TPLinker: Single-stage Joint Extraction of Entities and Relations Through Token Pair Linking
会议:COLING
年份:2020
作者:Yucheng Wang, Bowen Yu, Yueyang Zhang, Tingwen Liu, Hongsong Zhu, Limin Sun
机构:Institute of Information Engineering, Chinese Academy of Sciences
贡献:
- 提出了一种一阶段的联合抽取方法,可以解决 overlapping 问题(也可以解决嵌套实体的问题)和 exposure bias 问题。将联合抽取问题转化为 token pair 的链接问题。
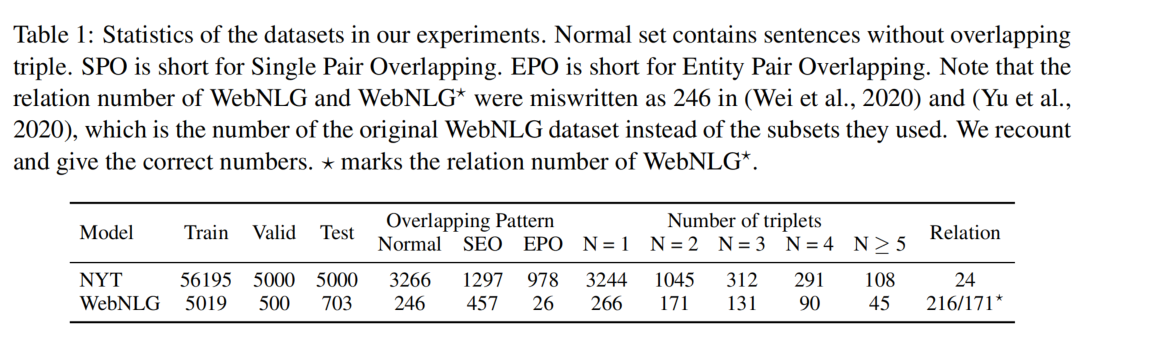
数据集:NYT 和 WebNLG
github: https://github.com/131250208/TPlinker-joint-extraction
目前处理 EntityPairOverlap(EPO)和SingleEntityOverlap(SEO)问题的模型可以分为两类:
- decoder-based(基于解码器的):采用 encoder-decoder 架构,decoder 每次提取一个关系三元组或者一个词。
- decomposition-based(基于分解的):首先提取出可能的候选 subject,然后为每个 subject 提取出对应的 object 和关系。
这些方法都有一个相同的问题:exposure bias,原指在 RNN 中的一种偏差,在训练时接受的标签是真实的值,但是在测试时却接受自己前一个单元的输出作为本单元的输入,这两者的不一致会导致误差累积。
exposure bias,暴露偏差:
在decoder-based 的方法中,在训练时,ground truth token 被用作上下文,而在预测时,整个序列是由所产生的模型自行生成的,因此,由模型生成的之前的 token 被作为上下文输入。(解码器需要一个递归译码过程)
在 decomposition-based 的方法中,在训练时使用 gold subject entity 作为输入去提取特定的 object 和关系;而在预测时,subject 由模型自己给出。
论文将联合抽取任务转化成了一种 token pair 的链接任务,对于两个位置 p1 和 p2,以及一个给定的关系 r,TPLinker 回答三个问题:
- p1 和 p2 是同一个实体的开始位置和结束位置吗?
- p1 和 p2 是两个具有关系 r 的实体的开始位置吗?
- p1 和 p2 是两个具有关系 r 的实体的结束位置吗?
设计了一个 handshaking tagging scheme,为每个关系标注三个 token link matrices(这三个矩阵用于解码不同的标记结果,用来解决 overlapping 问题),以回答上面的三个问题。TPLinker 不包含任何相互依赖的提取步骤,所以可以避免 exposure bias。
模型结构
模型的结构如下,可以划分为两个部分:
- 下方绿色的部分是 Token Pair Representation
- 上方橘色部分是 Handshaking Tagger
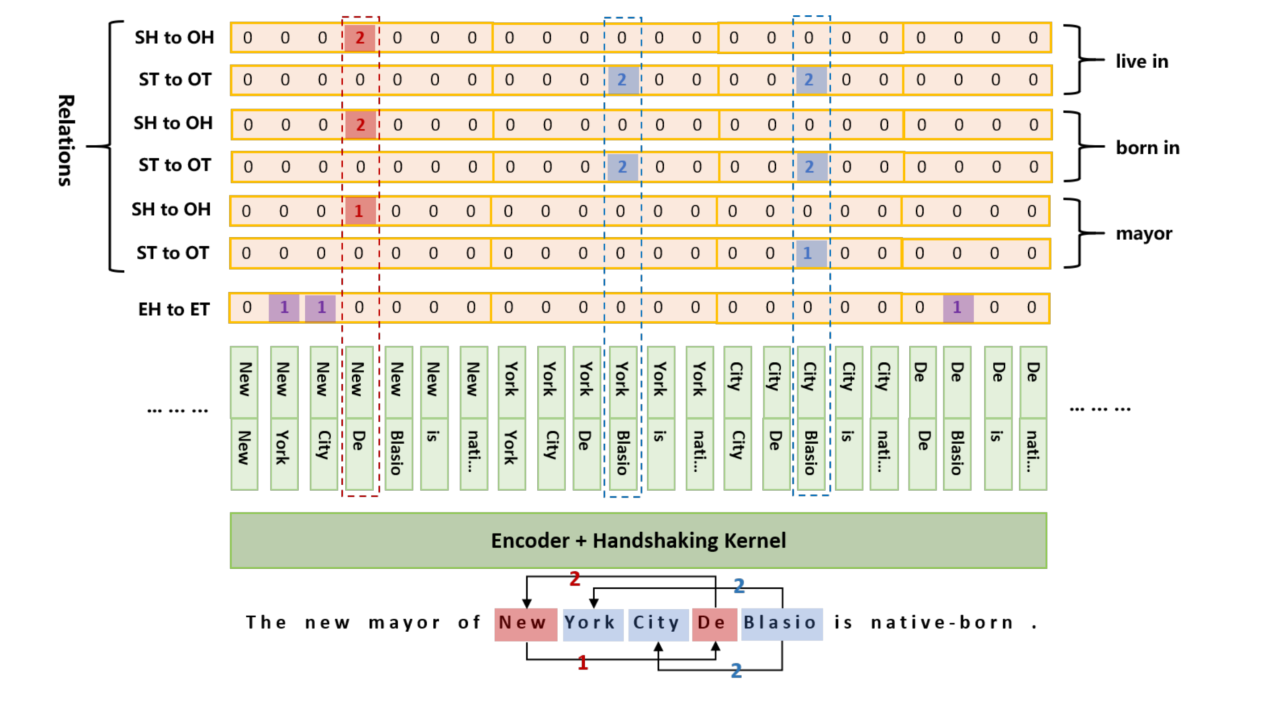
Handshaking Tagging Scheme
首先说明 handshaking 标注方法。
Tagging
如下图所示,给定一个句子,枚举了所有可能的 token pair,并且使用矩阵来标记 token links。links 有三个种类:
- entity head to entity tail(EH-to-ET)
- subject head to object head(SH-to-OH)
- subject tail to object tail(ST-to-OT)
对于 EH-to-ET 而言,一个实体的尾部一定在头部之后,所以矩阵的下三角区域全部为 0,可以直接删除矩阵的下三角区域只保留上三角区域。对于 SH-to-OH 和 ST-to-OT 而言,object 的位置是可能在 subject 之前的,所以将下三角区域的1 映射到上三角区域中,并且将 1 变为 2 以表示这是 object 指向 subject。在实际操作中,将每个矩阵的上三角部分展开成一个一维向量。
这个方法可以解决 SEO 问题和实体嵌套问题,但是还不能解决 EPO 问题,为了解决 EPO 问题,为每一种关系类型都标注两个矩阵(SH-to-OH 和 ST-to-OT)。注意,EH-to-ET 是被所有关系所共享的,因为这个矩阵只考虑了所有的实体而没有考虑特定的关系。所以,联合关系抽取任务被分解为 2N+1 个序列标记子任务,其中 N 表示预定义关系类型的数量。每一个序列标注子任务的序列长度为 1+2+...+n = (n^2+n)/2,n 是输入句子的长度。
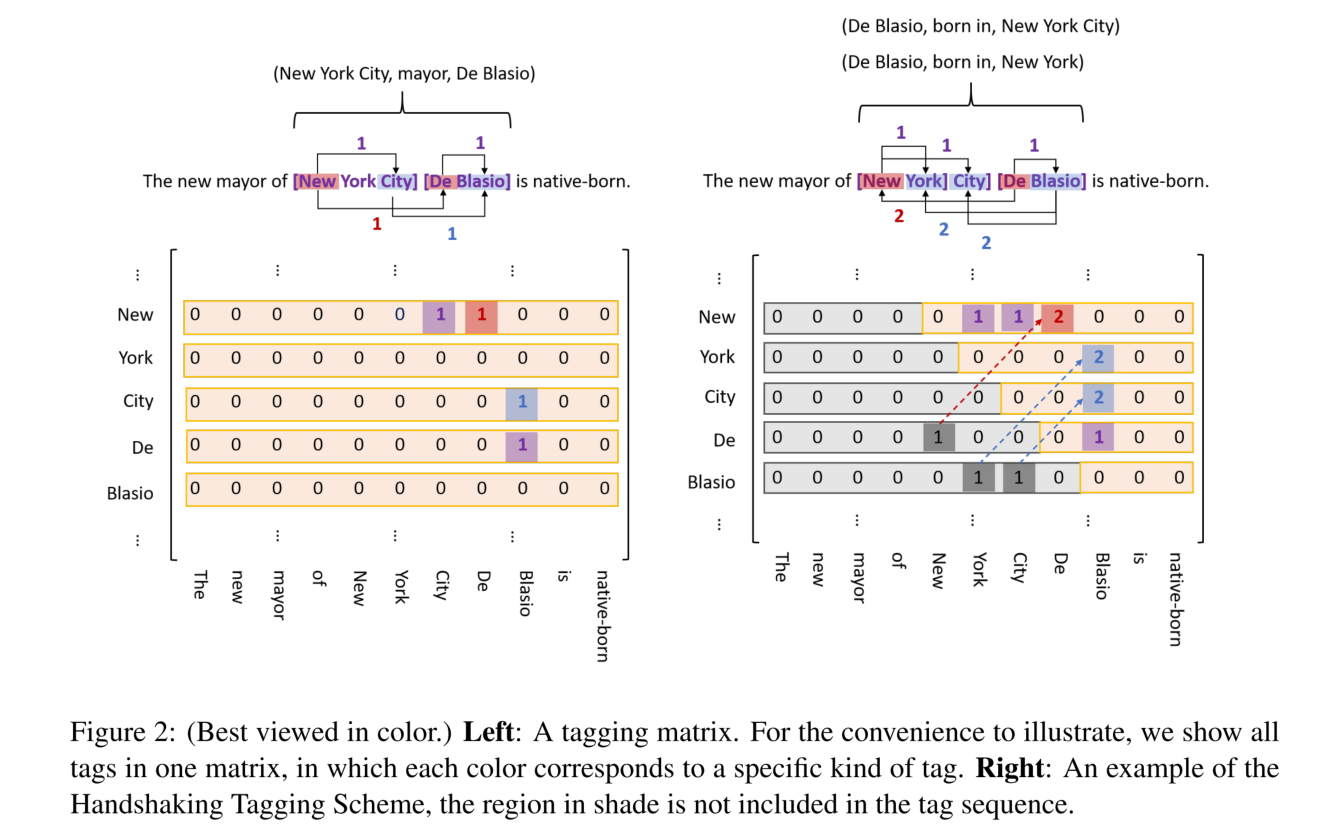
Decoding
解码过程如下:
- 首先,从 EH-to-ET 序列中提取所有的 entity span,并且用一个字典 D 将每一个头部位置映射到从这个头部位置开始的响应实体。
- 然后,对于每一种关系:
- 首先从 ST-to-OT 序列中解码出(subject 的尾部位置,object 的尾部位置)这样的元组,将元组添加到集合 E 中。
- 接着从 SH-to-OH 序列中解码出(subject 的头部位置,object 的头部位置)这样的元组,在 D 中查询所有的以头部位置开始的所有可能的实体。
- 遍历所有的 subject-object pair,以检查它们的尾部位置是否在 E 中。如果是,则提取一个新的三元组并添加到结果集合 T 中。

Token Pair Representation
给定一个长度为 n 的句子,通过一个 encoder 将每个 token 转为上下文向量 hi,然后可以为 token pair 生成一个表示:
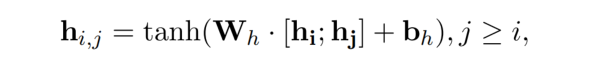
上式也就是模型结构图中的 Handshaking Kernel。
Handshaking Tagger
利用一个统一的结构去标记 EH-to-ET,SH-to-OH 和 ST-to-OT:
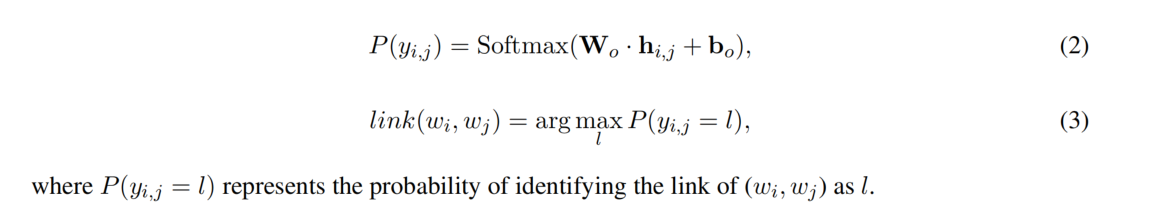
损失函数
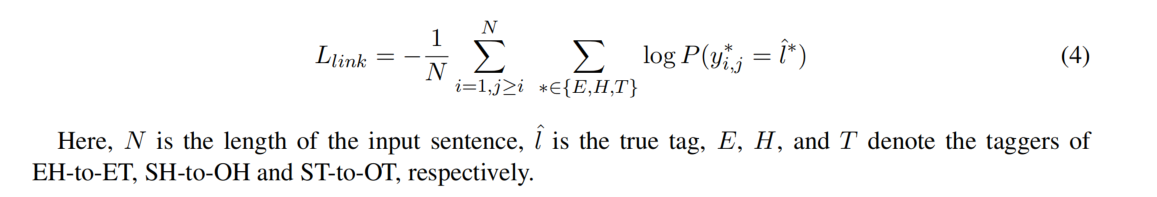
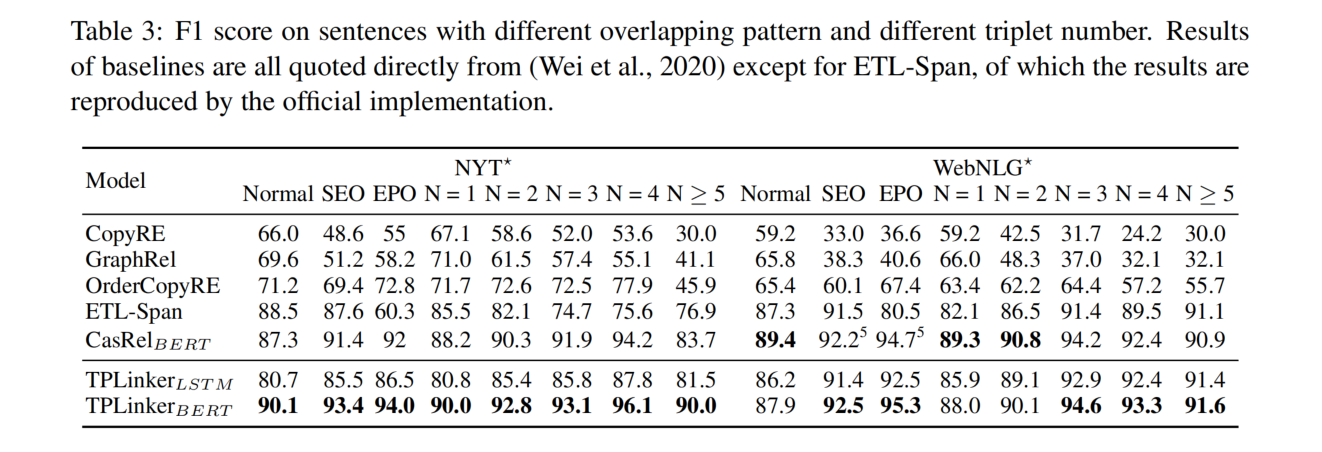
实验结果
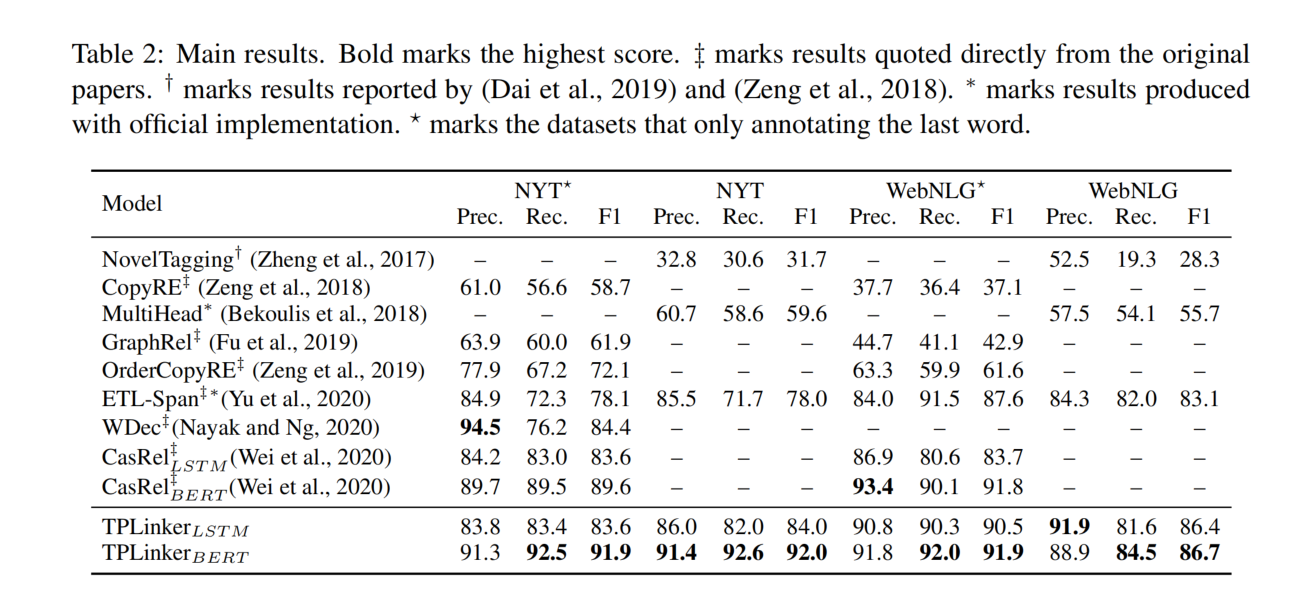
NYT 和 WebNLG 有两个版本的标注标准:1)对实体的最后一个单词进行标注 2)对整个实体的 span 进行标注。为了进行公平的比较,在这两种设置下都评估了模型,第一种版本记为*。
NYT 和 WebNLG 数据集的统计数据如下:
各模型的比较
不同句子类别的比较