对比了 Child-Sum Tree-LSTM、SPSeq、SPXu,法相效果相当。
这说明,LSTM 的结构不是重要的影响因素,但是输入的 representation(如最短路径)更为重要。
Relation Classification 的评估
在 SemEval-2010 Task 8 数据集上单独测试 Relation Classification 的效果,各个模型对比如下:
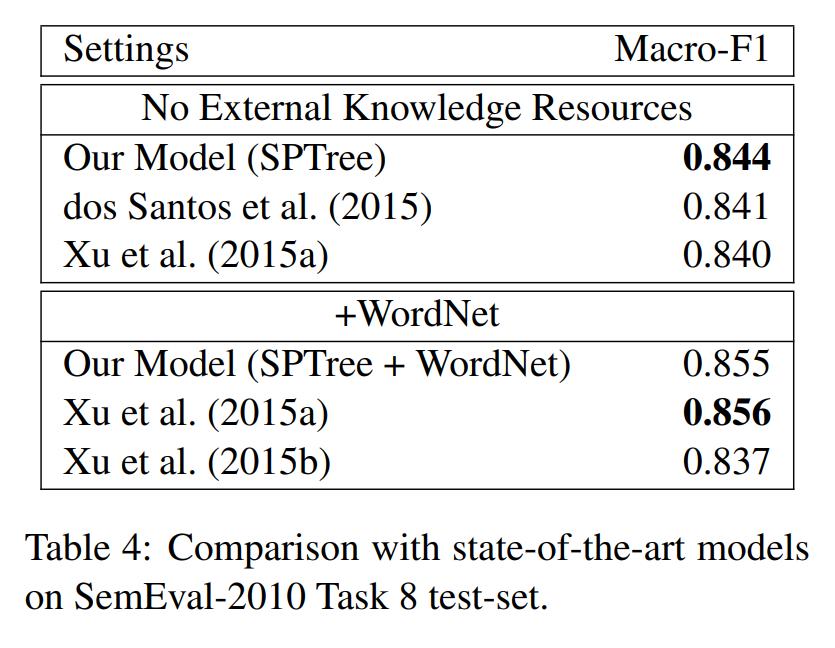
接着比较了在 SemEval-2010 Task 8 数据集上不同 LSTM 结构的效果,值得注意的是 FullTree 和 FullTree(-SP)的效果都不是很好,其他 LSTM 比论文提出的 SPTree 效果略差,但是差别不大。虽然在 ACE05 上的结果不同,但是同样说明,LSTM 的结构不是重要的影响因素,但是输入的 representation(如最短路径)更为重要。
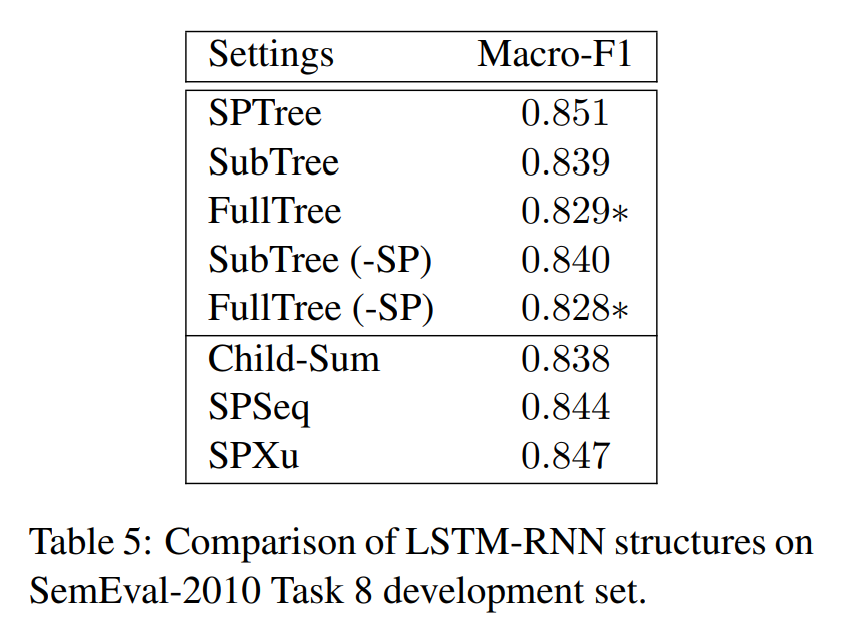
最后,探究了在 SemEval-2010 Task 8 上,Relation Classification 各个组成部分的影响因素:
- 除去 Hidden layer,在 LSTM 后直接接入 softmax 层,结果略微降低。
- 去除 Sequence layer,直接使用 word 和 POS embedding 送入 dependency layer 时;或者去除 entity embedding (-Pair)时,结果只会小幅度降低。但是同时去除二者,结果下降的比较明显。
- 使用 Stanford PCFG parser 来替换 Stanford neural dependency parser 后,结果没什么变化(轻微降低),说明 parsing model 的选择不重要。
结论
综上,有三条重要结论:
- 单词序列(word sequence)和依存树信息(dependency tree)是非常有效果的。
- 共享参数的训练方式,提升了关系抽取的准确度,尤其是应用了 entity pretraining 和 scheduled sampling 时。
- 最短路径信息(已经被广泛应用于关系分类之中),对于树型结构的 LSTM 的 represent 也同样适用。
树状 LSTM
Improved Semantic Representations From Tree-Structured Long Short-Term Memory Networks
论文原文:https://arxiv.org/pdf/1503.00075.pdf
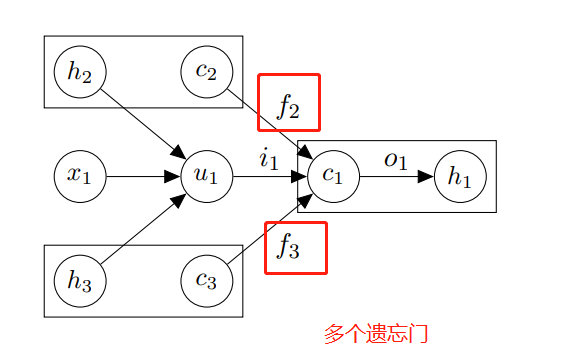
该论文提出了一种新型的 LSTM 结构,称为 Tree-LSTM。
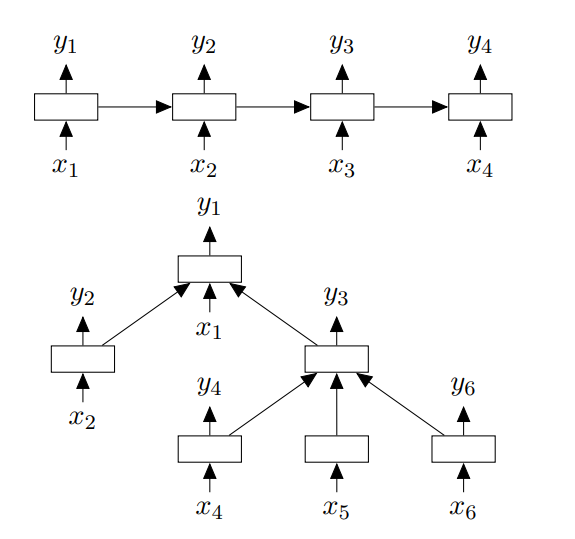
Tree-LSTM 单元
与标准的 LSTM 单元一样,Tree-LSTM 包含输入门 i、输出门 o,一个记忆单元 c 和一个隐藏状态 h。
但是与标准的 LSTM 单元不同的是,Tree-LSTM 单元包含多个遗忘门 f,对应于每一个子单元,均包含一个遗忘门。
两种结构
论文提出了 Tree-LSTM 结构,Child-Sum 和 N-ary。
Child-Sum Tree-LSTM
Child-Sum 的孩子是无序的,所有的孩子共用一个遗忘门参数 U。

N-ary Tree-LSTM
若树的分支数固定为 N,并且孩子是有序的,可以从 1 到 N 进行索引,就可以使用 N-ary。为每个孩子 k 引入单独的遗忘门的参数矩阵 U 用于计算第 k 个孩子的遗忘门。