IPRE: a Dataset for Inter-Personal Relationship Extraction
年份:2019
作者:Haitao Wang, Zhengqiu He, Jin Ma, Wenliang Chen, Min Zhang
机构:School of Computer Science and Technology, Soochow University, China
贡献:提出了用于人际关系抽取的数据集 Inter-Personal Relationship Extraction,IPRE,这是第一个用于提取人际关系的数据集。
- IPRE 有 41000 个标注的句子,包含 34 个关系类别(其中 9000 条句子是人工进行标注的)。
IPRE Dataset
论文首先通过远程监督的方法进行标注,然后再利用人工在测试集和验证集上进行标注(训练集占比 70,测试集 20,验证集 10)。
同一对人物实体被划分到同一个 bag 中,最终共标注了超过 41000 个句子 和 4214 个 bags。
下面是数据集的统计数据:
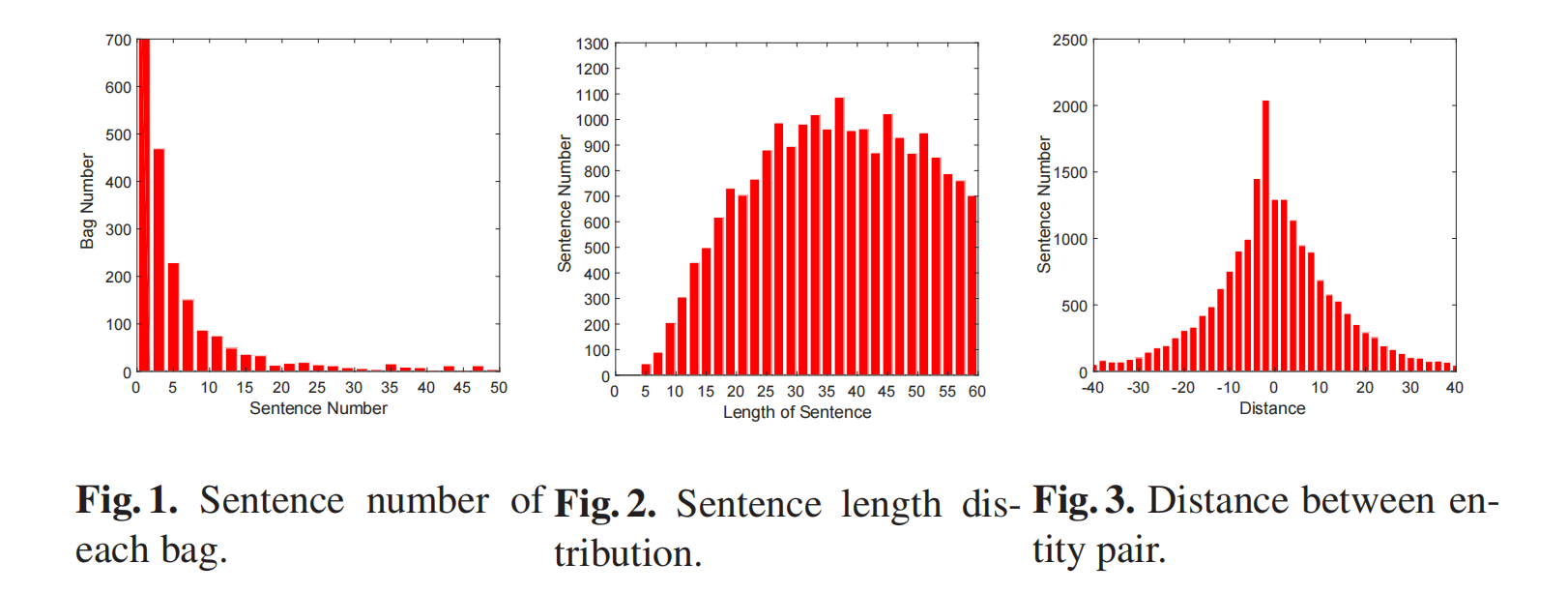
- 图 1 进一步给出了每个 bag 中所包含的句子数的分布直方图。虽然有些 bags 中只有一个句子,但大多数 bags 里的句子数在 2 到 15 个之间,这是一个非常合理的分布。
- 图 2 显示了句子长度的分布情况。为了尽可能保持句子的质量,我们在文本对齐部分的过程中将句子的长度限制在 60。从图中可以看出,句子的长度大多超过15。
- 图 3 中可以看出,在 IPRE 数据集中,大多数句子中两个实体之间的距离在 3-20 个单词之间,这是一个可以反映语义关系的合理距离。以往的许多研究表明,同一句子中两个实体之间的距离越近,句子越有可能反映实体对的语义关系。