目前有如下两个问题:
- 容量不够,Redis 如何进行扩容。
- 并发写操作,Redis 如何分摊操作。
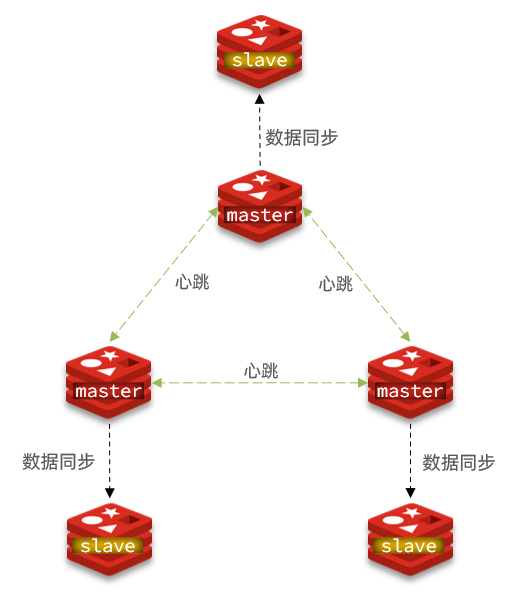
解决方法:无中心化集群。
Redis集群
Redis 集群实现了对 Redis 的水平扩容,即启动 N 个 Redis 节点,将整个数据库分布存储在这 N 个节点中,每个节点存储总数据的 1/N。
Redis 集群通过分区(partition)来提供一定程度的可用性(availability): 即使集群中有一部分节点失效或者无法进行通讯, 集群也可以继续处理命令请求。
开启集群
开启集群的步骤:
- 为集群中的每一个 Redis 服务器编写配置文件,并开启 Redis 服务。
- 启动集群,用
redis-cli --cluster create命令将节点合并成一个集群(一个集群中至少 3 个主节点)。
1 | redis-cli --cluster create --cluster-replicas 1 <Redis地址1> <Redis地址2> <Redis地址3> ... |
- 访问集群时,需要给
redis-cli加上-c参数才可以:
cluster node命令:查看集群信息。
slots
一个 Redis 集群包含 16384 个插槽(hash slot), 数据库中的每个 key 都属于这 16384 个插槽的其中一个, 集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽,集群中的每个节点负责处理一部分插槽。
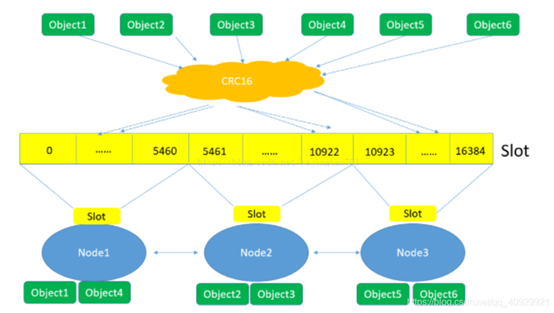
节点之间也互相监听,一旦有节点退出或者加入,会按照 slot 为单位做数据的迁移。例如 Node1 如果掉线了,0-5640 这些 slot 将会平均分摊到 Node2 和 Node3 上,由于 Node2 和 Node3 本身维护的 slot 还会在自己身上不会被重新分配,所以迁移过程中不会影响到 5641-16384 slot段的使用。
不在一个 slot 下的键值,是不能使用 mget、mset 等多键操作。
可以通过 {} 来定义组的概念,从而使 key 中 {} 内相同内容的键值对放到一个 slot 中去。


故障恢复
如果主节点下线,如果超过配置文件中配置的节点超时时间(cluster-node-timeout 选项配置),从节点就会自动升为主节点。主节点恢复后,主节点回来变成从机。
如果某一段插槽的主从节点都挂掉,而 cluster-require-full-coverage 为 yes :整个集群都挂掉;
如果某一段插槽的主从节点都挂掉,而 cluster-require-full-coverage 为 no :该插槽数据全都不能使用,也无法存储。