A Partition Filter Network for Joint Entity and Relation Extraction
会议:ACL
年份:2021
作者:Zhiheng Yan, Chong Zhang, Jinlan Fu, Qi Zhang, Zhong yu Wei
机构:School of Computer Science, Shanghai Key Laboratory of Intelligent Information Processing, Fudan University, Shanghai, China
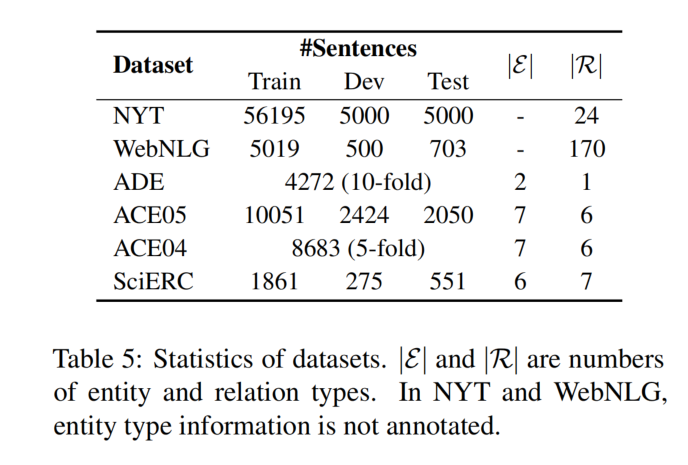
数据集:在六个数据集上进行评价,NYT、WebNLG、ADE、SciERC、ACE04、ACE05
贡献:
- 提出了一种 partition filter network,用于建模任务(NER 和 RE)之间的双向交互。
- 实验表明,关系预测对命名实体预测的贡献是不可忽视的(与 PURE 相反)。
根据之前的工作在编码 task-specific features 上的差异,可以将现有的方法分为两种类型:sequential encoding 和 parallel encoding。
- sequential encoding:task-specific features 被顺序的生成,这意味着第一个提取的特征不会被后面提取的特征所影响(任务间特征交互不平衡)。
- parallel encoding:task-specific features 由共享的输入独立的生成,不需要考虑 encoding 的顺序。在这种方法中,虽然编码顺序不再是一个问题,但是交互只存在于共享 input 中。
然而,上述两种编码方式都不能正确的模拟 NER 和 RE 任务之间的双向交互。
论文考虑在 feature encoding 时加入双向交互,采用了一种 joint encoding 的形式:使用一个编码器联合编码 task-specific features,这个编码器应该存在一些用于任务间通信的交互部分。
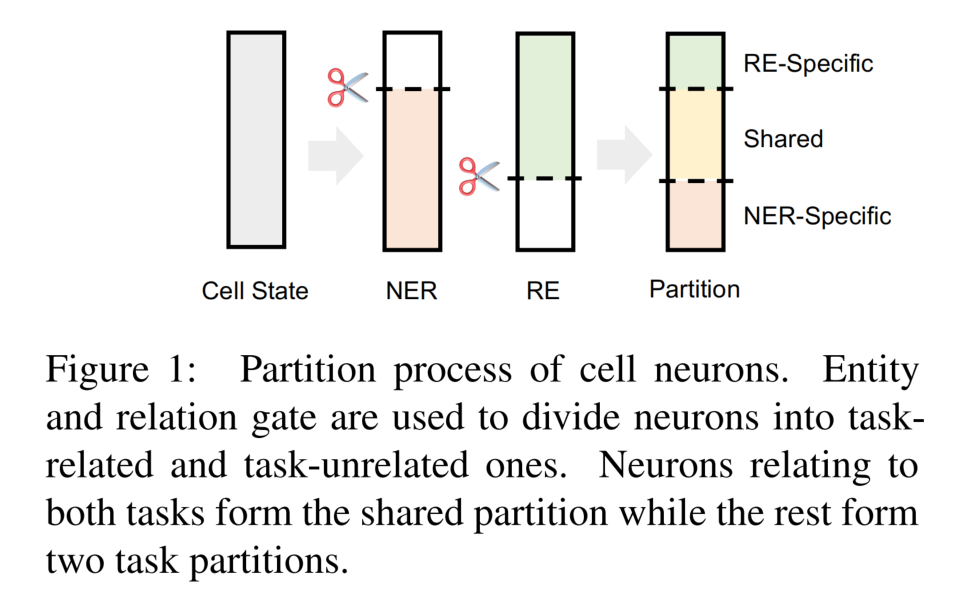
提出了一种 partition filter encoder,利用 entity gate 和 relation gate 将神经元划分为两个任务分区和一个共享分区。这些分区被被组合生成了 task-specific features(提出了无关当前任务的分区信息)。
模型结构
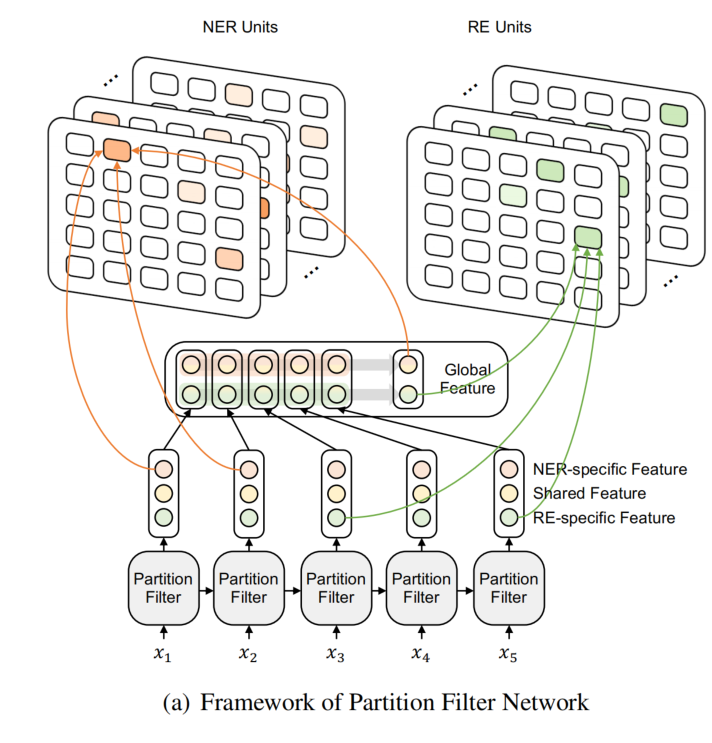
模型由三个部分组成:
- partition filter encoder:用于生成 task-specific features,作为实体和关系预测的输入。
- NER unit
- RE unit
论文将实体关系联合抽取分为两个子任务:命名实体识别和关系抽取。
- 对于 NER,需要识别出实体的 start、end position 和实体类型。
- 对于 RE,需要识别出 subject 和 object 的 start position 以及它们之间的关系。
Partition Filter Encoder
partition filter encoder 是一个循环特征编码器,用于联合提取 task-specific features。分为两步,partition 和 filter:
- partition:每一个时间步中,encoder 将神经元分为三个部分:entity partition,relation partition 和 shared partition。
- filter:通过选择和组合这些部分、过滤出与每个任务无关的信息,来生成 task-specific features。
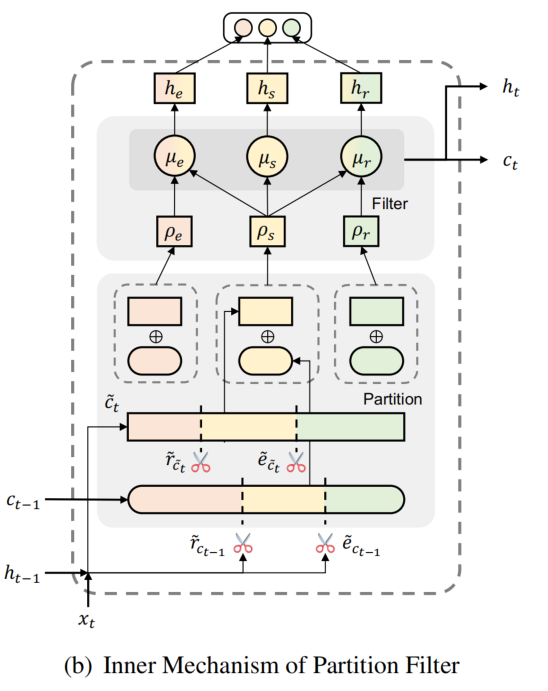
Partition
两个任务分区存储任务内部的信息,而共享分区存储任务间的信息。神经元 ct-1 是上一个时间步的输出,而神经元 ct_hat 由如下方式计算(ht-1 为上一个时间步的输出):
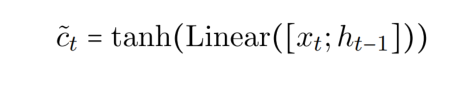
利用两个门 entity gate 和 relation gate 将神经元 c 划分为两个部分(与当前任务相关、与当前任务不相关)。shared partition 通过组合两个门的分区结果而形成的,共享分区中的神经元可以被视为对这两个任务都有价值的信息。gates 由 cummax 激活函数计算,cummax( . ) = cumsum(softmax( . )),输出形式可以近似看为 (0, ..., 0, 1, ..., 1)。
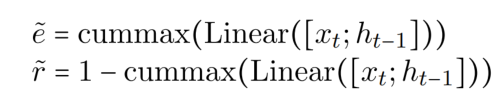
其中,cumsum 的计算式如下所示:
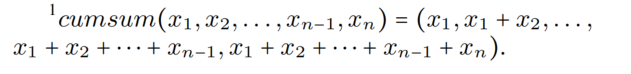
gates 将神经元 c 划分为三个部分 entity partition、relation partition 和 shared partition。其中 shared partition 为两个 gate 对位相乘,具体如下图所示(注意到,三个部分相加是不等于1的,这就保证了在转发消息传递中,一些信息会被丢弃,类似于遗忘机制):
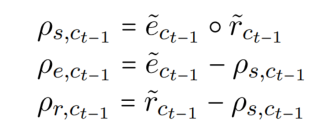
然后,形成最终的分区,两个神经元(t 和 t-1)相加而成:
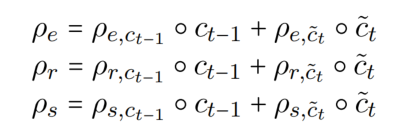
Filter
提出了三种 memory block(用 μ 表示):entity memory、relation memory 和 shared memory。entity memory 选择了 entity partition 和 shared partition 中的信息(就相当于,与 NER 无关,甚至有害的信息被过滤了),relation memory 选择了 relation partition 和 shared partition 的信息,shared memory 选择了 shared partition 的信息。
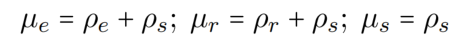
shared partition 中的信息可以被 entity memory 和 relation memory 获取,所以 relation feature 对 entity feature 的形成有直接的影响(在之前的工作中,relation 是不影响 entity 的)。
最终 entity feature,relation feature,shared feature 的计算式如下:

用于输入到下一个时间步的隐藏状态 h 和 神经元 c 的计算式如下:
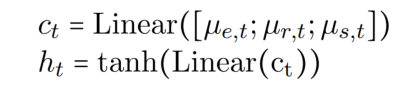
Global Representation
在模型中,除了应用了一个单向(前向) encoder 用于编码特征,还用了一个 task-specific global representation 来捕捉 feature 上下文的语义信息(用这个来替换后向编码器,让未来的上下文对每个单词可见)。global representation 由 task-specific features 和 shared features 计算而成:
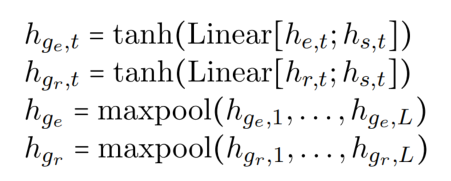
Task Units
NER Unit
对于 NER 任务来说,就是识别出 wi 和 wj 是否是实体的 start 和 end,首先用 ELU 激活函数去得到 entity span representation:
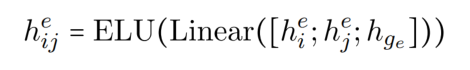
其中,ELU 激活函数的表达式为:
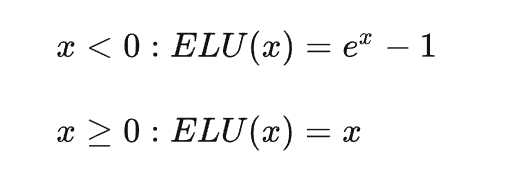
论文将 NER 转化为填表问题,第每一个实体类型对应一张表, 第 k 个实体类型中的第 i 行第 j 列元素代表第 i 和第 j 个 token 是否是第 k 个实体类型的 start 和 and 的置信水平。
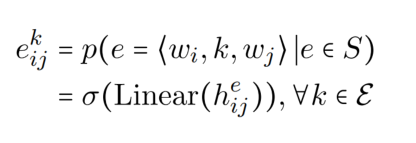
RE Unit
对于 RE 任务来说,只需要预测 wi 和 wj 是否是关系三元组中两个实体的 start,因为实体的 span 已经在 NER 中预测了。
同样的,论文将 RE 也转化为了填表问题,每一个关系类型对应一张表,第 l 个关系类型中第 i 行第 j 列元素代表第 i 和 第 j 个 token 是否是 subject 和 object 的 start 的置信水平。
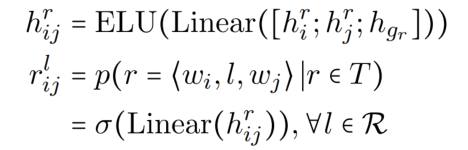
Training
loss 函数使用 BCE,分别计算 NER 和 RE 的损失,总的损失是两个部分的损失加起来。
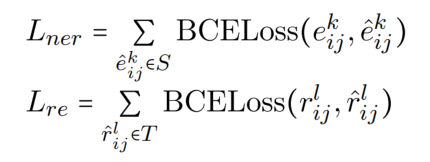
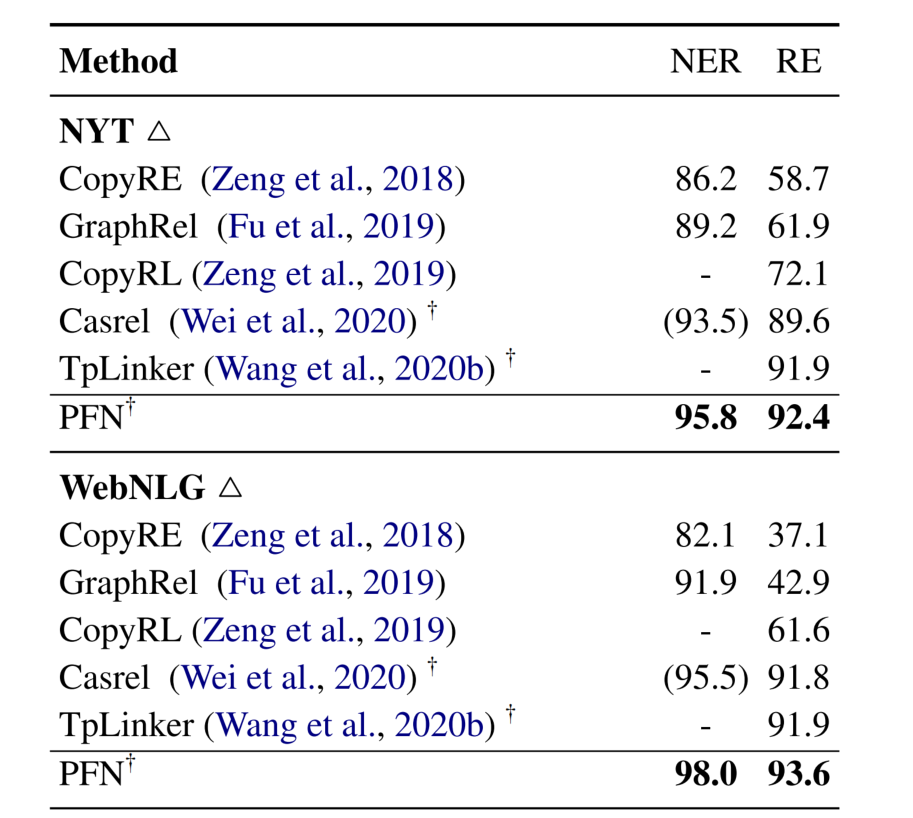
实验结果
Main Result
NYT 和 WebNLG 只标注了实体的 end 位置,在 WebNLG 数据集上,比 SOTA TpLinker 提升了 1.7%,而在 NYT 数据集上只提升了 0.5%,作者认为这是因为 NYT 是利用远程监督生成的,所以实体和关系的标注可能是不完全的或者错误的。与 TpLinker 相比,作者的方法的优势是加强实体和关系之间的双向交互。然而,当处理有噪声的数据时,由于在两个任务之间,错误的传播也会被放大。对于 NER 来说,与 CasRel 相比,在 NTY 和 WebNLG 中 F1 得分高出 2.3% 和 2.5%,这说明将关系信息暴露给 NER 提高了关系识别的表现。
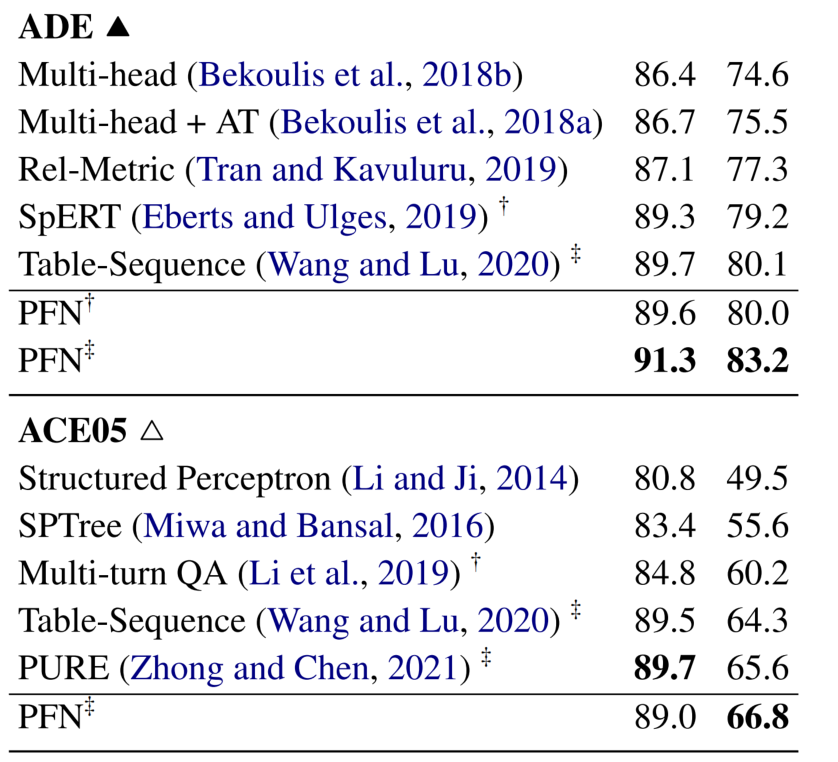
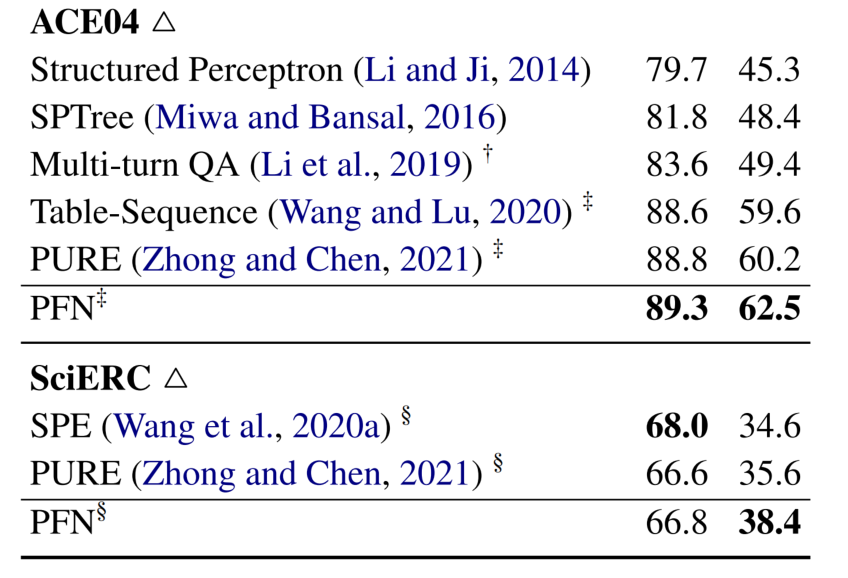
在完全标注实体 span 的数据集 ADE、ACE05、ACE 04 和 SciERC 上,都表现的很好。值得注意的是,在 ACE05 的 NER 任务上比 PURE 的表现低了 0.7%,作者归因于 ACE05 包含许多不属于任何关系三元组的实体。因此,利用关系信息进行实体预测可能不像其他数据集那样有效(PURE 是一种管道方法,在实体预测中是看不到关系信息的)。
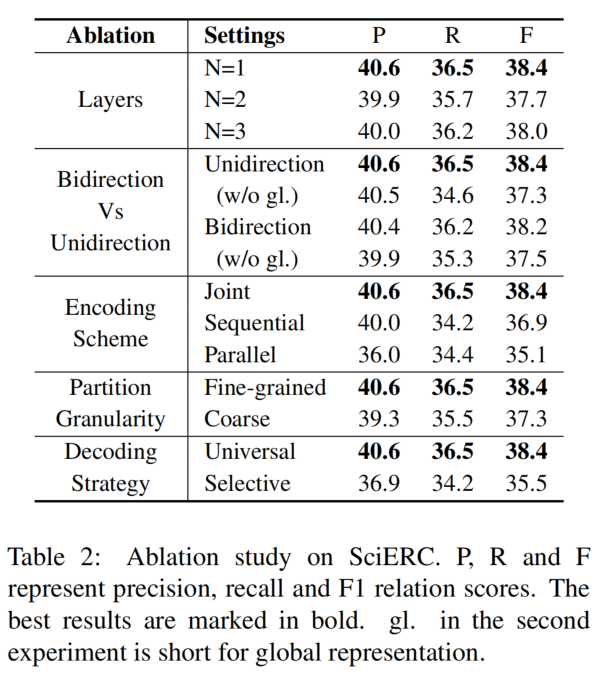
消融实验
从 encoder 的层数、双向与单向、编码方案、分区粒度和解码策略对模型的有效性进行判断。
- encoder 层数:一层已经足以表示 task-specific features。
- 双向与单向:带有 global representation 的单向编码器与双向编码器是差不多的,所以 global representation 已经足以获取到上下文语义信息。
- 编码方案:用两个 LSTM 来替换论文中的 partition filter encoder,在 Parallel 中除了共享输入外分别学习 task-specific feature,在 Sequential 中将第一个 LSTM 的输出输入到第二个 LSTM 中。实验结果表明,partition filter encoder 相比于 parallel 和 sequential 有比较大的优势。
- 解码方案:Selective 中只预测在 NER Unit 中有效实体的关系分数,Universal 预测所有的关系分数。包含所有负实例的 Universal 解码明显优于 Selective 解码。除了减少错误传播外,我们认为 Universal 解码类似于对比学习,因为负实例有助于通过隐式比较更好地识别正实例。