论文
Attention as Relation: Learning Supervised Multi-head Self-Attention for Relation Extraction
发布年份:2020
会议:IJCAI
作者:Jie Liu, Shaowei Chen, Bingquan Wang, Jiaxin Zhang, Na Li, Tong Xu
机构:College of Artificial Intelligence, Nankai University
贡献:
- 提出了一个 supervised attention-based 的联合关系抽取模型,用于解决 overlapping 关系三元组问题。
- 为了充分捕捉独特的关联语义,分别学习不同关系类型下的关联强度(每一个关系类型都是单独的子空间),将关系检测转化为一个多标签分类任务,并设计了一个监督的多头自注意机制。
数据集:在测试集中随机选择 10% 作为验证集。
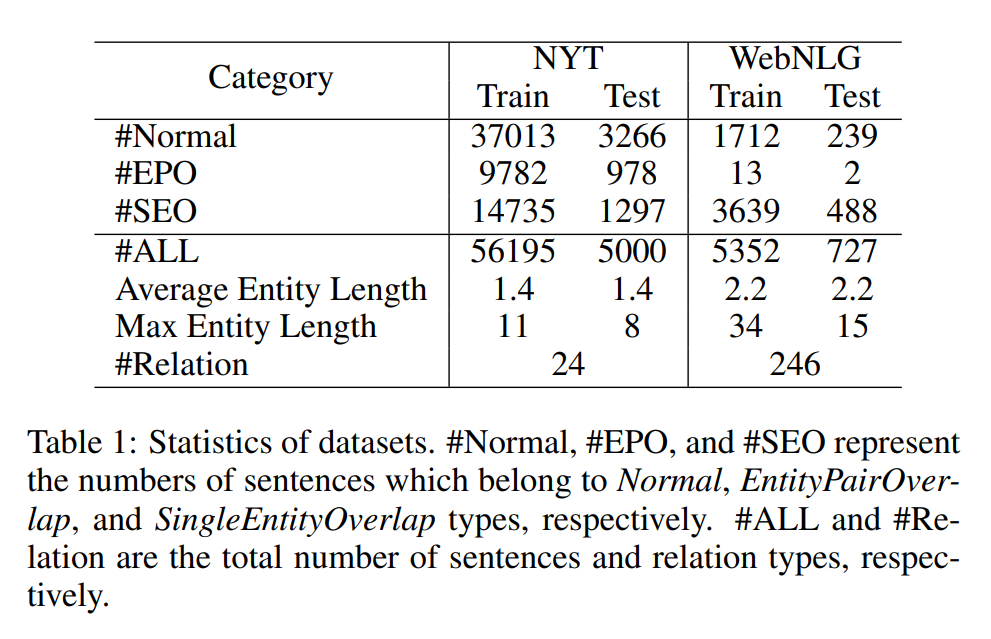
- NYT(New York Times),包含 24 种关系类型。
- WebNLG:包含 246 种关系类型。
目前来说,实体关系联合抽取模型还面临着许多问题。提出的基于多头注意力机制的联合抽取模型就是为了解决这些问题。
- 识别重叠的关系三元组(identify overlapping relation triplets):overlapping 可以分为两种子类型,之前的联合关系抽取模型无法解决 overlapping 问题。
- EntityPairOverlap(EPO):两个实体有多种关系。
- SingleEntityOverlap(SEO):两个关系三元组共同享一个实体。
- 在不同的关系类型中,实体语义可能会发生变化。
- 在 EPO 问题中,传统的联合抽取模型将所有关系类型的可能性都放在同一个可能性空间中,这很难去同一对实体的多种关系。
NYT 和 WebNLG 的统计数据如下:
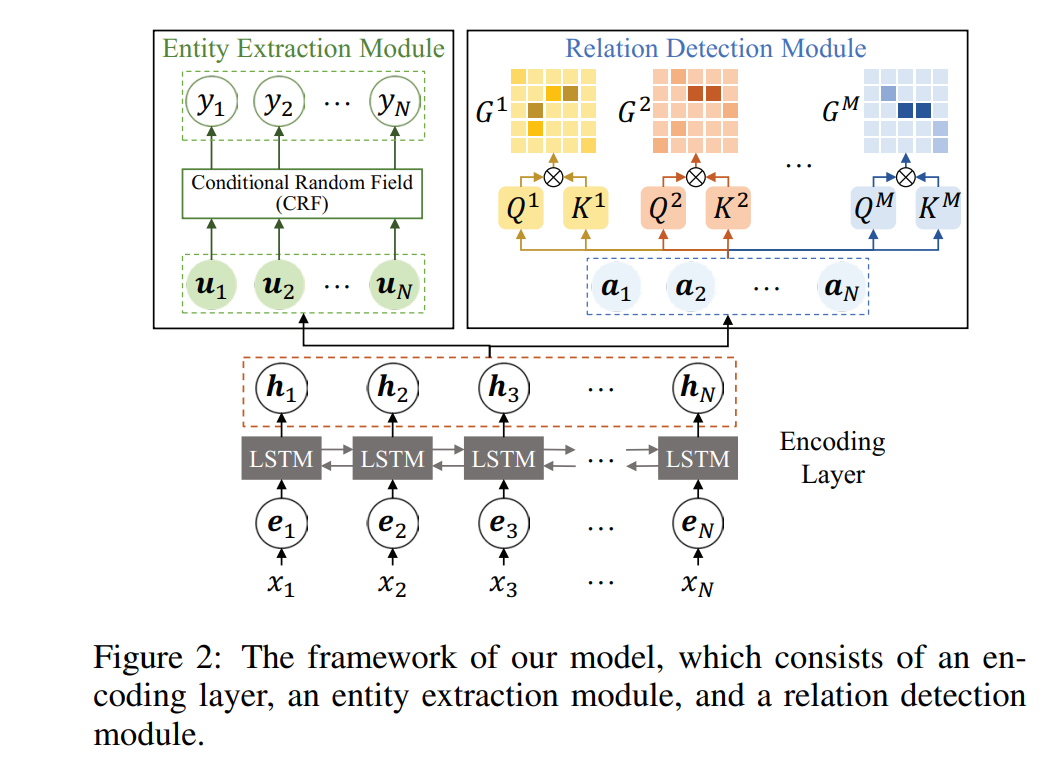
模型结构
模型由三个部分组成:
- Encoding Layer:采用 BiLSTM 作为 encoder。
- Entity Extraction Module:采用 CRF 去识别实体。
- Relation Detection Module:设计了一种 supervised multi-head self-attention 机制,用于得到两个 token 之间的关系类型(解决 overlapping 问题)。
Entity Extraction Module
将实体识别看作是序列标注任务,采用 CRF 实现。用 BIO(Begin、Inside、Others)标签,进行序列标注。
P 为发射矩阵,用于表示 token 到 label 的映射。V 为转移矩阵,用于表示相邻标签之间的依赖关系。 对于一个预测的标签序列:
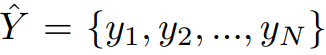
定义它的分数如下所示,其中 U 为 BiLSTM 的输出 H 进入一个全连接层的输出 U= {u1, u2, ..., uN}。
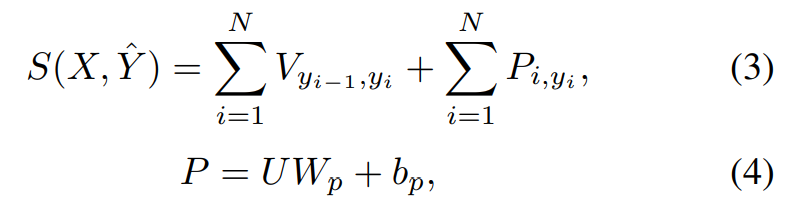
预测标签的可能性可以用以下方式进行计算:
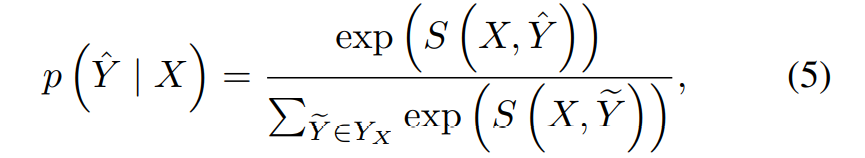
所以我们需要最大化这个可能性,所以加上负号,由这个可能性是趋近于 1 的,所以再加上 log,使之趋近于 0。于是,实体识别的损失函数定义如下:
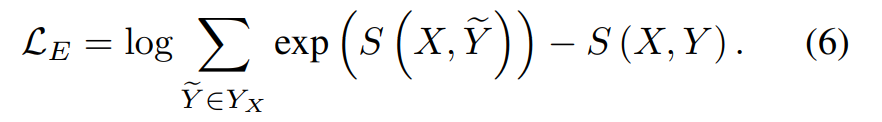
Relation Detection Module
将关系分类看作是多标签(multi-label classification task)任务,而不是多分类任务。利用 supervised multi-head self-attention 机制将每一种关系类型划分到不同的子空间中。
首先将 BiLSTM 的输出 H 送入一个线性隐藏层中,得到隐藏层输出 A = {a1, a2, ..., aN}。通过共享一个线性隐藏层,可以捕捉到不同关系类型之间的交互关系。
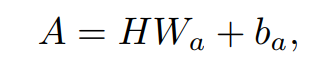
不同的类型有不同的参数矩阵 W,m 表示第 m 种关系类型(这里体现了 multi-head)。计算 key 和 query 矩阵如下:
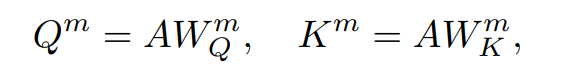
attention 矩阵 G 的计算方式如下,G 的第 i 行第 j 列元素代表第 i 个 token 与第 j 个 token 在第 m 种关系类型中的关联强度:
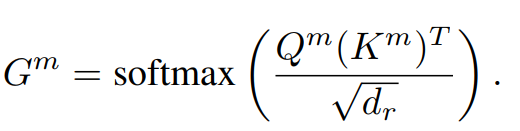
在给定输入 X 的情况下,输出 Z 的可能性计算方式如下。其中 Z_m_i_j = 1 表示在第 i 个 token 和第 j 个 token 之间有第 m 中关系类型,反之亦然。
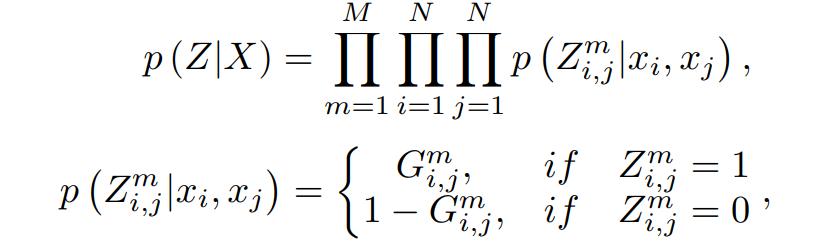
Relation Detection 的损失函数(使用了 Cross-entropy Loss)如下:
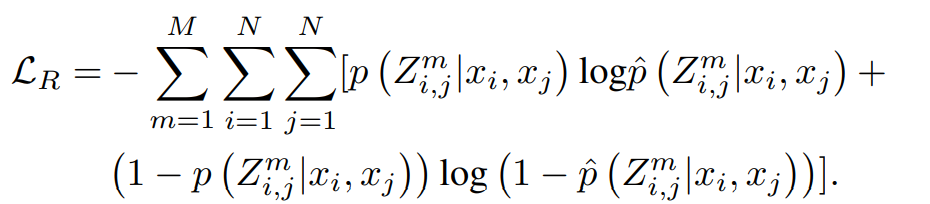
第 i 个实体和第 j 个实体,都是由多个 token 组成。
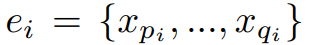
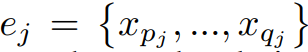
第 i 个实体和第 j 个实体关于第 m 个关系类型的关联强度计算公式如下,其中 |ei| 表示第 i 个实体的长度。当这个强度大于一个给定的阈值时,关系三元组就会被抽取出来。
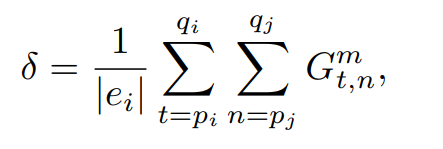
Joint Learning
为了使两个子模块同时学习,定义整个的损失函数为两个子模块的损失函数之和:
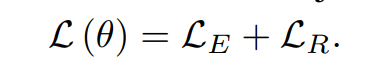
再训练时,采用迭代式的两步训练方法(iterative two-step training manner),即第一次训练模型中的所有参数,第二次只训练 relation extraction 和 encoding layer 中的参数。
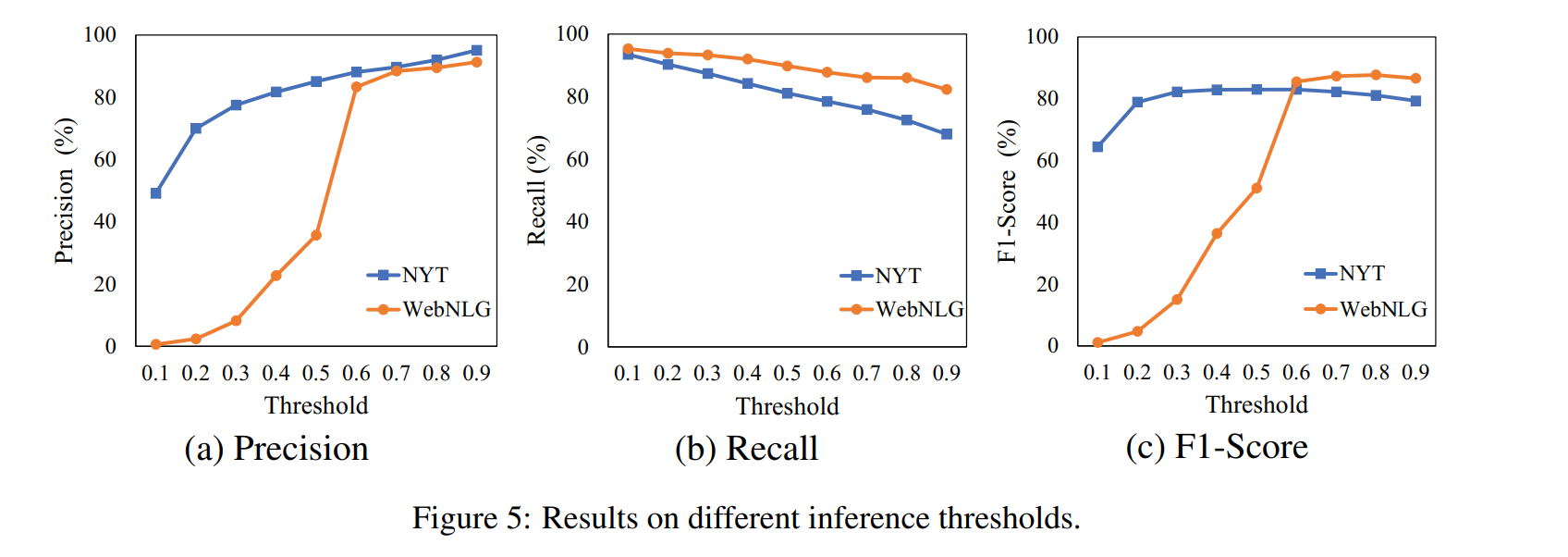
实验结果
模型对比
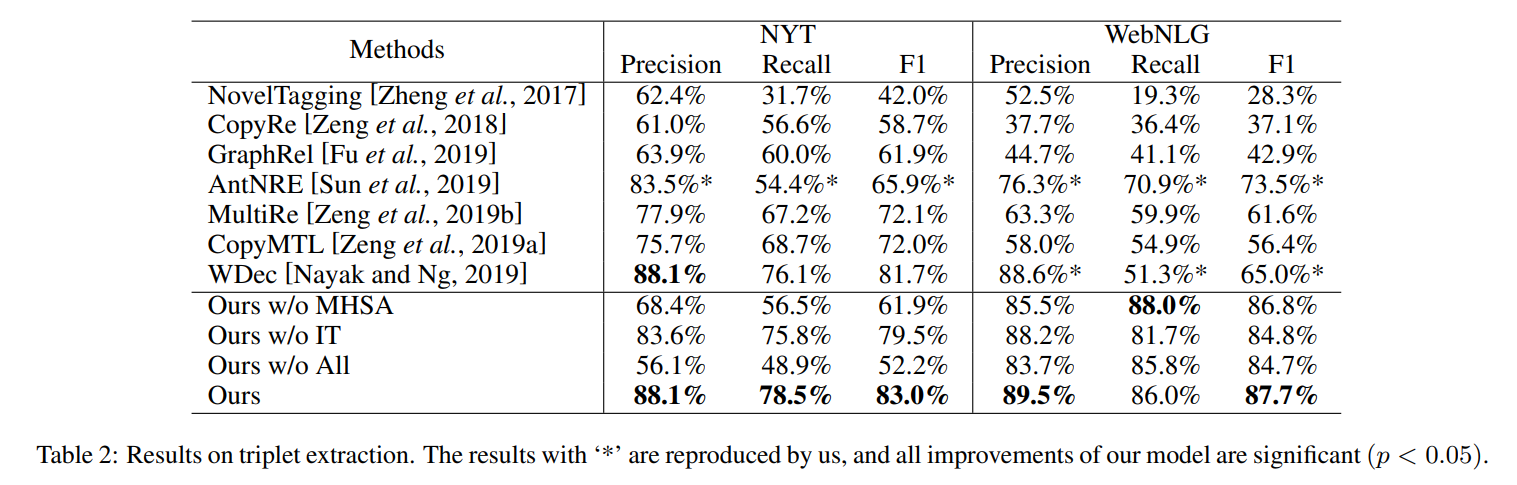
与其他模型的对比如下,其中 Ours w/o MHSA 代表在 detect relation 时使用了标准的多分类(而不是多标签,即没有使用 multi-head self-attention 机制),Our w/o IT 表示没有使用 iterative two-step 的训练方法,Ours w/o ALL 表示没有使用多标签以及 iterative two-step 训练方法。
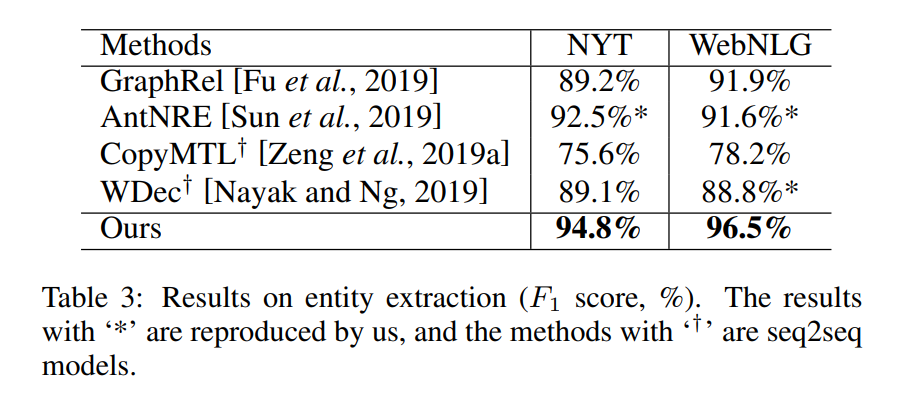
还与其他模型比较了 entity extraction 的效果:
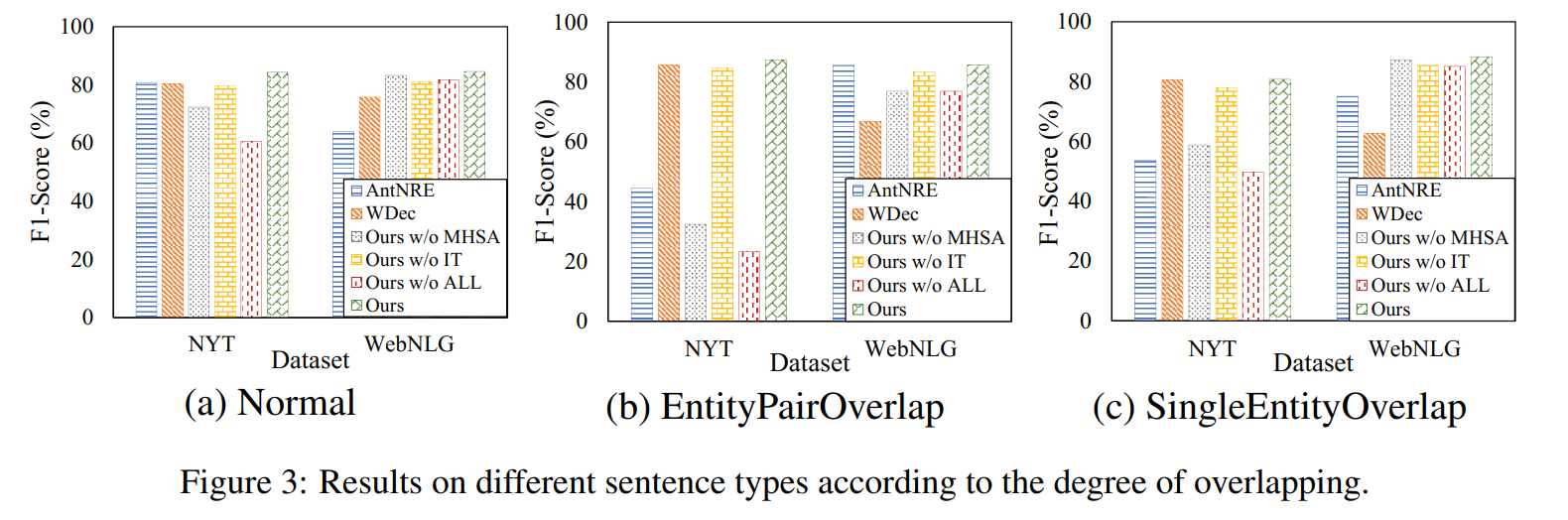
消融实验
- Ours w/o MHSA(去除了 multi-head self-attention)在NYT 数据集上表现大幅度下降,但是在 WebNLG 数据集上只有轻微的下降。这是因为 NYT 数据集上的 overlapping 关系三元组多得多,说明 supervised multi-head self-attention 机制可以很好的识别 overlapping 三元组。
- Ours w/o IT(去除 iterative two-step 训练方法)在两个数据集上的表现分别下降了 3.5% 和 2.9%,说明 entity extraction 和 relation detection 的不平衡影响了联合关系抽取的表现。

Analysis of Different Sentence Types
在 EPO 和 SEO 问题中,论文提出的模型表现最好,但是 Ours w/o MHSA 和 Ours w/o ALL 表现最差,说明多分类很难解决关系三元组中的 overlapping 问题。
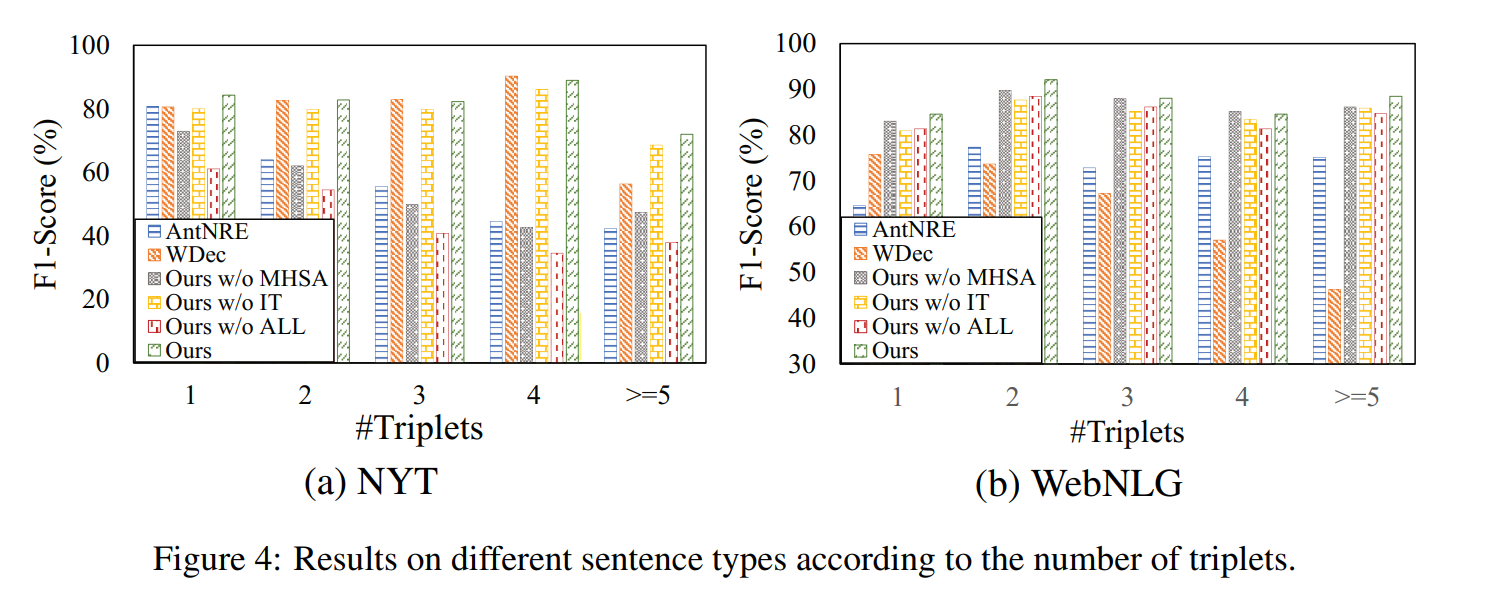
将句子分为 5 类,分别是一句话中只有一组关系、两组关系、三组关系、四组关系、五组及以上关系。从途中可以看到,在一句话中有多个关系时,模型的表现比较稳定。说明在面对复杂关系情形时,模型鲁棒性很好。
relation extraction 中阈值的分析