PRGC: Potential Relation and Global Correspondence Based Joint Relational Triple Extraction
会议:ACL
年份:2021
作者:Hengyi Zheng, Rui Wen, Xi Chen, Yifan Yang, Yunyan Zhang, Ziheng Zhang, Ningyu Zhang, Bin Qin, Ming Xu, Yefeng Zheng
机构:College of Electronics and Information Engineering, Shenzhen University Information Technology Center, Shenzhen University Tencent Jarvis Lab, Shenzhen, China
数据集:
贡献:
- 以一种全新的视角,将关系抽取任务分为三个子任务:Relation Judges,Entity Extraction 和 Subject-object Alignment。
- 针对三个子任务,提出关系抽取框架 PRGC(Potential Relation and Global Correspondence),并提出了三大组件:Potential Relation Prediction,Relation-Specific Sequence Tagging 和 Global Correspondence,减缓了冗余关系判断、基于 span 的提取泛化性差、不足的 subject-object 对齐的问题。
- 尤其当数据集中有很多关系、复杂的 overlapping 的场景下,方法的效果很好。
对于overlapping 问题,不仅解决了 SEO 和 EPO 问题,而且也解决了 SOO(Subject Object Overlap)问题。三种 overlapping 问题的的例子如下:

模型结构
PRGC 将关系抽取划分为 3 个子任务:
- Relation Judgment:得到可能所包含的关系,可能的关系是全部关系的子集。
- Entity Extraction:给定一个句子和其中包含的可能的关系集,利用 BIO 标记,提取实体。
- Subject-object Alignment:预测主体和客体的开始 token 的 correspondence score(也就是说,其余的 token pair 分数很低)。
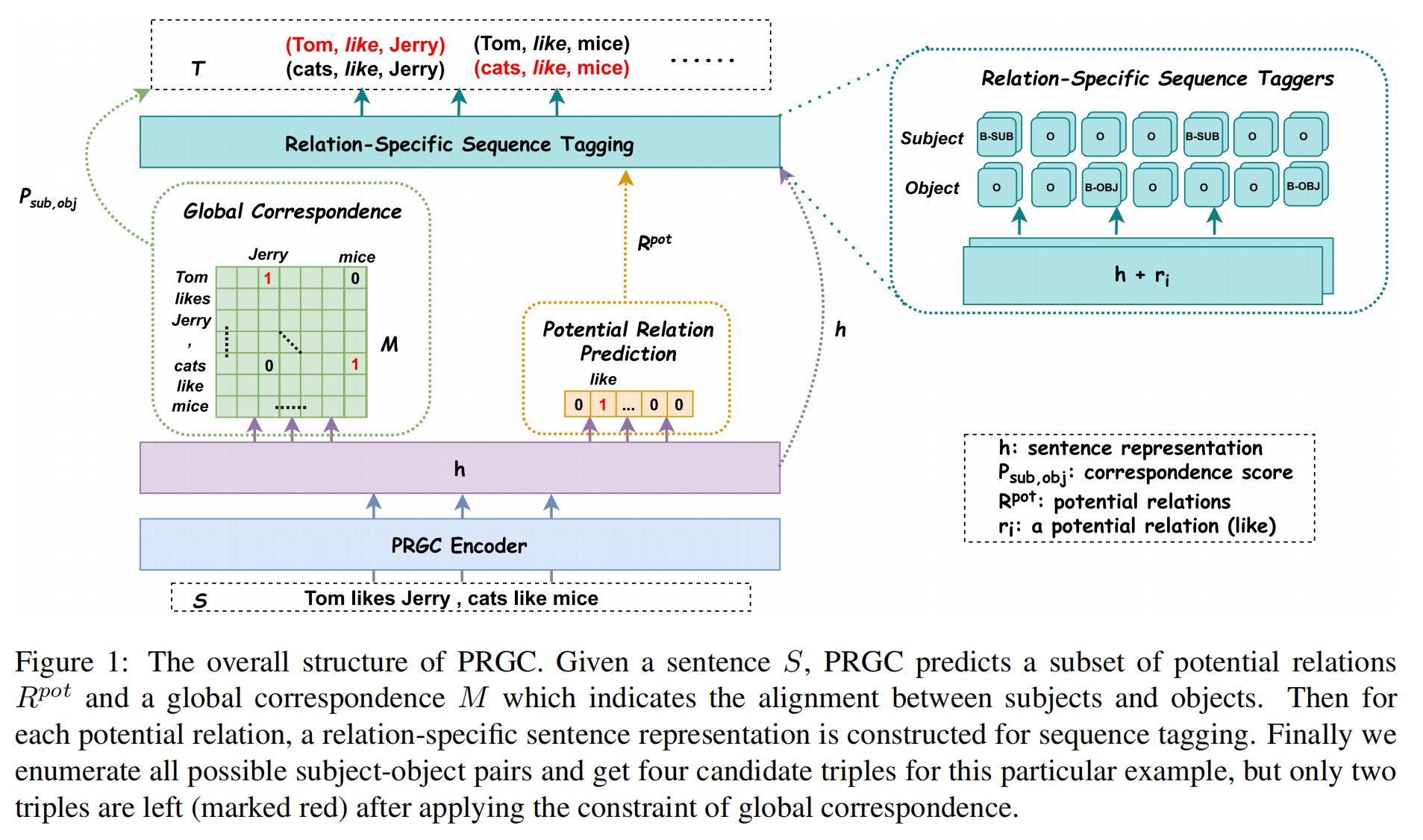
PRGC Encoder
论文使用预训练的 BERT 作为 Encoder,也可以使用其他的如 Glove 和 RoBERTa 等。
PRGC Decoder
PRGC decoder 包含以下三个部分。
Potential Relation Prediction
首先预测句子中可能包含的关系,首先对 encoder 的输出 h 进行平均池化操作,接着送入一个线形层和 sigmoid 函数中,预测每一种分类出现的概率。把这个子任务当作是多分类任务,当输出的概率超过阈值 λ1 时,对应关系的标签被置为 1。
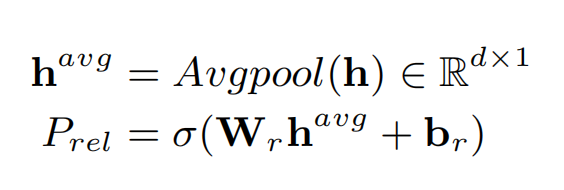
Relation-Special Sequence Tagging
分别执行两个句子标注任务,用于标注 subject 和 object。因为需要解决 Subject Object Overlap(SOO)问题,所以需要两次句子标注。其中,u 代表 relation embedding;输出的维度为 3,代表 BIO。

若数据集中没有 SOO 问题,则句子标注可以被简化为 1 次。
Global Correspondence
因为 Global Correspondence matrix 独立于关系,所以可以在潜在关系预测的阶段同时学习。
首先,枚举出所有可能的 subject-object pair。
然后,检查 Global Correspondence matrix 中对应的分数,若分数超过阈值 λ2 则保留,否则过滤掉。
Global Correspondence matrix 中的每一个元素代表,第 i 个 token 和第 j 个 token 作为主客体的起始位置的置信度。矩阵中每个元素的计算方法如下:

Training Strategy
三个部分的损失函数如下所示:

而总的损失函数就是三个部分的损失函数的加权和,权重可以自己训练,在论文中被简化为 α = β = γ =1:
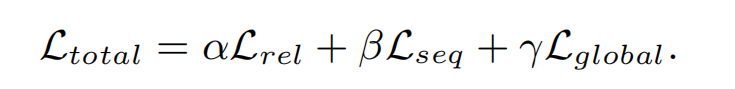
实验结果
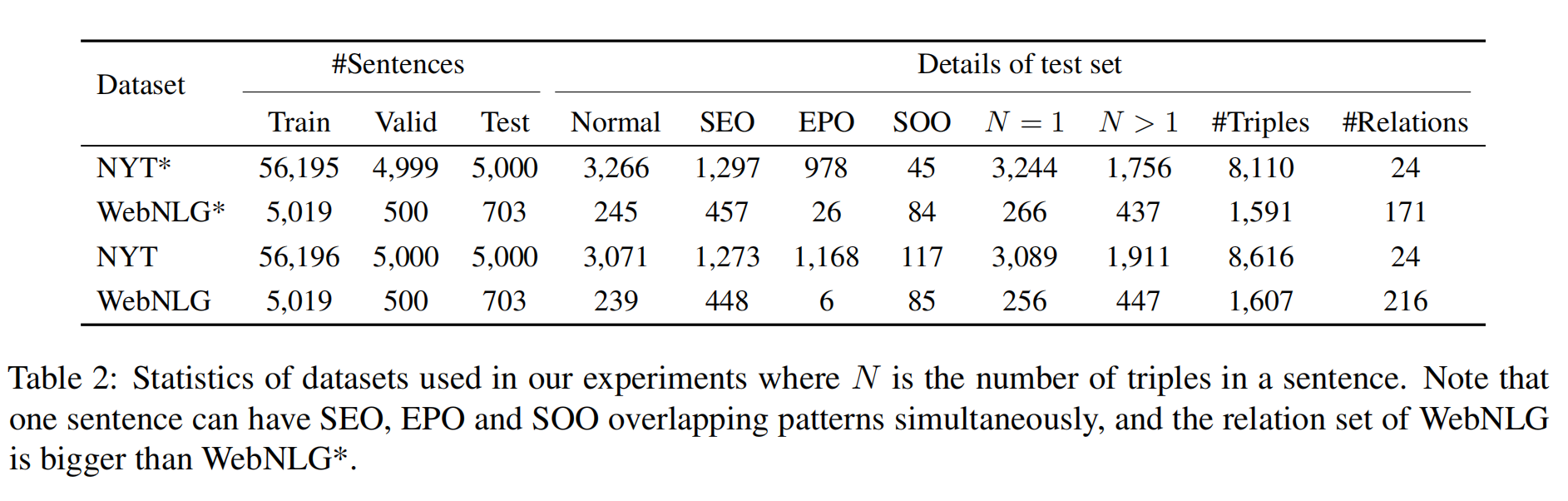
NTY 和 WebNLG 的标注有两个版本,用 * 表示第一个版本,即只标注了实体的最后一个单词;而第二个版本中,标注了完整的实体 span。数据集的统计结果如下:
PRGC 与其他模型的对比如下:
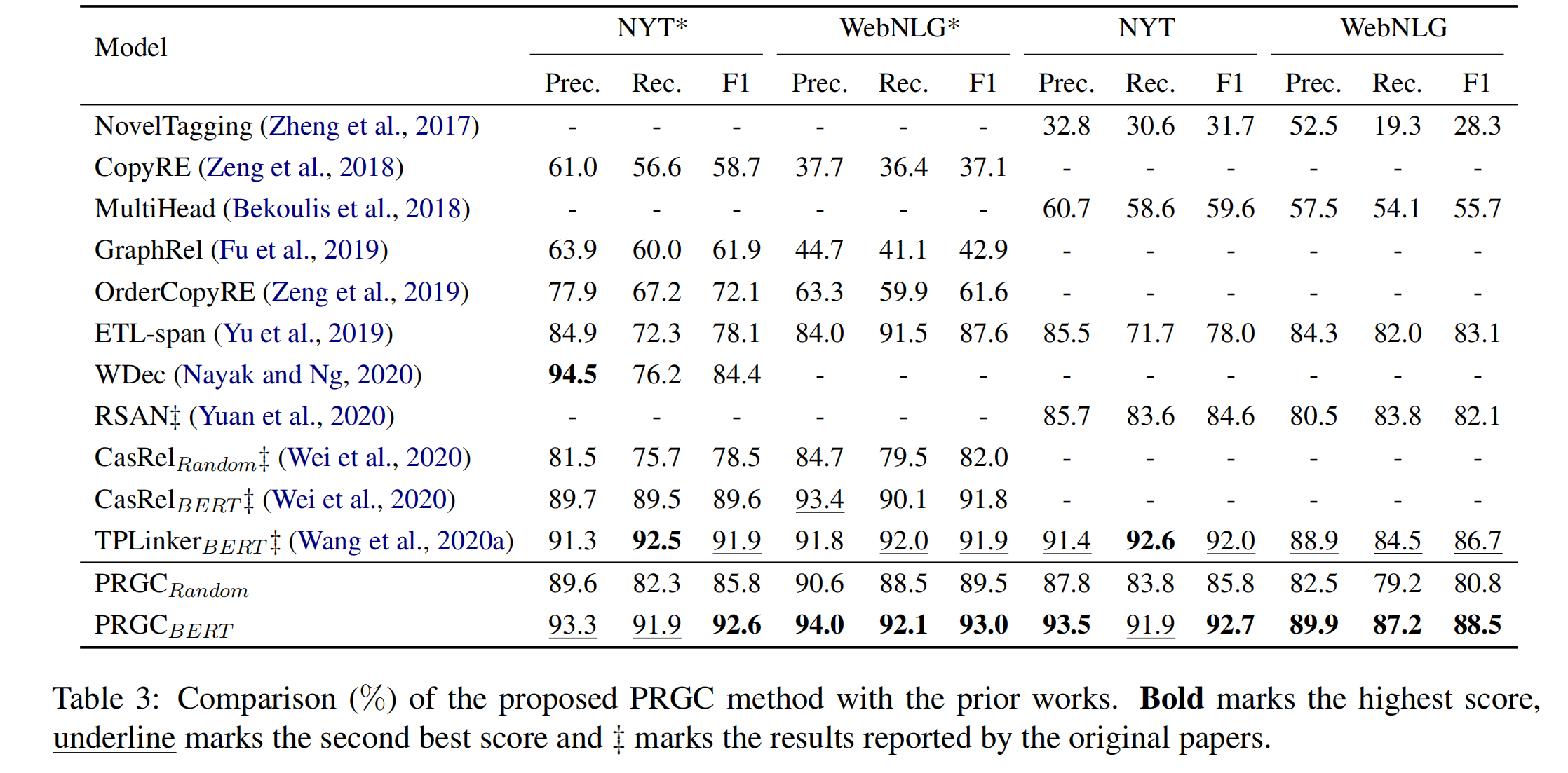
值得注意的是,尽管 TPLinker 比 CasRel 有更多的参数,但是在 WebNLG* 这个数据集上只有 0.1% 的提升。然而,此篇论文在 WebNLG 数据集上有着 1% 的提升,这是 TPLinker 提升的十倍的改进,并在 WebNLG 数据集上实现了显著的提升。这背后的原因是,论文的模型中的关系判断组件大大减少了冗余关系,特别是在包含数百个关系的 WebNLG 数据集中。换句话说,与在每个关系下执行实体提取的模型相比,负关系的减少提供了额外的提升。
在复杂场景下的实验结果
实验结果表明,不管是 overlapping 问题还是句子中出现多个关系三元组,论文的模型都展现出很好的效果,在复杂的场景下很有优势。
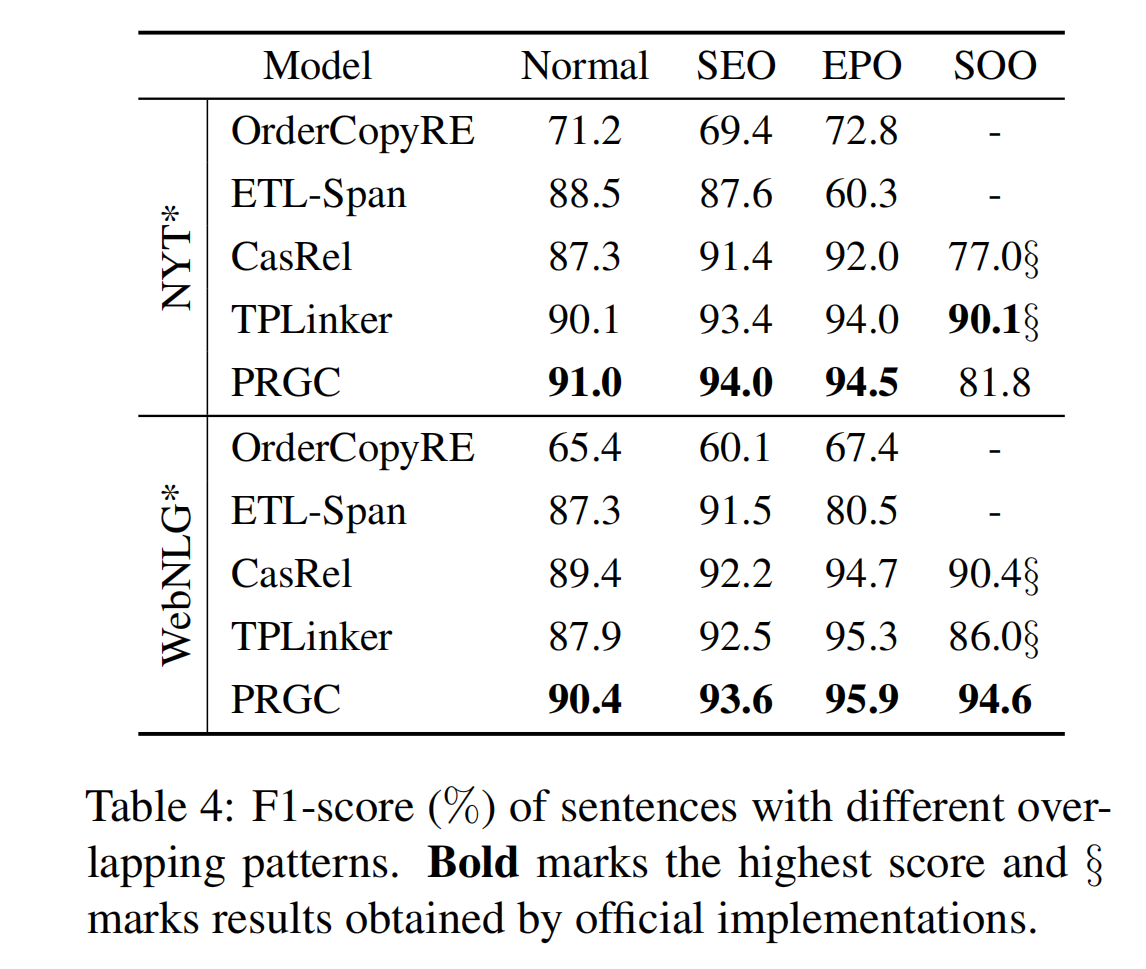
不同的 Overlapping
PRGC 除了在 NYT* 数据集 SOO 问题中表现不佳,其余的所有 overlapping 场景中 PRGC 的表现都是最好的。
作者将出现这种状况的原因归结为 NYT* 中 SOO 的占比太低了(8110 个样本中仅仅出现了 45 次),这样的预测结果是不可靠的。
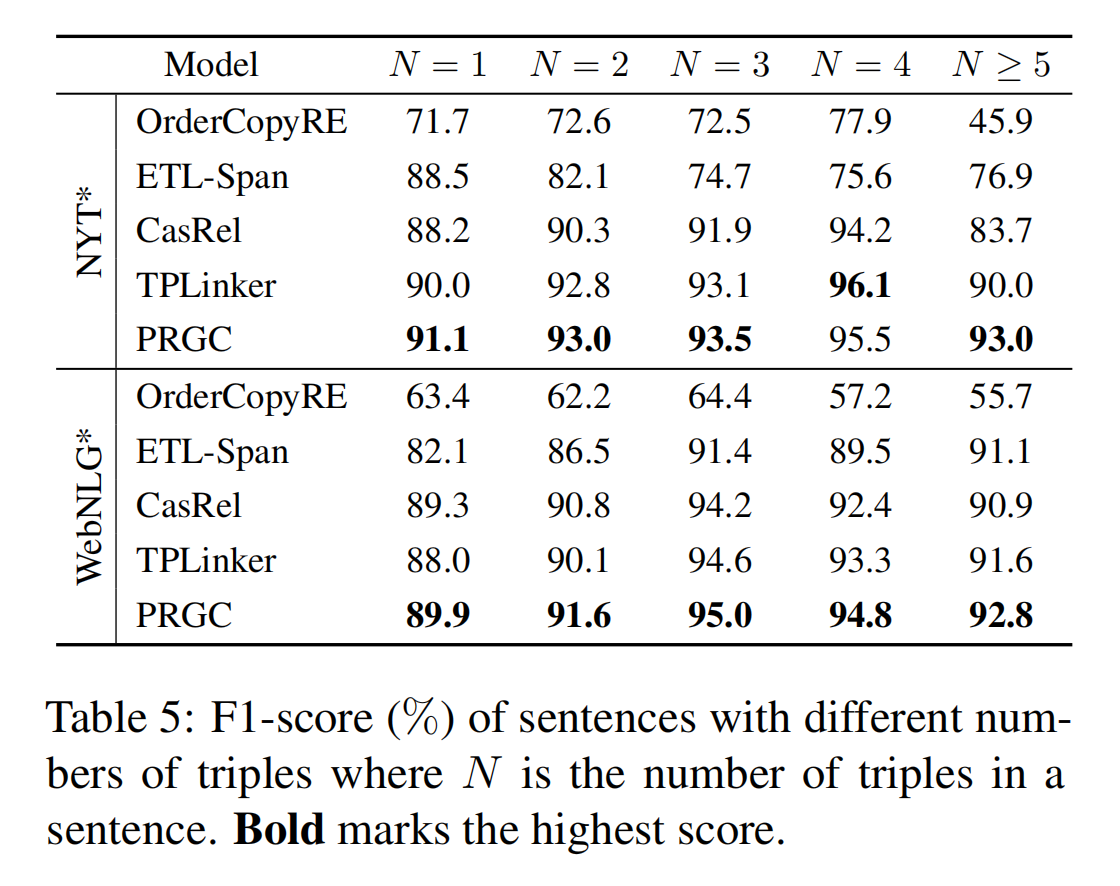
句子中关系三元组的数量
对于句子中关系三元组不同数量的场景,PRGC 的表现基本上是最优秀的:
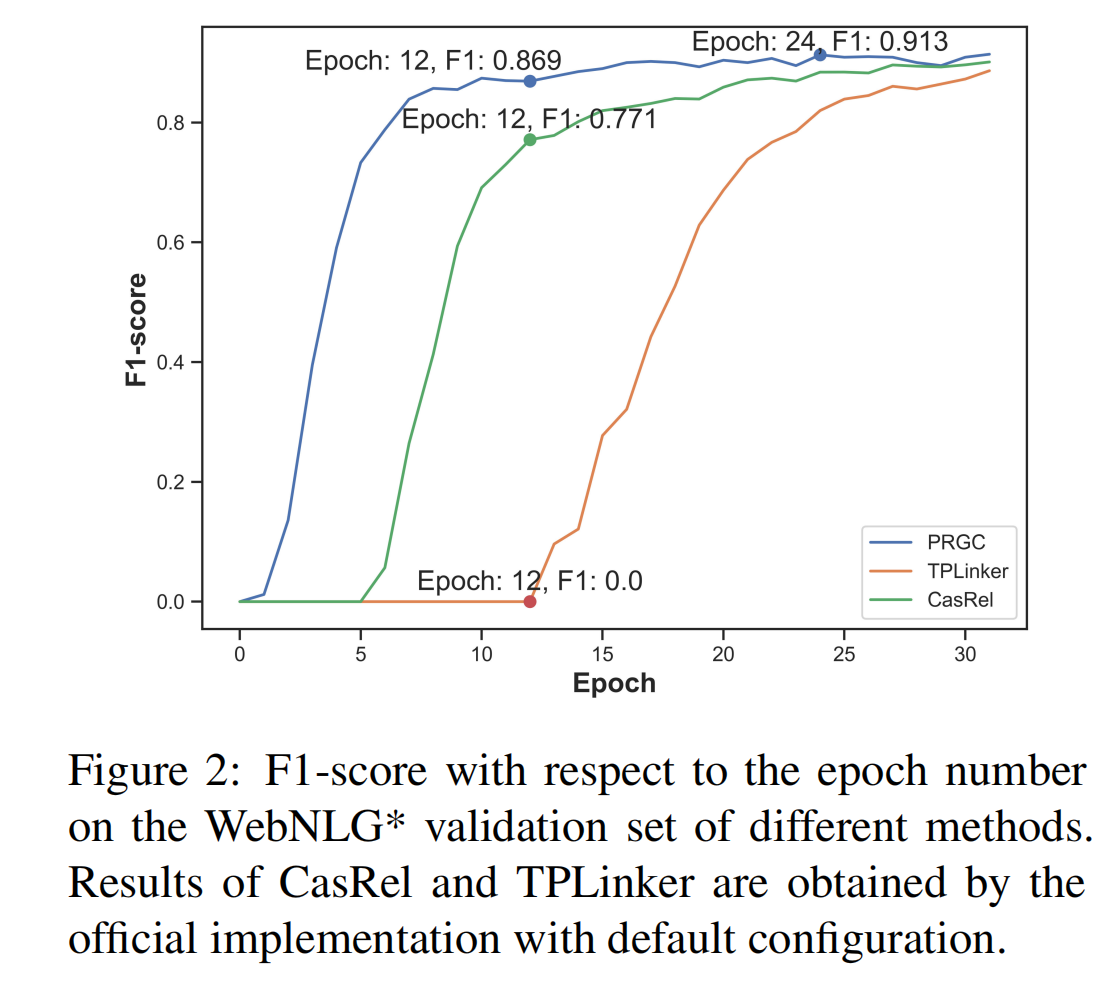
模型效率
在收敛速度方面,相比于 CasRel 和 TPLinker,PRGC 的模型收敛速度最快。
消融实验
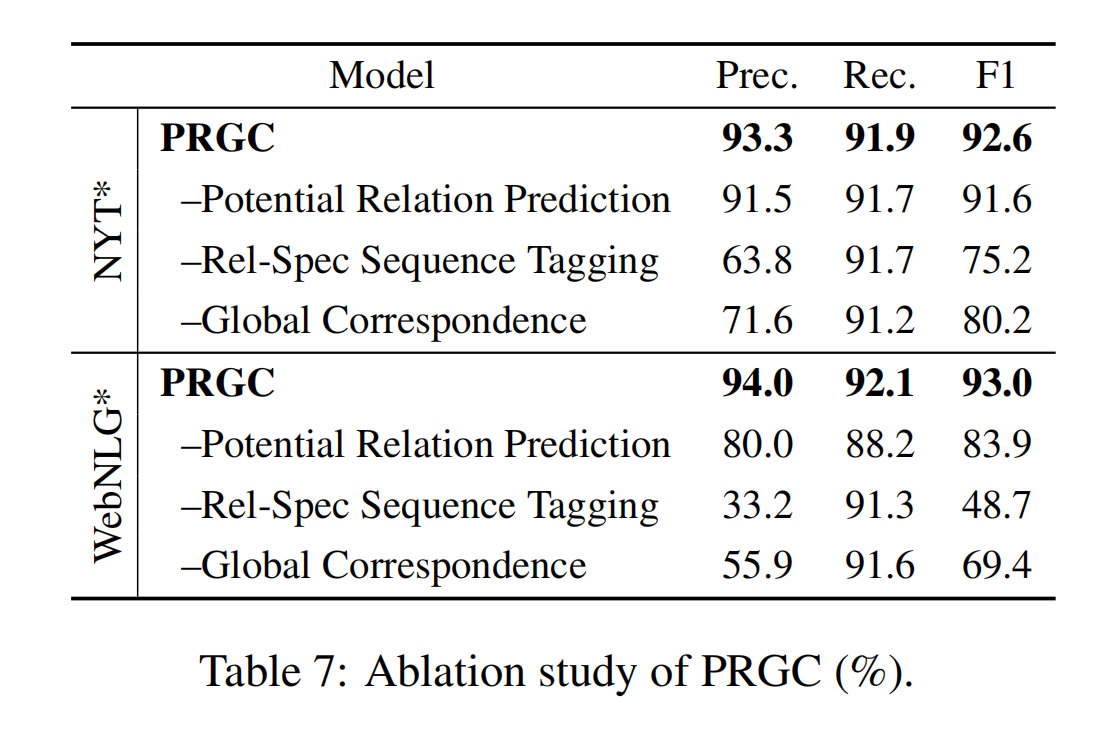
Potential Relation Prediction 的效果:
使用关系集中的每一种关系用于后续的预测,对每一种关系都执行序列标注任务。
在没有该组件时,准确性显著降低,因为有了更多的冗余关系(在关系类型多的数据集 WebNLG 中,这样的现象更为明显)。同时,训练和预测的时间也会相应的增加,因为对所有的关系都要执行序列标注任务。
所以通过实验,证明了该组件旨在预测潜在关系子集的有效性,这不仅有利于模型的准确性,而且有利于效率。
Rel-Spec Sequence Tagging 的效果
使用分类,来预测实体的开始位置和结束位置(这种就是基于 span 的方案)。基于 span 的方案,使得模型表现下降的十分明显。
通过下图的示例可以观察到,基于 span 的方案倾向于识别长实体以及识别出正确的 subject-object 对,但是忽略了 subject 和 object 之间的关系。这是因为模型倾向于记住一个实体的位置,而不是理解底层的语义。
PRGC 提出的基于序列标注的实体识别,不管是在长实体识别方面、还是在理解 subject 与 object 之间的关系方面,都表现得很好。这说明,PRGC 的泛化能力更加强大。

Global Correspondence 的效果
使用 heuristic nearest neighbor 准则,而不使用 global correspondence 矩阵时,模型的精度显著降低。