Entity-Relation Extraction as Multi-turn Question Answering
会议:ACL
年份:2019
作者:Xiaoya Li, Fan Yin, Zijun Sun, Xiayu Li, Arianna Yuan, Duo Chai, Mingxin Zhou, Jiwei Li
机构:Shannon.AI Computer Science Department, Stanford University
数据集:ACE 04、ACE 05 和 CoNLL04。并且构建了一个新的数据集 RESUME。
- ACE 04 :
- 定义了 7 种实体类型:Person(PER)、Organization(ORG)、Geographical Entities(GPE)、Location(loc)、Facility(FAC)、Weapon(WEA)和 Vehicle(VEH)。
- 定义了 7 种关系类型:Physica(PHYS)、Person-Social(PER-SOC)、Employment-Organization(EMP-ORG)、Agent-Artifact(ART)、PER/ORG Affiliation(OTHER-AFF)、GPE-Affiliation(GPE-AFF)和 Discourse(DISC)
- ACE 05:
- 保留了 PER-SOC、ART 和 GPE-AFF 类别,将 PHYS 分为了 PHYS 和一个新的类别 PART-WHOLE,删除了类别 DISC,将 EMP-ORG 和 OTHER-AFF 合并为了一个新的类别 EMP-ORG。
- CoNLL04:
- 定义了 4 种实体:LOC、ORG、PER 和 OTHERS
- 5 种关系类别:LOCATED IN、WORK FOR、ORGBASED IN、LIVE IN、KILL
贡献:
- 将实体关系联合抽取任务转换为多轮次的 QA 任务,即从上下文中识别答案范围。
- 构建了一个新开发的中文 RESUME 数据集简历,它需要多步推理来构建实体依赖,而不是在以前的数据集的三元组提取中进行单步依赖提取。
RESUME 数据集
ACE 和 CoNLL04数据集基于关系三元组的提取,两轮 QA 就可以提取三元组:第一轮用于提取头实体,第二轮用于提取尾实体和关系。这些数据集不涉及层次的实体关系。
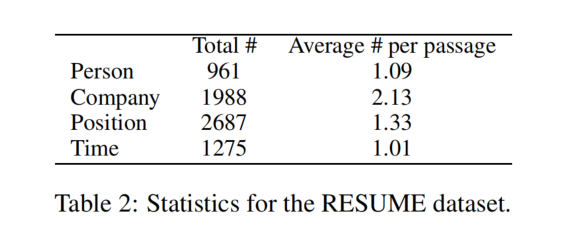
因此,论文中构建了一个新的数据集 RESUME,从 IPO(指首次公开募股)招股说明书中描述管理团队的章节中提取了 841 个文档。每一个文档都描述了一些主管的工作历史,并从简历中提取结构性数据。该数据集是用中文表示的。
定义了 4 种类型的实体:Person、Company、Position、Time。值得注意的是,一个人可以在不同的时间在不同的公司工作,一个人可以在不同的时间在同一公司担任不同的职位。将所有数据以(人,公司,时间,职位)进行组织,表示一个人在某事件某公司担任某职位:
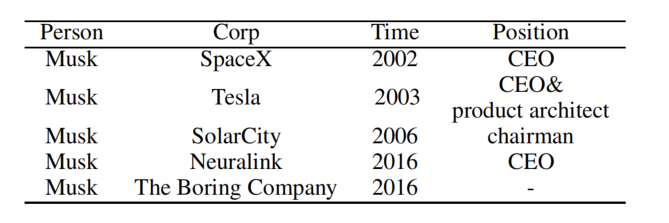
RESUME 数据集的统计数据如下:
模型结构
算法分为两个阶段:
- 头实体提取阶段(4 - 9 行):为了提取头实体,使用 EntityQuesTemplates(line 4)将实体类别转化为一个问题,并通过回答这个问题(line 5)提取实体 e(若答案是 None,则说明不包含该类型的任何实体)。
- 关系和尾实体提取阶段(10 - 24 行):ChainOfRelTemplates 定义了一个关系链,需要遵循它的顺序来运行多轮次的 QA(因为一些实体的提取依赖于其他实体的提取,比如在 RESUME 数据集中,高管所担任的职位依赖于他所工作的公司,时间实体的提取也依赖于公司和职位的提取。)。提取的顺序是人为预先定义的。ChainOfRelTemplates 还定义了每一种关系的模板,每个模板都包含一些要填充的插槽。为了生成一个问题(line 14),我们将先前提取的实体插入到模板中的插槽中。通过回答生成的问题(line 15)共同提取 REL 和尾部实体 e。
值得注意的是,从头实体提取阶段提取的实体可能不都是头实体。如果从第一阶段提取的一个实体 e 确实是一个关系的头实体,那么 QA 模型将通过回答相应的问题来提取该尾部实体。否则,答案将是 None,因此这个错误的头实体会被忽略。

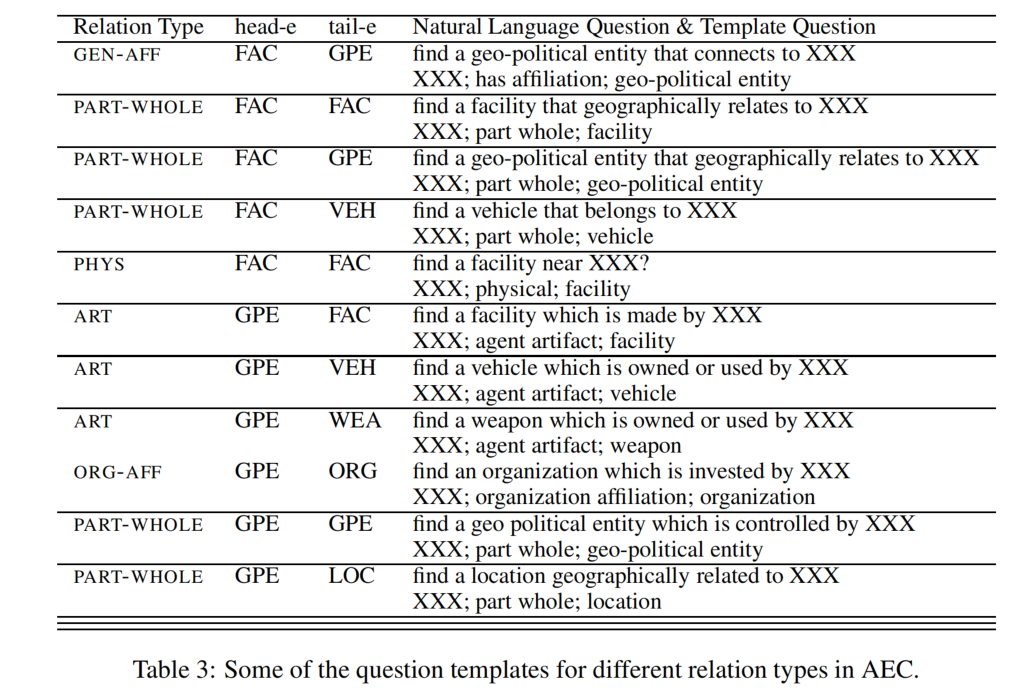
Generating Question using Templates
每一种实体类型都与一个通过模板生成的特定的问题相关联。有两种方式去基于模板生成问题:
- 自然语言问题(natural language questions):如
Which facility is mentioned in the text - 伪问题(pseudo-question):语法不是必要的,如
entity: facility
在关系和尾实体联合提取阶段,将关系特定的模板与提取的头实体相结合,生成一个问题。这个问题可以是自然语言问题,也可以是伪问题。

Extracting Answer Spans via MRC
对于标准的 MRC,给定一个问题 Q 和一个上下文 C,需要预测出答案的 span。此论文使用 BERT 作为 QA 的 backbone,为了对齐 BERT,Q 和 C 被连接为以下形式:
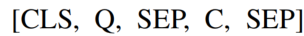
传统的 MRC 模型使用两个 softmax 层去分别预测答案的开始和结束位置,这种方法只适用于只有一个答案的提取任务,但是在我们的任务中可能会有多个答案。为了解决这个问题,将任务转化为基于问题的序列标注任务,即对每一个 token 预测BMEO(beginning,inside,ending,outside)标签。每一个单词的表示被送入 softmax 层去输出一个 BMEO 标签。
使用这种序列标注的方法,将两个 N 分类任务(预测开始和结束位置,N 为句子长度),转化为 N 个 5 分类任务。
联合训练(Jointly train):进行两个阶段的联合训练,其中 λ 是控制这两个目标函数之间的权重的参数,它们在训练过程中共享参数。
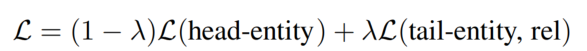
Reinforcement Learning
从一个轮次中提取的答案不仅会影响其自身的准确性,而且还决定了如何为下游回合构造一个问题,这反过来又会影响以后的准确性。我们决定使用强化学习来解决这种问题。
实验结果
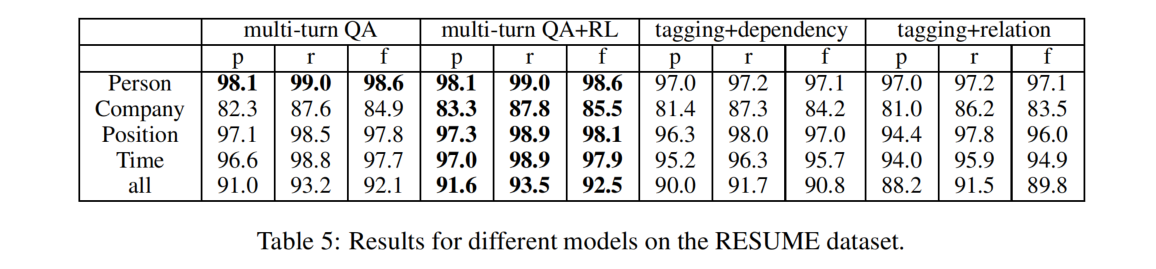
在 RESUME 上的结果
答案按人(第一轮次)、公司(第二轮次)、职位(第三轮次)和时间(第四轮次)的顺序提取,每个答案的提取取决于之前的顺序。
multi-turn QA 的效果最好,RL(强化学习)为 multi-turn QA 提供了额外的结果提升。
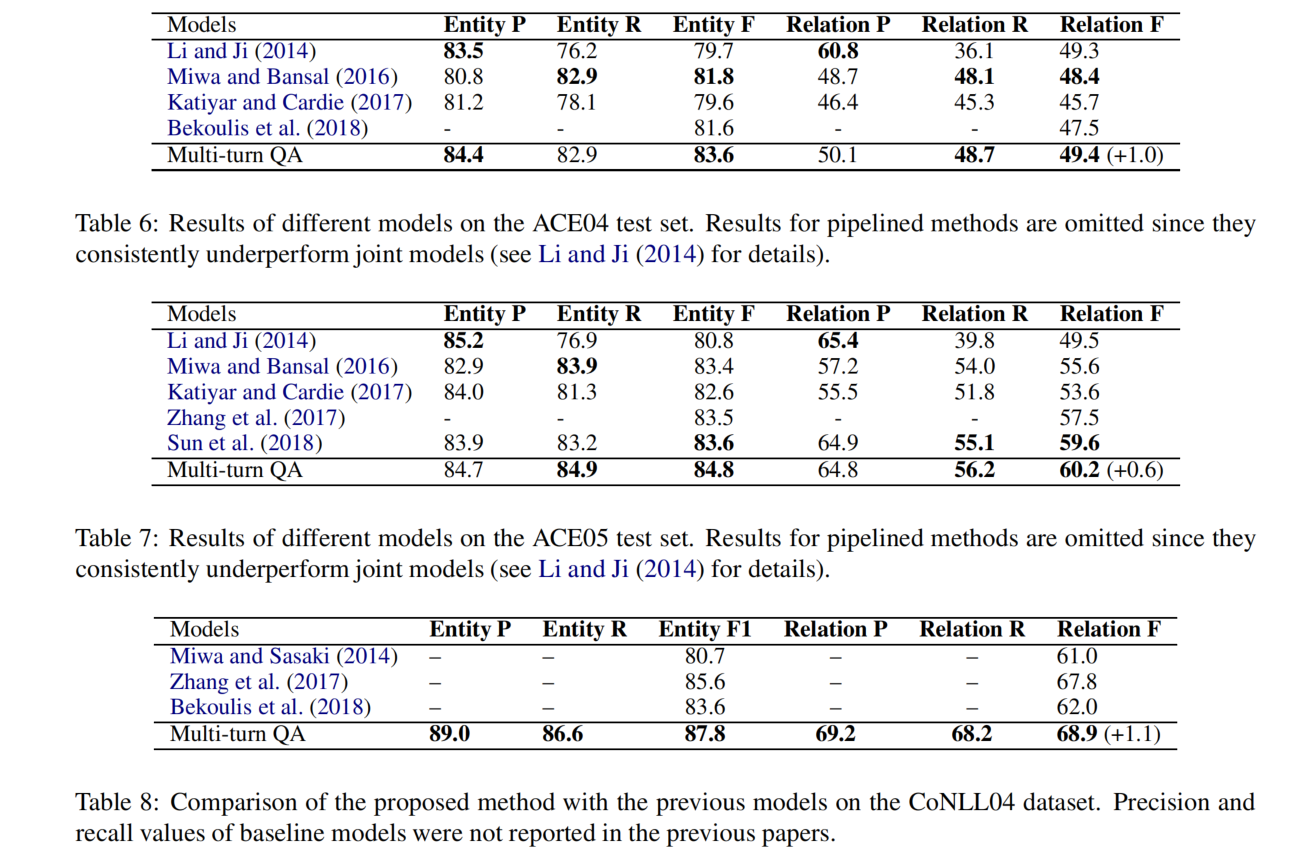
在 ACE 04、ACE 05 和 CoNLL04 上的结果
消融实验
Question Generating 策略的效果
比较自然语言问题和伪问题的效果:
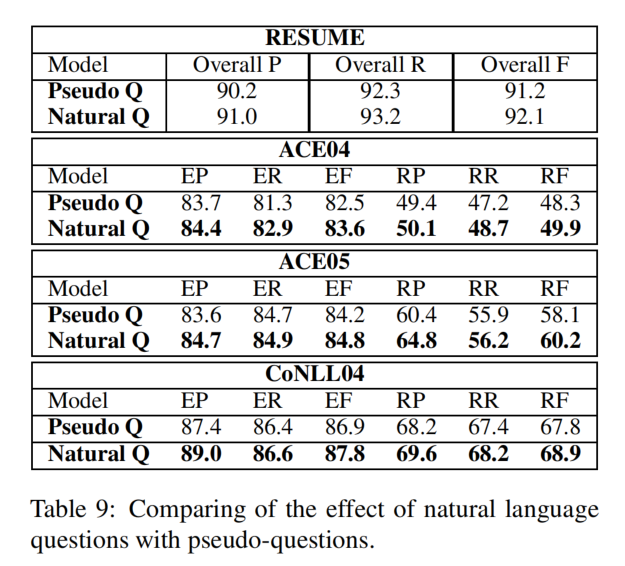
自然语言问题的效果更好,这是因为自然语言问题提供了更细粒度的语义信息,并可以帮助提取实体/关系。相比之下,伪问题提供了非常粗粒度、模糊的和隐式的实体和关系类型的提示,这甚至可能会混淆模型。
Joint Training 的效果
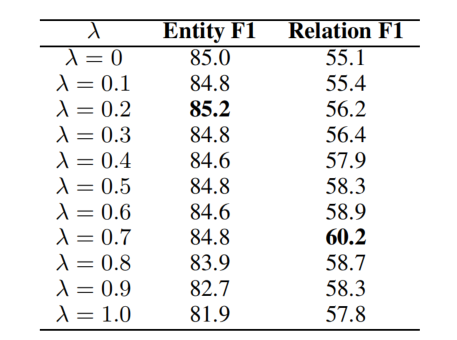
将实体关系提取任务分解为两个子任务:头实体提取的多答案任务和联合关系提取和尾实体提取的单答案任务。共同训练了两个参数共享的模型,参数 λ 控制了这两个子任务之间的权重:
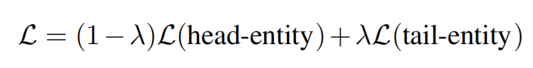
当 λ 设置为 0 时,系统基本上只在头部-实体预测任务上进行训练。有趣的是,λ = 0 并不能获得最佳的实体提取性能。这说明了第二阶段的关系提取实际上有助于第一阶段的实体提取,这再次证实了将这两个子任务同时考虑的必要性。对于关系提取任务,当 λ 设置为 0.7 时,性能最好。