Document-Level Relation Extraction with Adaptive Thresholding and Localized Context Pooling
会议:AAAI 2021
作者:Wenxuan Zhou, Kevin Huang, Tengyu Ma, Jing Huang
机构:Department of Computer Science, University of Southern California, Los Angeles
数据集:DocRED,CDR 和 GDA(CDR 和 GDA 是生物医学领域的数据集)
贡献:提出了一种关系抽取(不包括实体识别)模型 ATLOP(Adaptive Thresholding and Localized cOntext Pooling),这个模型解决了文档级关系抽取中的 multi-entity 问题和 multi-label 问题。
- 为了避免在不同的 entity pair 中,实体 embedding 相同的问题。论文引入了 localized context pooling,这增强了与当前 entity pair 相关的实体 embedding。
- 对于多标签问题,论文引入了 adaptive threshold 机制,提出了 adaptive-thresholding loss,即用一种 rank-based loss 训练,即将正类的 logits 推到阈值以上、负类的 logits 拉到很低。在测试阶段,返回所有高于阈值的类。这种方法不需要人为的对阈值(超参数)进行调优,也可以使阈值适应于不用的实体对。
对于 Document-level RE,有两个难题 multi-entity(在文档中出现了多个实体对)和 multi-label(一个特定的实体对之间存在多个关系)。在 DocRED 中如下:

模型结构
Basic Model
Encoder
用 BERT 作为预训练模型,在 entity mention 的开始和结束插入一个特殊的符号 *,用于标记 这一段是个 entity mention。对 entity mention 中 BERT 的 hidden states 做 logsumexp pooling 操作(这是一种平滑版本的 max pooling),得到实体的 embedding:
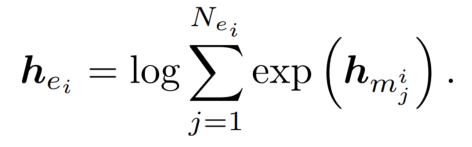
Binary Classifier
对于一对实体 embedding,需要计算他们之间有关系 r 的概率(首先进入线性层得到 z):
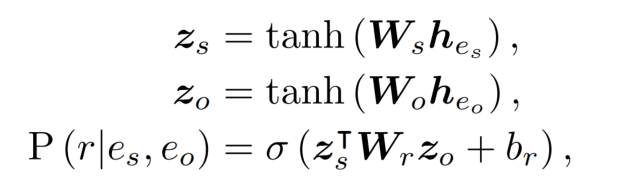
为了减少两个线性层的参数数量,使用 group 线性层,就是将实体 embedding 的维度分成 k 个相同大小的组,对这些组应用线性层:
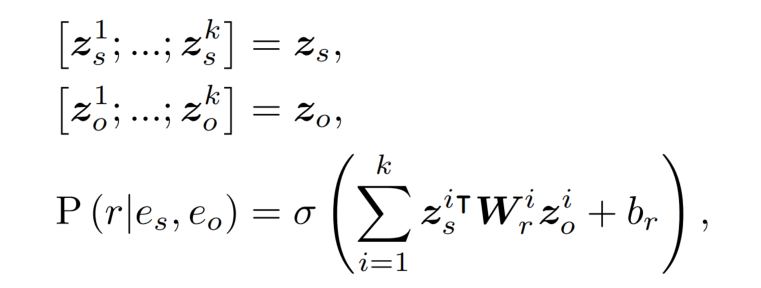
这样可以将参数的数量 d^2 减小到 d^2 / k。
Adaptive Thresholding
在之前的方法中,阈值是一个超参数。但是,对于不同的实体对以及类别之间,模型可能有不同的置信度,所以一个全局不可变的阈值显然是不够的。所以,论文提出了一种 adaptive thresholding 方法。
对于一个实体对,将这一个实体对的标签分为两个子集:
- 正类P:表示这个实体对之间有这样的关系。
- 负类N:表示这个实体对之间没有这样的关系。
如果一个实体对被正确的分类,那么正类的 logits 应该高于阈值并且负类的 logits 应该低于阈值。因此,引入了阈值类 TH,与 Binary Classifier 的计算方式相同(TH 学习了一个与 entity pairs 相关的阈值)。在推理时,返回高于 TH 的类,代表一对实体之间存在这样的关系。
为了训练 TH 类,设计了一种 adaptive-thresholding loss,这个损失函数分为两个部分:
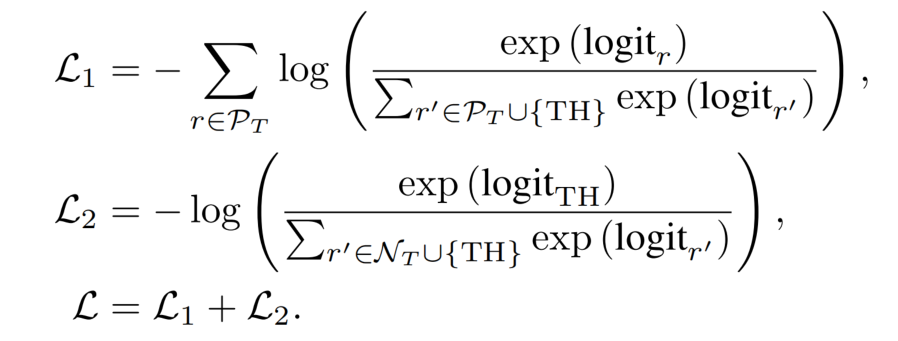
- 第一部分代表正类的损失,它使得所有的正类 logits 高于 TH 类。
- 第二部分代表负类的损失,它使得所有的负类 logits 低于 TH 类。
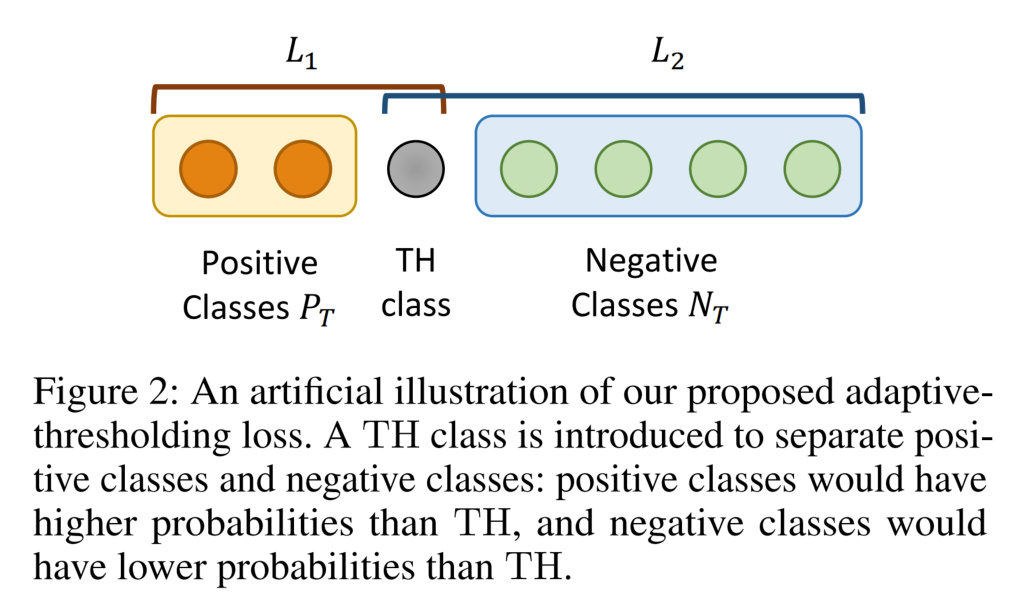
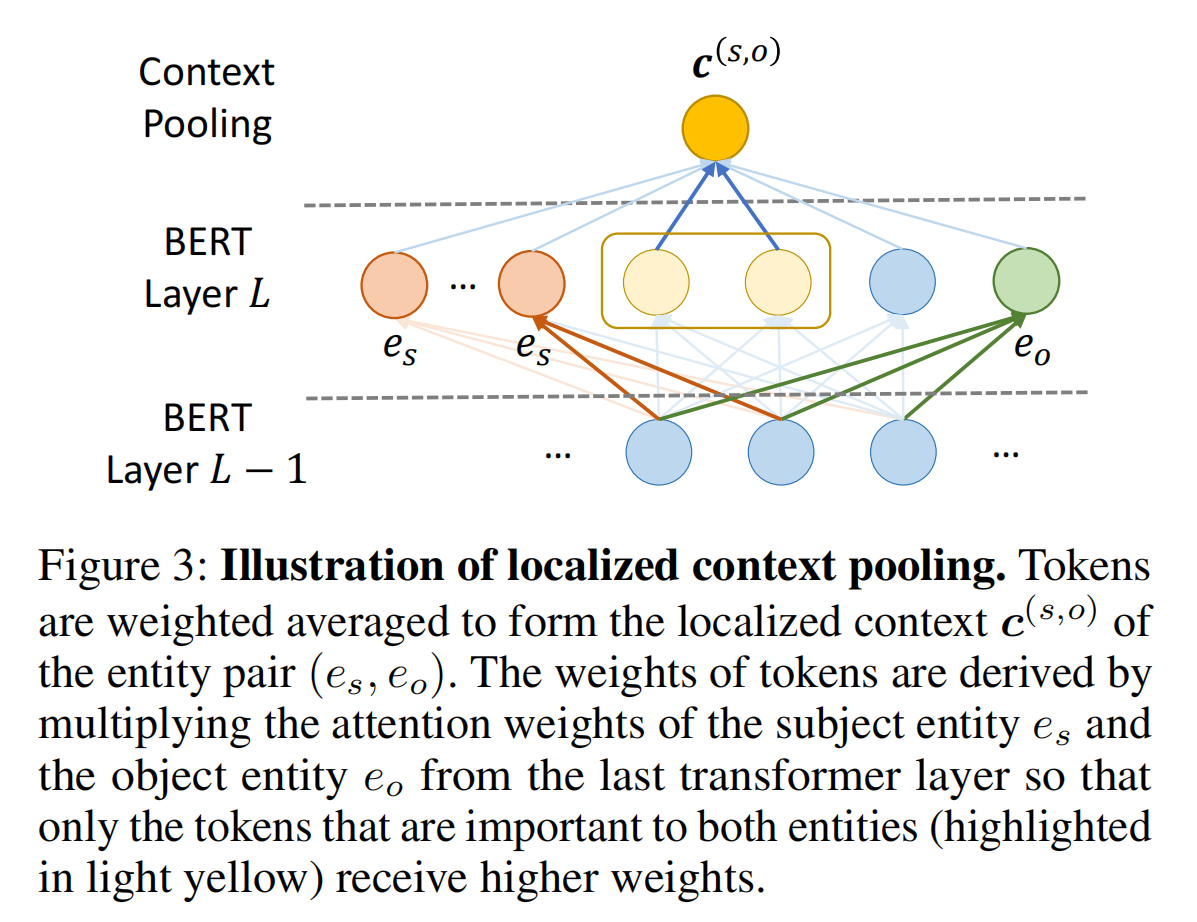
Localized Context
在基础模型中,使用了 logsumexp pooling 计算 entity embedding,这样的 embedding 使得同一个实体在不同的实体 pair 中的 embedding 是一样的。
然而,对于一个实体对,一些实体的上下文可能是不相关的(即两个实体之间是没有关系的)。因此,关注文档中相关上下文的 localized representation,对于判断实体对之间的关系很有帮助。论文设计了一个 localized context pooling,使用一个另外的与两个实体都相关的 local context embedding,来增强实体对的 embedding。local context embedding 为 c,计算如下:
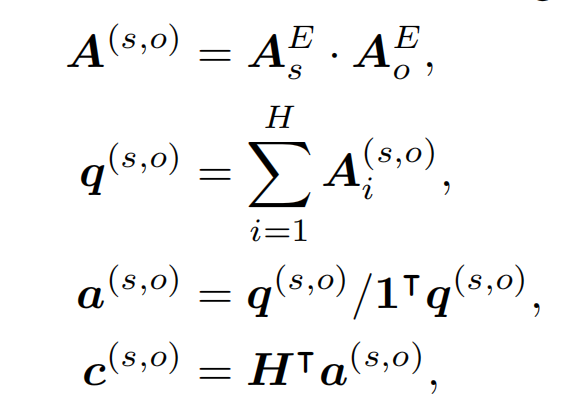
其中,A_s_E 表示 BERT 预训练模型 subject mention 输出的平均,维度为(bert_dim, seq_len)。H 为 BERT 的全部输出,所以本地上下文词嵌入 c 的维度为(bert_dim, 1)。对于 Binary Classifier 中 z 的计算,改为如下方式:
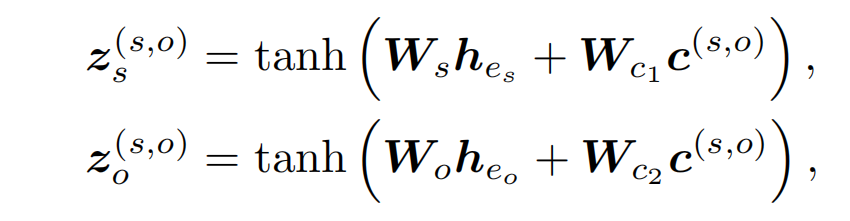
localized context pooling 的示意图如下所示:
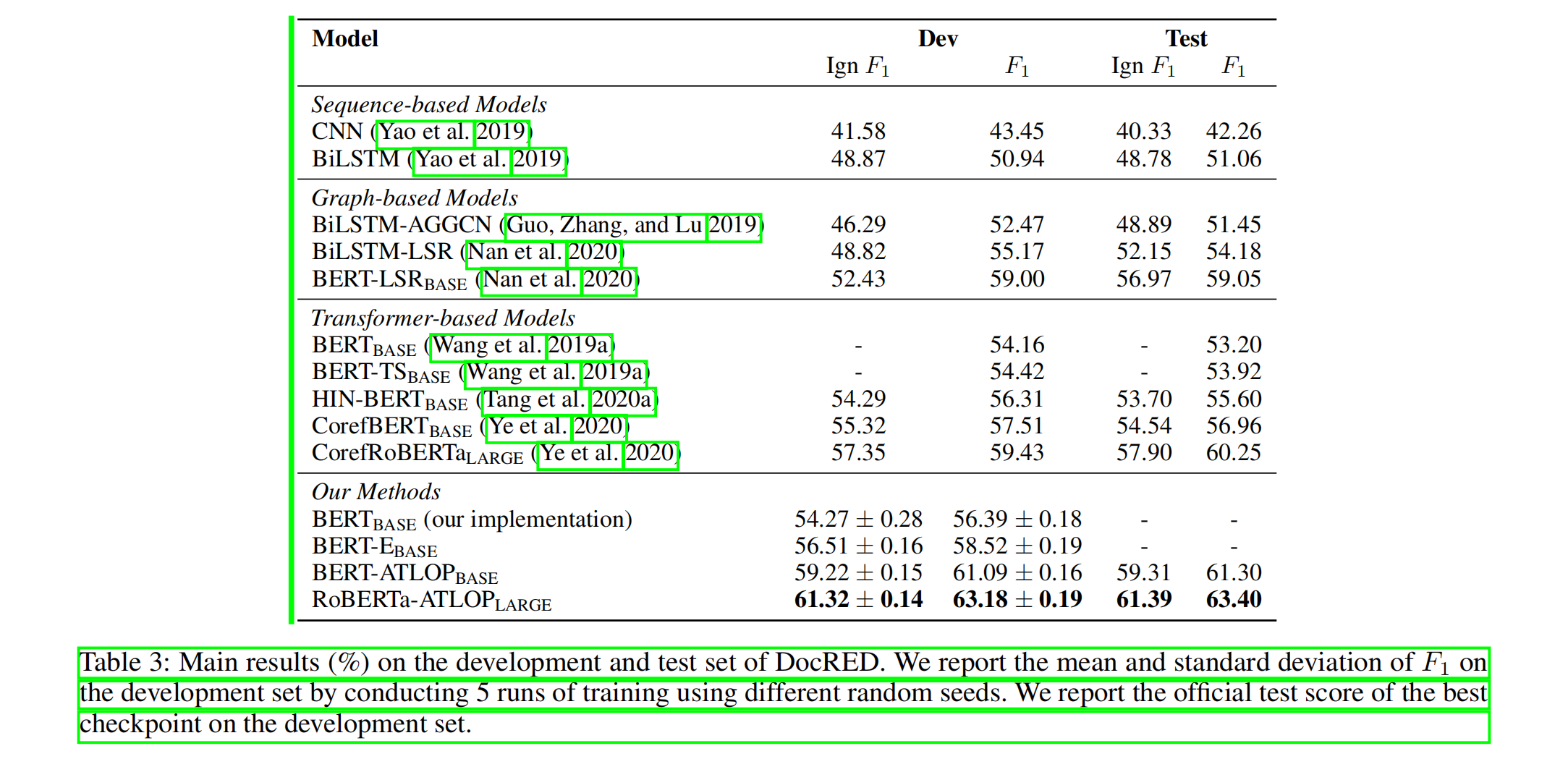
Experiments
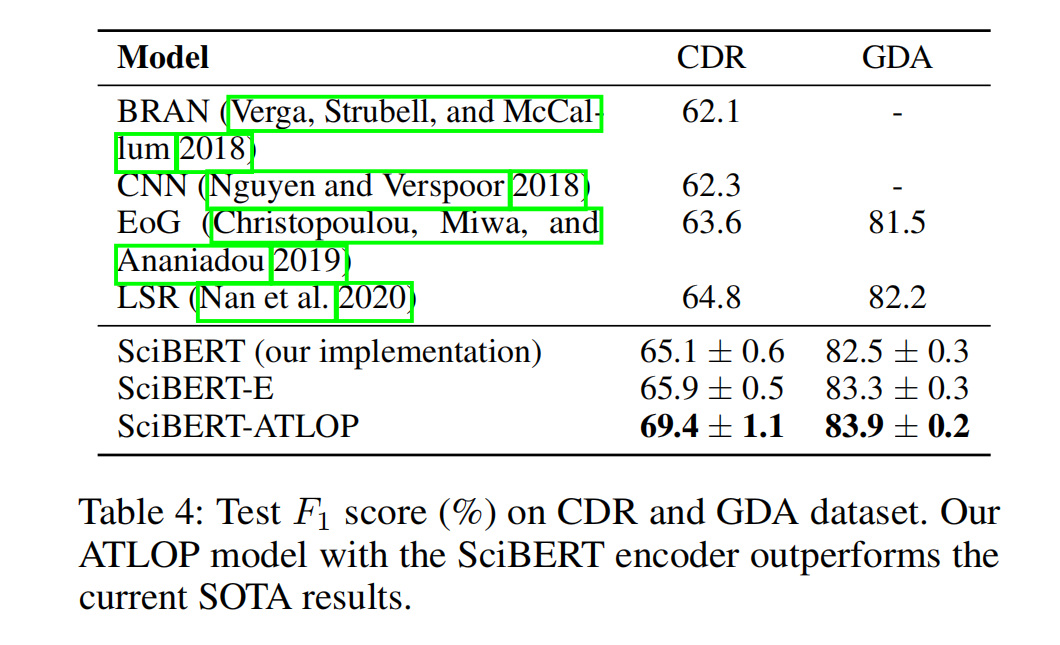
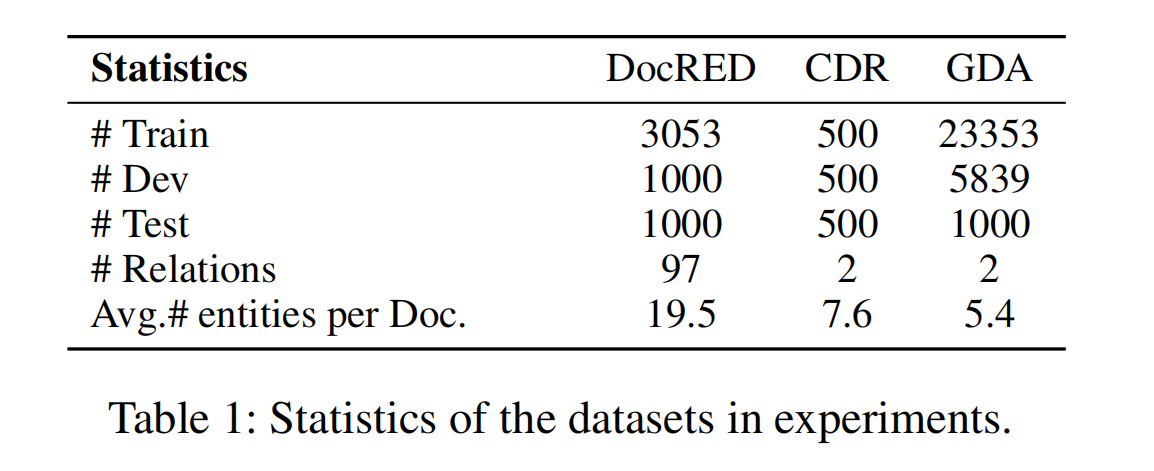
消融实验