// Expected check whether given item is equals to expected value type Expected func(a interface{})bool
// Consumer traverses list. // It receives index and value as params, returns true to continue traversal, while returns false to break type Consumer func(i int, v interface{})bool
type List interface { Add(val interface{}) Get(index int) (val interface{}) Set(index int, val interface{}) Insert(index int, val interface{}) Remove(index int) (val interface{}) RemoveLast() (val interface{}) RemoveAllByVal(expected Expected) int RemoveByVal(expected Expected, count int) int ReverseRemoveByVal(expected Expected, count int) int Len() int ForEach(consumer Consumer) Contains(expected Expected) bool Range(start int, stop int) []interface{} }
// find returns page and in-page-offset of given index func(ql *QuickList)find(index int) *iterator
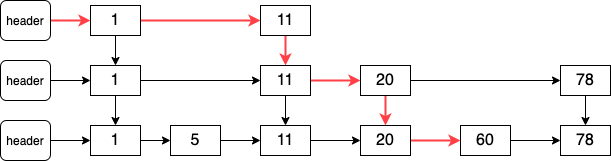
其流程为:
首先查看 index 在快速链表的前半部分还是后半部分。若在前半部分,则从前向后查找。
从前向后查找,找到 index 所在的 page,pageBeg 表示这个 index 所在 page 之前的元素个数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14
if index < ql.size/2 { // search from front n = ql.data.Front() pageBeg = 0 for { // assert: n != nil page = n.Value.([]interface{}) if pageBeg+len(page) > index { break } pageBeg += len(page) n = n.Next() } }
若 index 在快速链表的后半部分,则从后向前查找。
1 2 3 4 5 6 7 8 9 10 11 12 13
else { // search from back n = ql.data.Back() pageBeg = ql.size for { page = n.Value.([]interface{}) pageBeg -= len(page) if pageBeg <= index { break } n = n.Prev() } }
计算这个 index 在 page 中的相对位置 offset,返回迭代器。
1 2 3 4 5 6
pageOffset := index - pageBeg return &iterator{ node: n, offset: pageOffset, ql: ql, }
// Set updates value at the given index, the index should between [0, list.size] func(ql *QuickList)Set(index int, val interface{}) { iter := ql.find(index) iter.set(val) }
Add 在尾部插入数据
Add 用于在快速链表的尾部插入数据。
1 2
// Add adds value to the tail func(ql *QuickList)Add(val interface{})
func(ql *QuickList)Insert(index int, val interface{})
其流程如下:
若插入到最后,则调用 Add 进行末尾上的插入。
1 2 3 4
if index == ql.size { // insert at ql.Add(val) return }
找到 index 所在的 page,若 page 没有满,则直接插入到 page 的相应位置上并返回。
1 2 3 4 5 6 7 8 9 10
iter := ql.find(index) page := iter.node.Value.([]interface{}) if len(page) < pageSize { // insert into not full page page = append(page[:iter.offset+1], page[iter.offset:]...) page[iter.offset] = val iter.node.Value = page ql.size++ return }
若 page 满了,则将一个满的 page 分裂成两个 page。
1 2 3 4
// insert into a full page may cause memory copy, so we split a full page into two half pages var nextPage []interface{} nextPage = append(nextPage, page[pageSize/2:]...) // pageSize must be even page = page[:pageSize/2]
若迭代器的 offset 在前半部分则在第一个 page 上插入;否则在第二个位置上插入数据。
1 2 3 4 5 6 7 8 9 10 11 12
if iter.offset < len(page) { page = append(page[:iter.offset+1], page[iter.offset:]...) page[iter.offset] = val } else { i := iter.offset - pageSize/2 nextPage = append(nextPage[:i+1], nextPage[i:]...) nextPage[i] = val } // store current page and next page iter.node.Value = page ql.data.InsertAfter(nextPage, iter.node) ql.size++
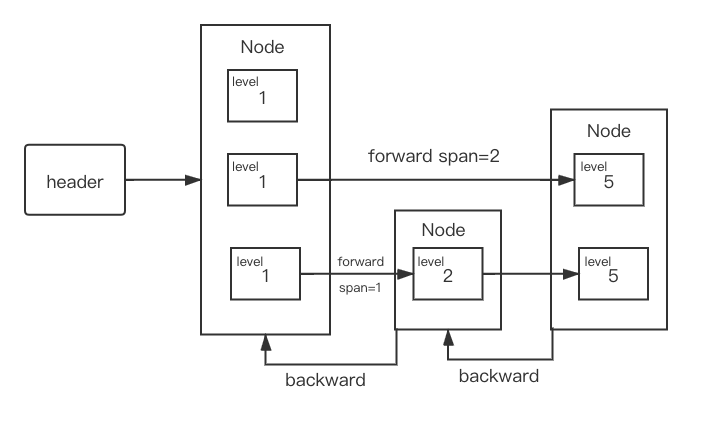
func(skiplist *skiplist)getByRank(rank int64) *node { var i int64 = 0 n := skiplist.header // scan from top level for level := skiplist.level - 1; level >= 0; level-- { for n.level[level].forward != nil && (i+n.level[level].span) <= rank { i += n.level[level].span n = n.level[level].forward } if i == rank { return n } } returnnil }
getFirstInScoreRange
skiplist.getFirstInScoreRange 方法用于查找分数范围内的第一个节点。
1
func(skiplist *skiplist)getFirstInScoreRange(min *ScoreBorder, max *ScoreBorder) *node
n := skiplist.header // scan from top level for level := skiplist.level - 1; level >= 0; level-- { // if forward is not in range than move forward for n.level[level].forward != nil && !min.less(n.level[level].forward.Score) { n = n.level[level].forward } }
查找结束,此时 n.level[0].forward 节点一定是范围内的第一个节点。
1 2 3 4 5
n = n.level[0].forward if !max.greater(n.Score) { returnnil } return n
// find position to insert node := skiplist.header for i := skiplist.level - 1; i >= 0; i-- { if i == skiplist.level-1 { rank[i] = 0 } else { rank[i] = rank[i+1] // store rank that is crossed to reach the insert position } if node.level[i] != nil { // traverse the skip list for node.level[i].forward != nil && (node.level[i].forward.Score < score || (node.level[i].forward.Score == score && node.level[i].forward.Member < member)) { // same score, different key rank[i] += node.level[i].span node = node.level[i].forward } } update[i] = node }
随机决定新节点的层数,若新的节点层数大于当前跳表的最高层数,则创建新的层。
1 2 3 4 5 6 7 8 9 10
level := randomLevel() // extend skiplist level if level > skiplist.level { for i := skiplist.level; i < level; i++ { rank[i] = 0 update[i] = skiplist.header update[i].level[i].span = skiplist.length } skiplist.level = level }
// make node and link into skiplist node = makeNode(level, score, member) for i := int16(0); i < level; i++ { node.level[i].forward = update[i].level[i].forward update[i].level[i].forward = node
// update span covered by update[i] as node is inserted here node.level[i].span = update[i].level[i].span - (rank[0] - rank[i]) update[i].level[i].span = (rank[0] - rank[i]) + 1 }
// RemoveByRank removes member ranking within [start, stop) // sort by ascending order and rank starts from 0 func(sortedSet *SortedSet)RemoveByRank(start int64, stop int64)int64 { removed := sortedSet.skiplist.RemoveRangeByRank(start+1, stop+1) for _, element := range removed { delete(sortedSet.dict, element.Member) } returnint64(len(removed)) }