BERT-Based Multi-Head Selection for Joint Entity-Relation Extraction
来源:2019 年语言与智能竞赛信息抽取任务
年份:2019
作者:Weipeng Huang, Xingyi Cheng, Taifeng Wang, Wei Chu
机构:Ant Financial Services Group
贡献:
- 使用 BERT 代替 BiLSTM 作为特征提取层,并且使用 semantic-enhanced task 优化 BERT 的预训练。
- 使用 Baidu Baike corpus 进行实体识别的预训练,以一种弱监督的方式。
- Soft label embedding 用于表示实体类型信息。
实体识别有助于关系分类,关系分类也有助于实体识别。
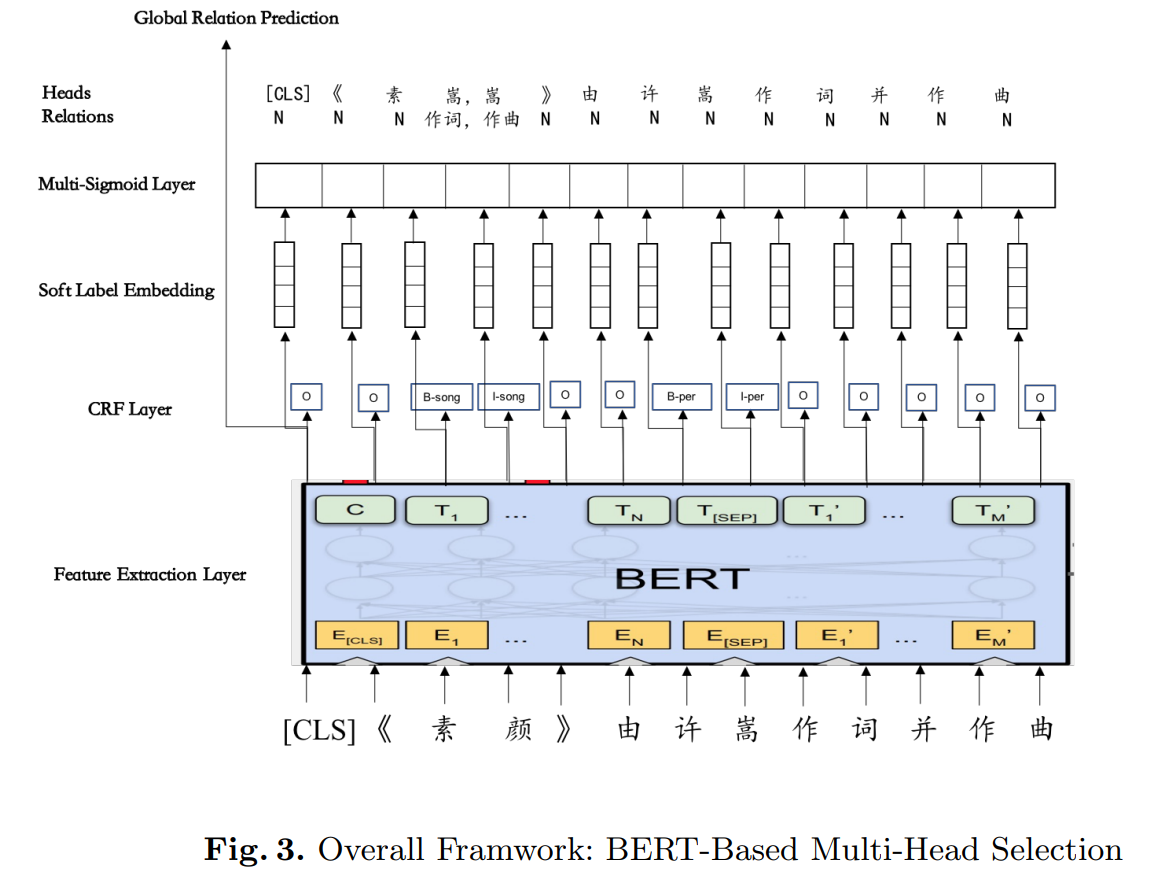
模型结构
- 模型使用 BERT 来获取上下文特征。
- CRF 层用于抽取实体。
- CRF 的最上面输出了软标签向量(soft label embedding),用于传递实体信息。
- 应用了 multi-sigmoid layer 去解决一个实体属于多个关系三元组的问题。
Feature Extraction Layer
使用 BERT 而不是 BiLSTM 来提取特征,并且使用了一种 semantic-enhanced 任务去优化 BERT 的预训练过程。
原始的 BERT 使用两个无监督任务去训练 BERT,分别是 masked language model(MLM)和 next sentence prediction(NSP)。MLM 可以使得模型捕获到分布式的上下文信息,NSP 可以使得模型可能理解到句子对之间的关系。
文章提出的 语义增强任务包含了:前一句预测(previous sentence prediction)和文档级预测(document level prediction)。联合使用了 MLM、NSP 和 semantic-enhanced 来预训练 BERT。
CRF Layer
使用 CRF 来进行实体识别,标注采用 BIO 的方式(标签为 B-type,I-type 和 O)。
使用了 Baidu Baike corpus(大约六百万个句子)去预训练 CRF,每一个样本包括一个标题和内容,文章将每一个样本的标题作为一个虚假的实体,让 CRF 在内容中去识别标题。

Soft Label Embedding
以前的工作都是使用了 entity embedding 作为关系分类的输入,这样的方式是一种硬标签(hard label)的方式,也就是说,entity embedding 完全取决于实体类型,这可能导致错误传播,如果 CRF 的结果错误了那么会导致模型的效果变差。
所以论文采用了软标签(soft label)的方式,即使用每一种实体类型的可能性作为关系分类的输入。N 为实体类型的数量,M 为 label embedding matrix,则第 i 个字符的软标签 embedding 如下:
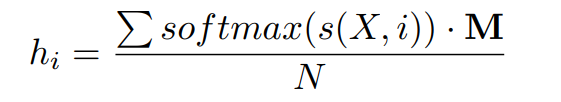
Multi-sigmoid Layer
将 soft label embedding 分别送入两个全连接层,得到作为 subject 和 object 的表示。对于第 i 个 token 和第 j 个 token:
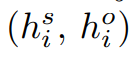
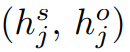
使用 multi-sigmoid 进行预测,预测出的关系如下,其中 f 代表神经网络(全连接 + sigmoid):
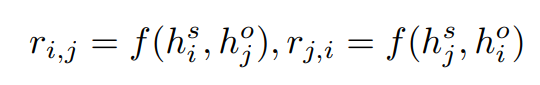
Global Relation Prediction:[CLS] 的 BERT hidden state 用于表示整个句子,将这个 hidden state 送入 multi-sigmoid 中进行关系分类。
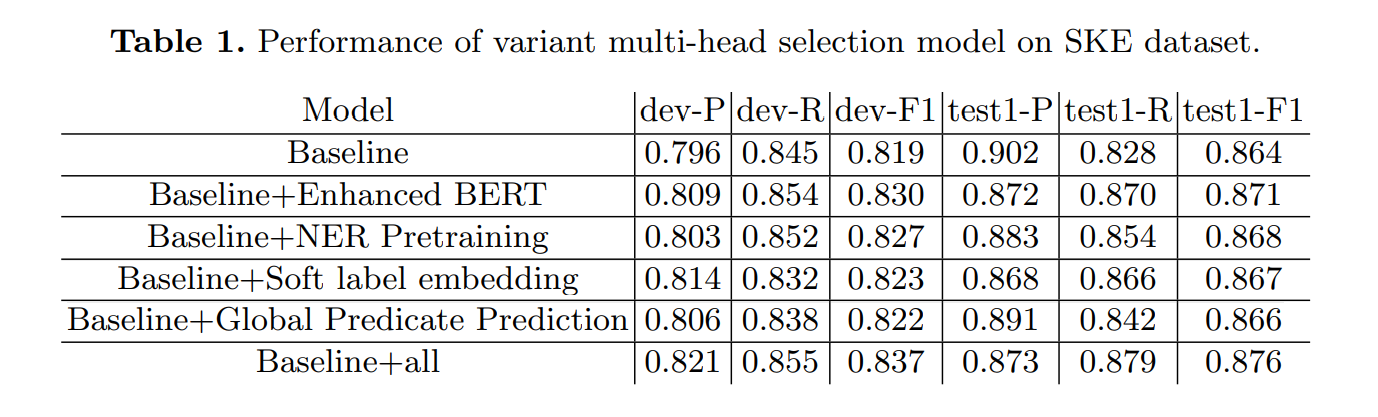
实验结果