Joint Extraction of Entities and Relations Based on a Novel Tagging
会议:ACL
年份:2017
作者:Suncong Zheng, Feng Wang, Hongyun Bao, Yuexing Hao,Peng Zhou, Bo Xu
机构:Institute of Automation, Chinese Academy of Sciences
数据集:NYT(https://github.com/shanzhenren/CoType),训练集利用远程监督的方法进行构建的。训练集中有 353k 个关系三元组,测试集中有 3880 个关系三元组。并且,关系类型的数量为 24。
贡献:
- 针对联合抽取,提出的一种新的标记方法(包含了实体和关系信息的标签),可以将抽取问题转换为序列标注问题。
- 提出了一个具有 biased loss function 的模型,以适应新标签,它可以增强实体与关系之间的联系。
模型结构
论文提出了一种端到端的基于序列标注的关系抽取模型,主要结构:
- BiLSTM 作为 encoder
- 基于 LSTM 的 decoder
- biased loss,起到了增强实体标签、削弱 O 标签的效果
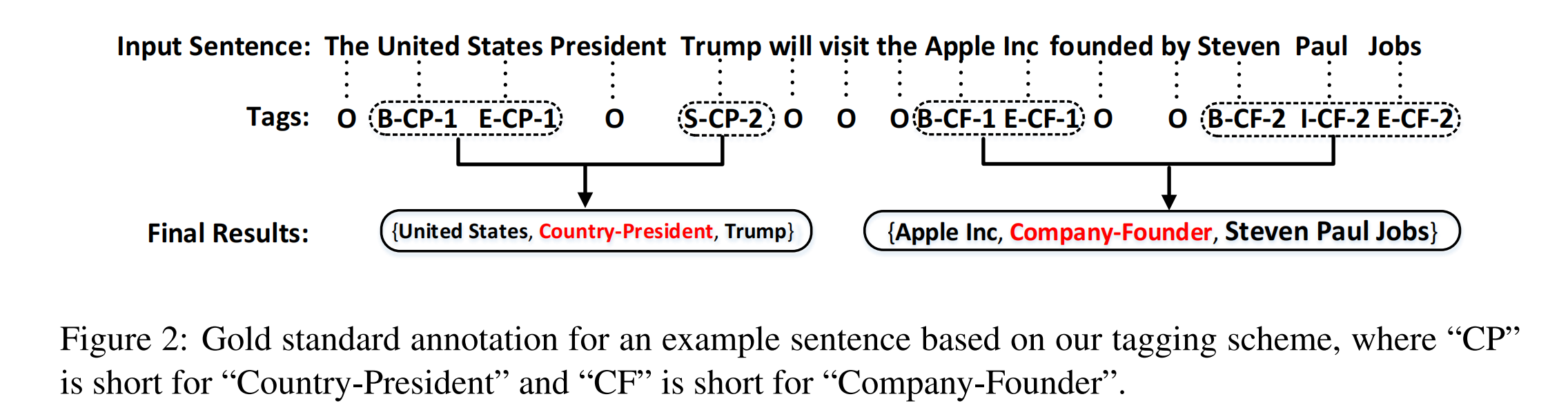
序列标注方案
论文提出的序列标记方案中,O表示 Other。除了 O 以外的其他标签有三部分组成:
- 单词在实体中的位置,用 BIES(Begin,Inside,End,Single)表示。
- 关系类型。
- 在关系三元组中的角色,可以是 1 或者 2,1代表头实体,2 代表尾实体。
标签个数为:
Nt = 2 * 4 * |R| + 1,其中 2 为关系三元组中的角色, 4 为 BIES,|R| 为关系种类数量,1 为 Other 标签。
至于如何将被标记的序列转换为实体,论文将具有相同关系类型的实体合并为一个关系三元组。
若一个句子中,包含两个及以上的具有相同关系类型的关系三元组,则根据最近准则(nearest principle)将每两个实体(不考虑overlap)合并为一个三元组。
注意,论文没有考虑到 overlaping 问题,这也是这篇论文的最大缺陷。
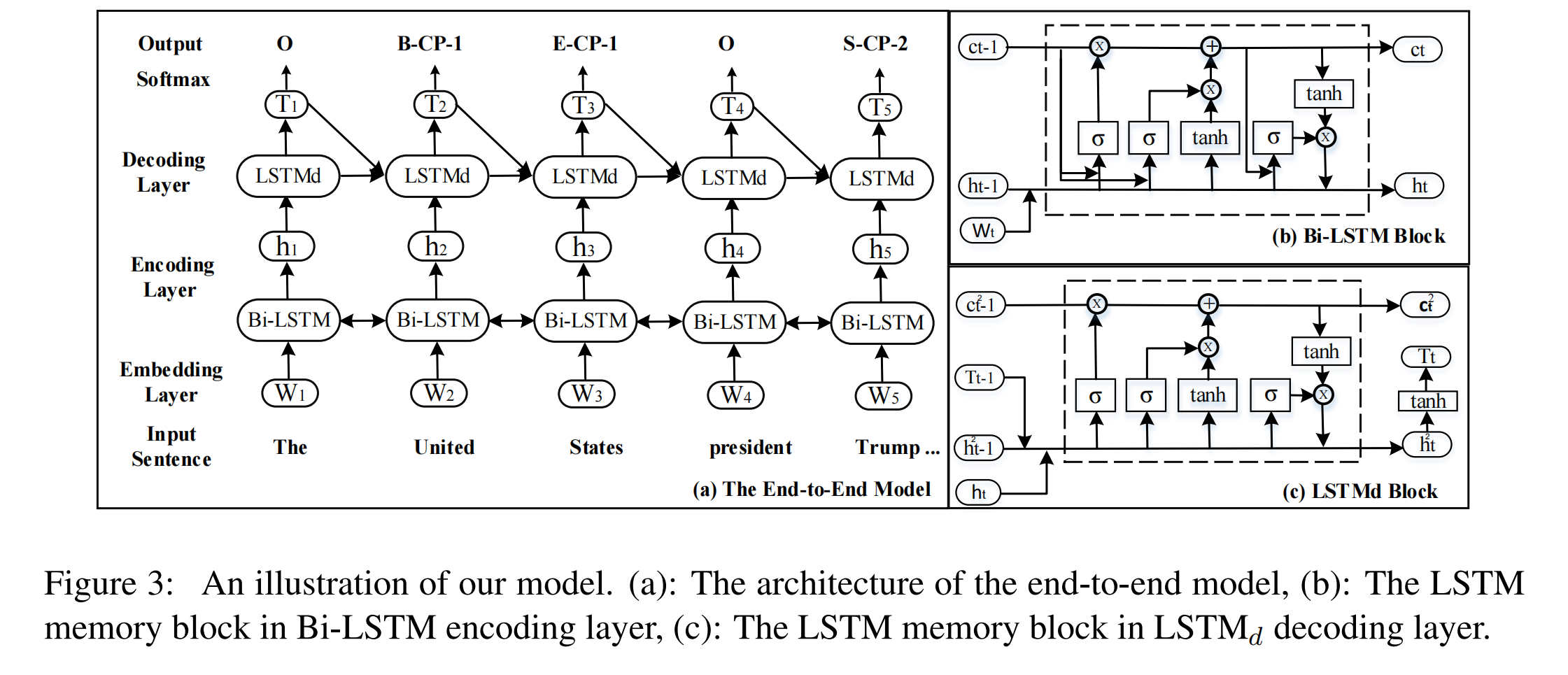
End-to-end Model
BiLSTM Encoding Layer
LSTM 的输出如下,将双向 LSTM 的输出拼接起来,得到 encoder 的输出。
其中,i 表示 input gate,f 表示 forget gate,o 表示 output gate,c 为记忆单元。
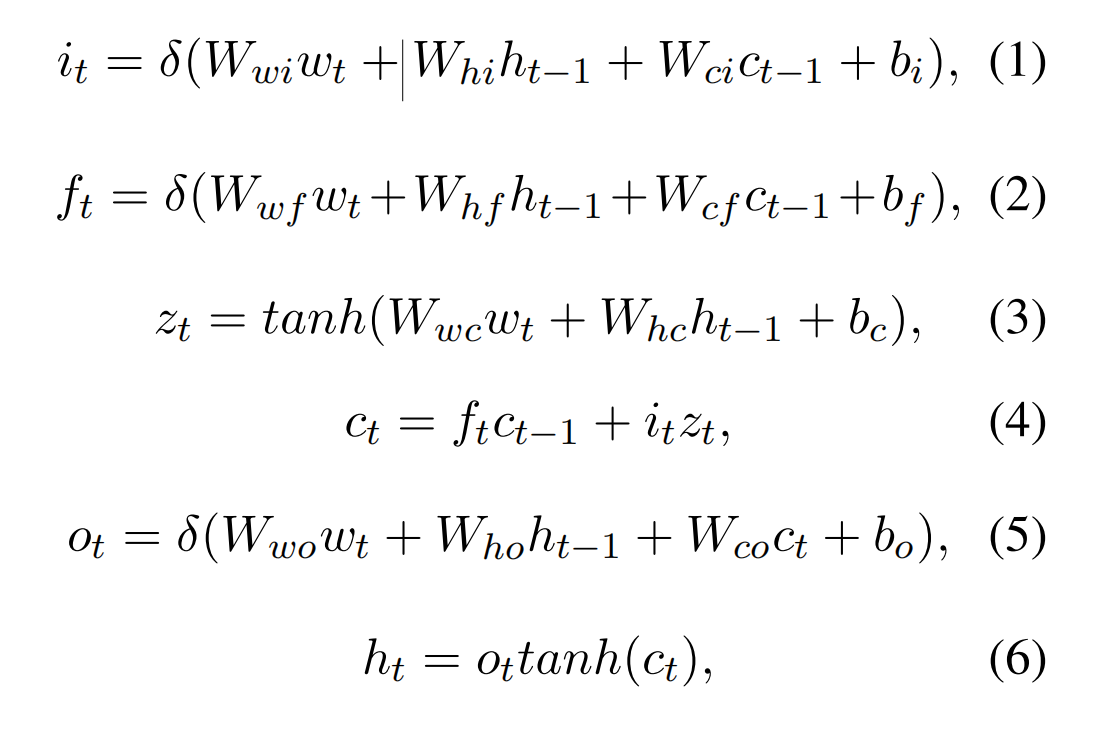
LSTM Decoding Layer
LSTMd 输出的计算方式如下,其中 T 代表的是预测标签的 embedding:
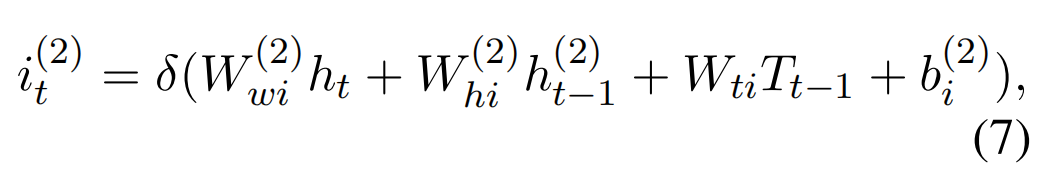
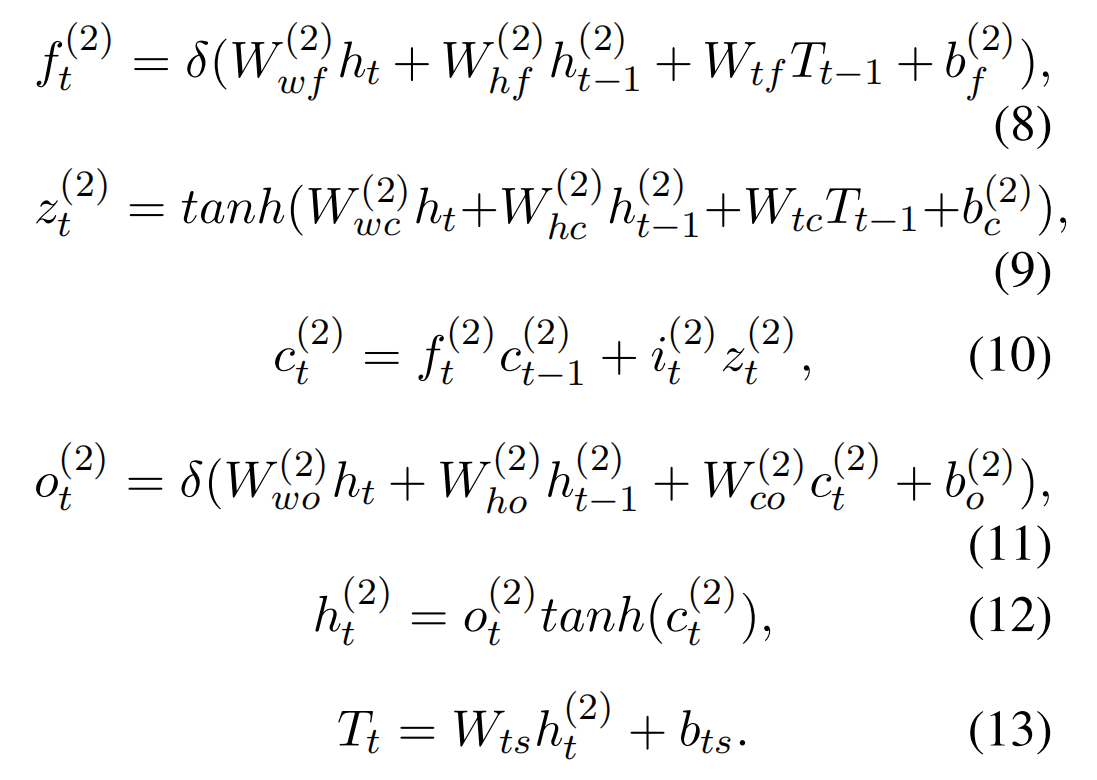
最后接一个 softmax 层,用于生成每个标签的概率:
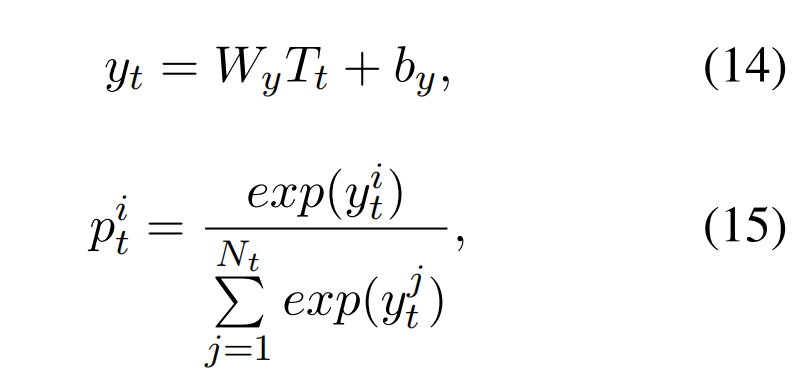
因为 T 可以看作是标签的 embedding,而 LSTM 能够学习长期的依赖关系,因此 LSTMd 可以学习到标签之间的相互关系。
Bias Objective Function
目标函数如下:
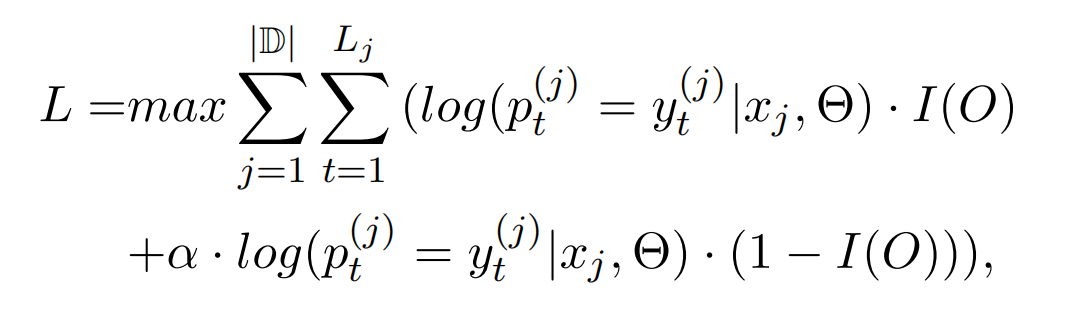
其中 |D| 代表训练集的 size;Lj 为第 j 个句子的长度;α 为偏差权重(α 越大,关系标签对模型的影响就越大);I(O) 是个 switching function,用于区分标签 O 与其他关系标签的 loss:
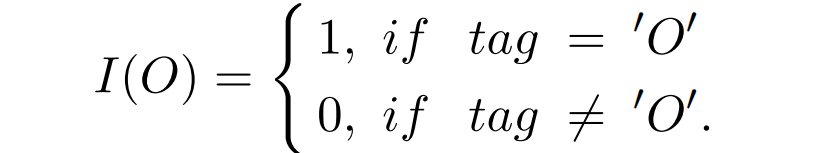
实验结果
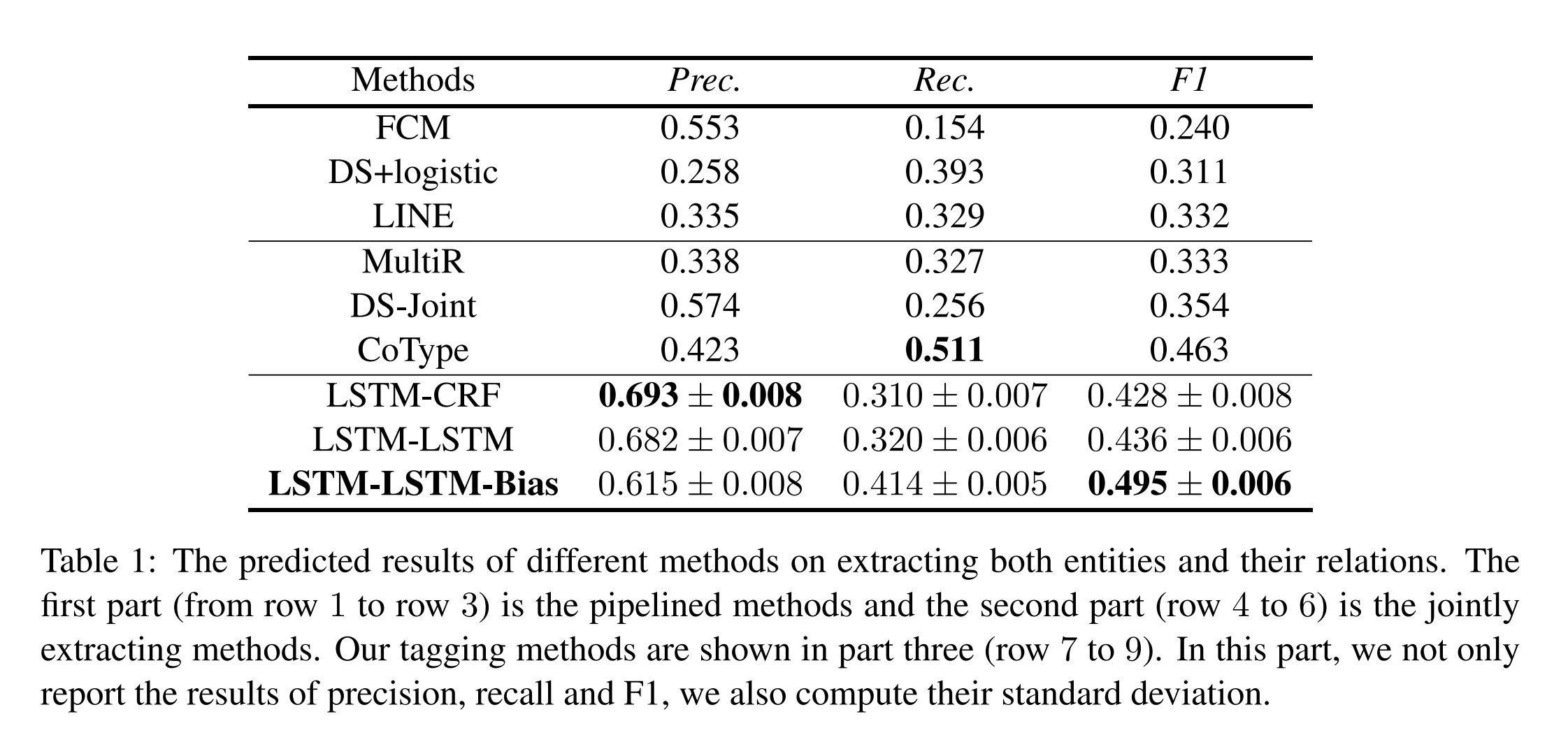
当一个关系三元组的关系类型和两个对应实体的头偏移量都是正确的时,则认为它是正确的。与其他模型的对比效果如下:
误差分析
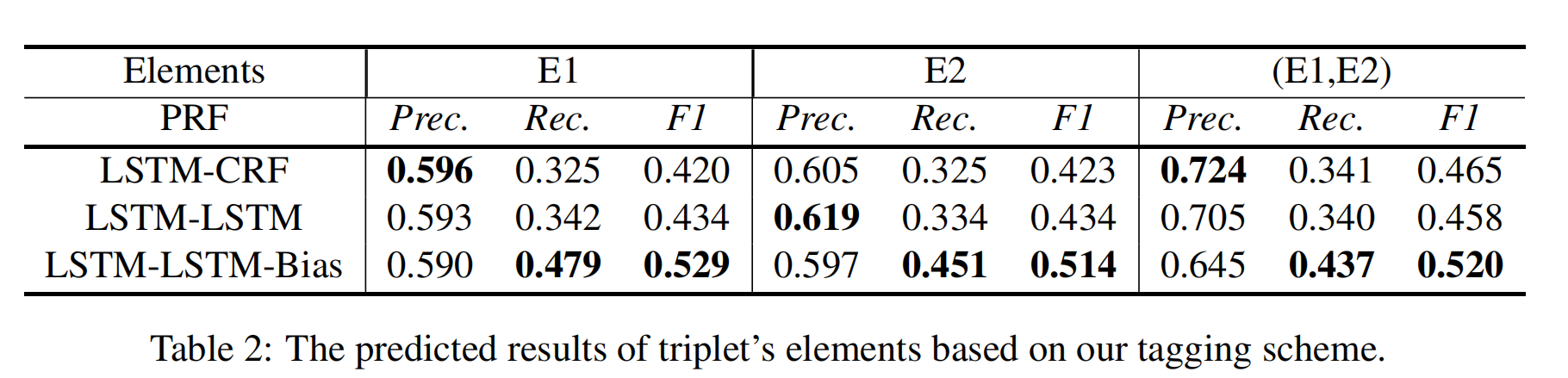
(E1,E2)与 E1 和 E2 相比具有更高的精度。但其召回结果低于 E1 和 E2。这意味着一些预测的实体不会形成一对(只得到 E1,找不到对应的 E2,或者得到 E2,找不到对应的 E1)。因此,模型导致预测更多的单一 E 和更少的(E1,E2)。因此,实体对(E1、E2)比单个 E 具有更高的精度和较低的召回率。
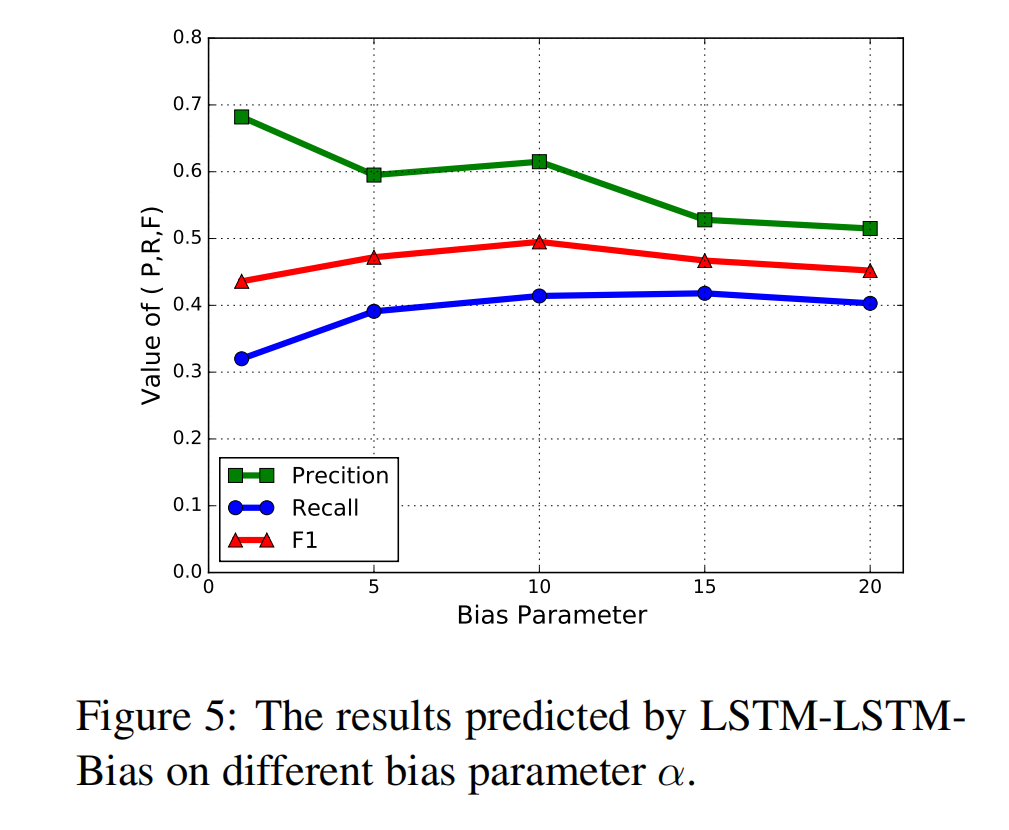
α 的影响
探究 bias loss function 中权重 α 的影响,可以看到随着 α 的增大准确率降低但是召回率升高,在 α = 10 时,F1 达到最大值。