A Frustratingly Easy Approach for Entity and Relation Extraction
会议:NAACL 2021
作者:Zexuan Zhong, Danqi Chen
机构:Department of Computer Science Princeton University
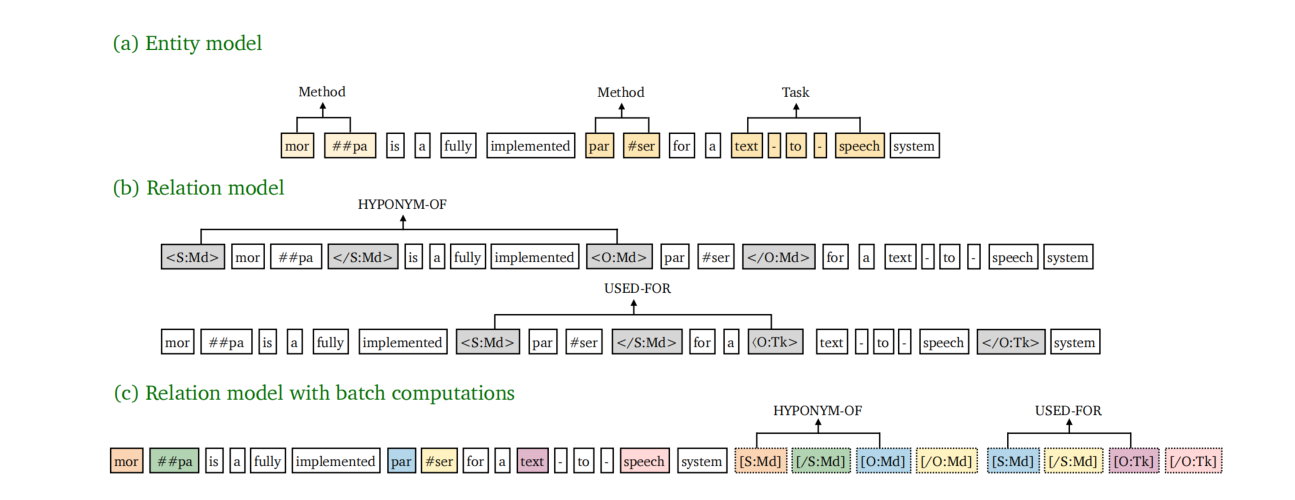
数据集:ACE04,ACE05,SciERC
共享:
- 提出了一种端到端 pipeline 的关系抽取模型 PURE(the Princeton University Relation Extraction system),分别为实体识别和关系分类学习两个独立的 encoder。
- 得到结论,为实体和关系学习不同的 contextual representations 比 joint 更为有效。
- 为了加快模型的推理时间,提出了一种新的有效近似方法。
将关系抽取分为实体识别和关系分类两个子任务,分别学习两个模型 entity model 和 relation model,论文发现:
- entity model 和 relation model 的 contextual representations 本质上捕获了不同的信息,所以共享 representations 可能对模型的表现有害(这与当前 Joint 方法的想法是相反的)。
- 在 relation model 的输入层中融合实体信息(边界和类型)是至关重要的。
- 利用跨句子信息在两个子任务中都是有效果的。
论文提出的模型有个缺点:
对每一对实体都会运行一次 relation model。为了缓解这一问题,论文提出了一种新的、有效的替代方法,即在推理时对不同的 groups of entity pairs 进行近似和批量计算。这种近似实现了 8-16 倍的加速,而精度略有降低。
模型结构
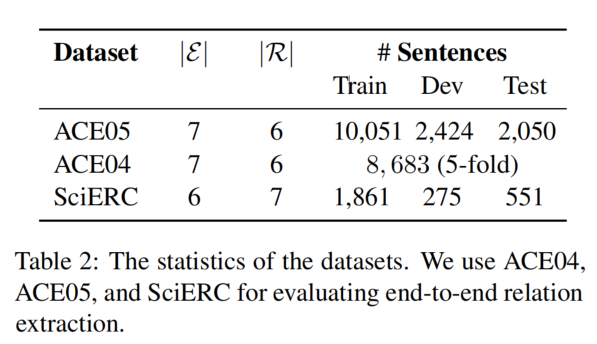
PURE 由 entity model 和 relation model 组成( relation model with batch computations 用于简化计算过程)。
Entity model

首先利用预训练模型获取每个 token 的上下文表示 contextualized representations,然后对于每一个 span 的 span representation 的计算如下(之后 span representation 会送入前馈神经网络预测实体类型):
即这个 span 的开始位置 token 的 embedding、结束位置 token 的 embedding 以及学习到的 span 宽度的 embedding(太长的 span 不太可能成为实体)这三个 embedding 的连接。

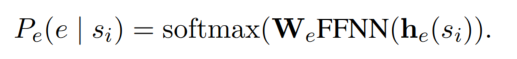
Relation model

relation model 使用一对 span 作为输入(两个 span 分别是 subject 和 object)并预测出一个关系类型。之前的方法复用了 span representations 去预测两个 span 之间的关系类型。
论文假设,这些 span representations 只捕获了每个单独实体周围的上下文信息,并且可能无法捕获这对 span 之间的依赖关系。论文还认为,在不同的 span 对之间共享 contextual representation 可能是次优的,因为不同的 span pair 需要关注不同的上下文信息。
论文的 relation model 中,独立地处理每对 span,并在句子中插入 typed markers,以突出显示 subject 和 object 及它们的类型。typed markers 的形式为 <S:subject类型></S:subject类型> 和 <O:object类型></O:object类型>。插入 typed markers 后的句子如下:
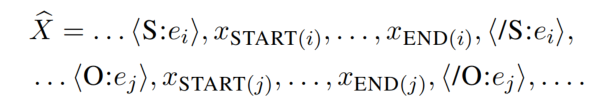
然后,对新生成的句子应用第二个预训练 encoder,并且得到了每一个 token 的 embedding。论文将两个 span 起始位置的 embedding 连接起来,形成了 span-pair representation(之后 span-pair representation 会送入前馈神经网络预测关系类型):

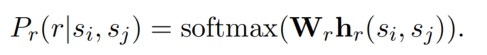
Cross-sentence context
Cross-sentence 信息可以用来帮助预测实体类型和关系,特别是在代词中。
在论文中,简单的通过在合并上下文句子输入到预训练模型中来获取 cross-sentence 信息。具体来说就是固定一个窗口长度为 W,若一个句子有 n 个单词,那么在左右两边分别增加 (W - n)/2 个单词来扩充输入,将输入的句子长度扩充到窗口 W 的大小。
Training
使用交叉熵损失来分别训练两个 models,在训练 relation model 时,输入的是 gold entitiys。
在推理时,只考虑实体类型不为 none 的实体,然后枚举每一对实体 span 输入到 relation model 中。
Efficient Batch Computation

在论文的原始模型中的一个缺点就是对于每一对实体,都要运行一次 relation model。问题的关键在于必须分别为每一对实体,都在句子中插入实体标签,导致无法并行计算。
所以提出了一种 approximation model,与原始的 relation model 有以下两个变化:
- 第一,不直接在原始句子中插入实体标签,而是让标签的 position embedding 等于对应实体的 start 和 end 的 position embedding(上图中,相同的颜色共享相同的 position embedding,这样等于共享 position ids)。这样,原始句子的 position embedding 就不会发生改变了。

- 第二,在 attention layer 中加入限制。即强行让 text tokens 只注意 text tokens 而不注意 marker tokens,而一个 entity marker token 可以注意所有的 text tokens 和相同实体对的 4 个 marker tokens。
在论文的实际实现中,将所有的 marker tokens 都加入到了句子的末尾。
在 batch = 2 的情况:

实验
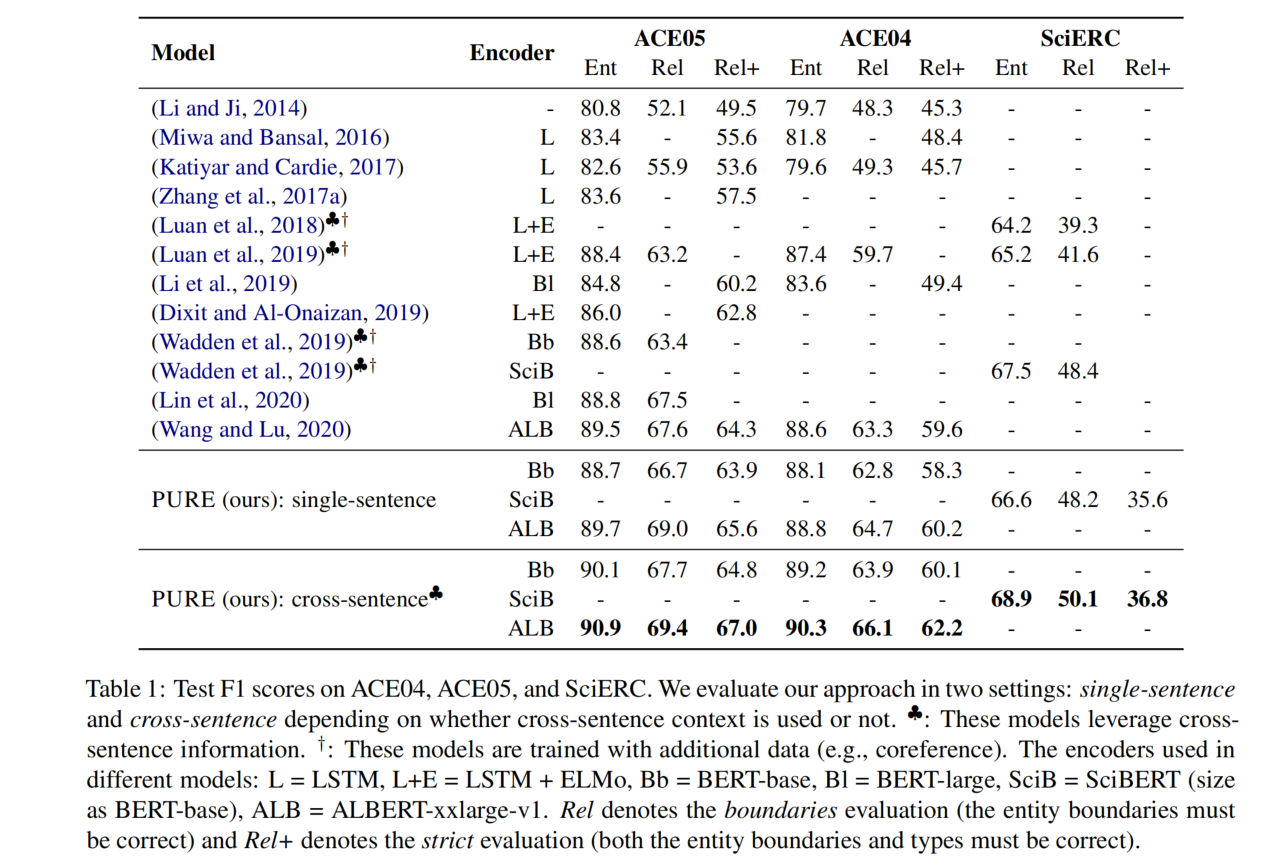
评价指标:
- 实体识别:当一个实体的 span 和类型都是正确的,就认为这个实体是正确的。
- 关系抽取:有两种指标
- Rel:当两个 span 和关系类型都是正确的,就认为这个关系是正确的。
- Rel+:除了 Rel 所要求的,还必须要求实体类型是正确的。
并行计算的效果: