A Simple yet Effective Relation Information Guided Approach for Few-Shot Relation Extraction
年份:2022
会议:ACL
作者:Yang Liu, Jinpeng Hu, Xiang wan, Tsung-Hui Chang
机构:The Chinese University of Hong Kong
数据集:FewRel 1.0
motivation:在 few-shot 关系抽取任务上应用原型网络有两个限制,因此论文提出了一种直接而有效的方法将关系信息融合进网络之中。
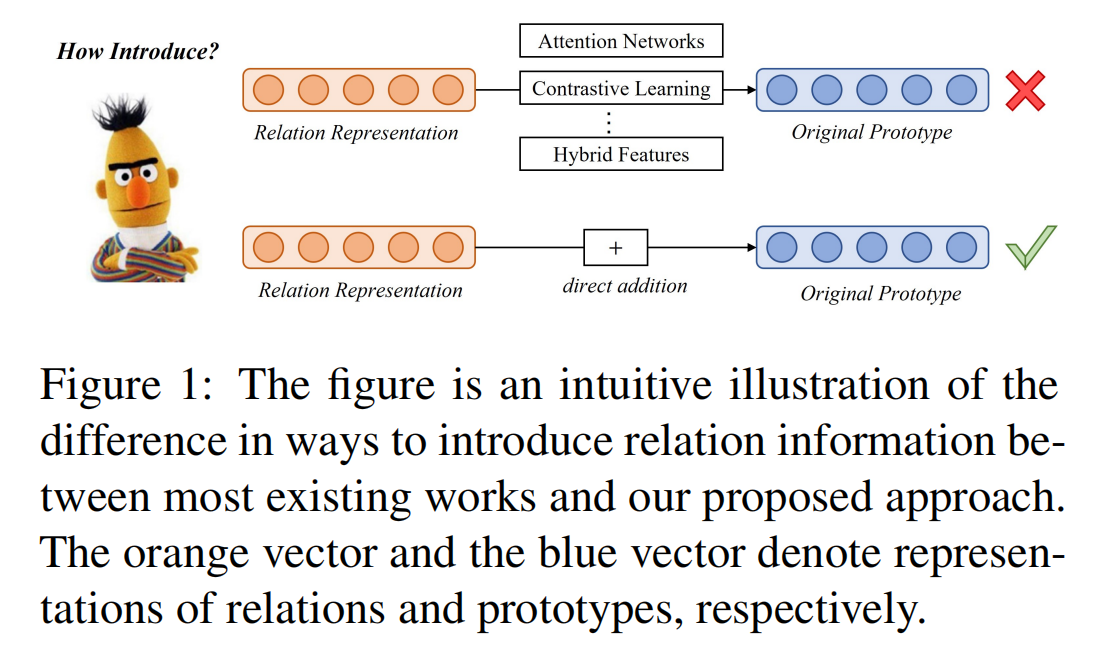
- 局限一:现有模型中的大多数都采用了隐式约束,如对比学习或者关系图,而不是直接融合关系信息到网络中。这会导致在面对 remote samples 时,表现较弱。
- 局限二:它们通常采用复杂的设计或网络,如混合特征或精心设计的注意力网络,这可能会带来太多甚至是有害的参数。
- 论文中的具体做法是:
- 使用相同的编码器来编码关系信息和句子,并将它们映射到相同的语义空间中。
- 通过连接两个关系视图(比如 CLS token embedding 和所有 tokens 的平均)来为每个关系类生成关系表示 relation representation,这使得关系表示和原型有相同的维度。然后,将生成的关系表示直接与原型相加。
因为关系抽取数据集人工标注困难,所以开始研究 Few-Shot Relation Extraction(FSRE)。这个任务在现有关系的大规模数据集上进行训练,然后快速迁移到新关系类型的少量数据上。
原型网络(Prototypical Networks)是 Few-Shot 的方法,就是先把样本投影到一个空间,计算每个样本类别的中心,在分类的时候,通过对比目标到每个中心的距离,从而分析出目标的类别。
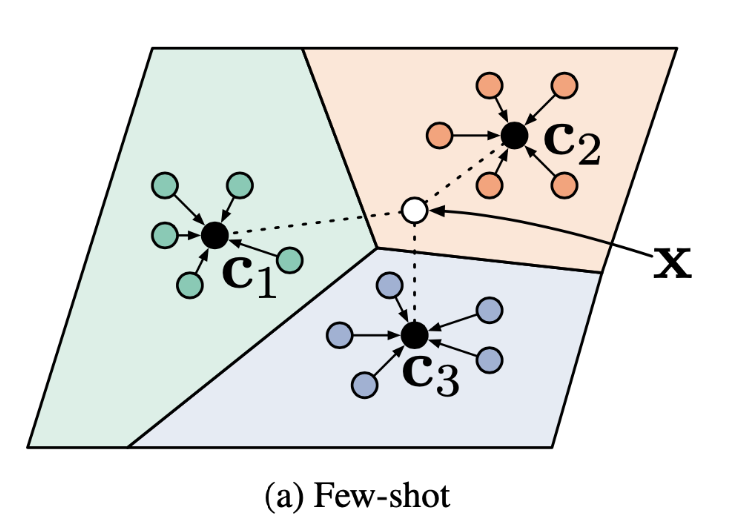
原型网络具体实现就是:
- 首先是把输入投影到新的特征空间,通过神经网络,把输入转化为一个新的特征向量,使得同一类的向量之间的距离比较接近,不同类的向量距离比较远。
- 计算每个类别的均值表示该类的原型。
针对现有方法在 RE 上应用原型网络的两个缺陷,论文提出通过连接两个关系视图(比如 CLS token embedding 和所有 tokens 的平均)来为每个关系类生成关系表示,这使得关系表示和原型有相同的维度。然后,在训练和预测时将生成的关系表示直接与原型相加。至于为什么直接相加的方法适用于 few-shot RE,作者是这样解释的:
- 直接相加更具有鲁棒性,在面对 remote samples 时。
- 直接相加不会带来额外的参数,简化了模型。由于过拟合的问题,较少的参数总是比较多的参数更好,特别是对于较少数据量的任务。
模型结构
最重要的是以下两个部分:
为了将句子和关系信息的表示映射到同一语义空间中,使用了共享句子编码器。
接着连接两个关系表示的两个视图,用于得到与原型相同的维度。通过直接加法,将关系表示集成到原始原型中
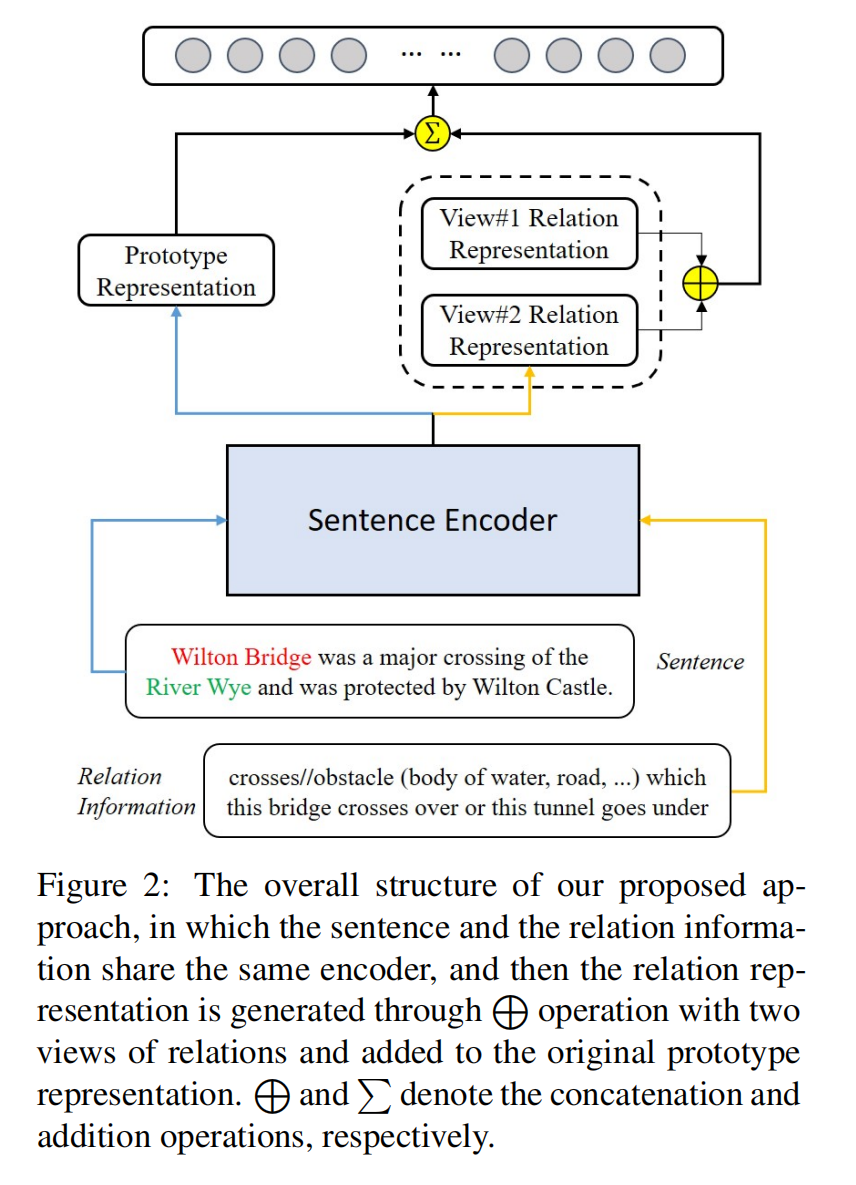
Sentence Encoder
论文应用了 BERT 作为共享编码器,编码器有两个作用一是编码句子生成原型,二是编码关系信息生成关系表示。
在编码句子时,将两个实体的开始 token embedding 连接起来作为中间状态,对于每一种关系类型都将相关的中间状态做平均,以生成对应的关系类型原型表示 Pi。
在编码关系信息时,连接关系名字和其描述信息作为一个句子输入到编码器中,将 CLS 和句子 token 的平均作为关系表示的两个视图。
Relation Representation Generation
将关系表示的两个视图连接起来,作为最终的关系表示(最终的关系表示与原型的维度是相同的):
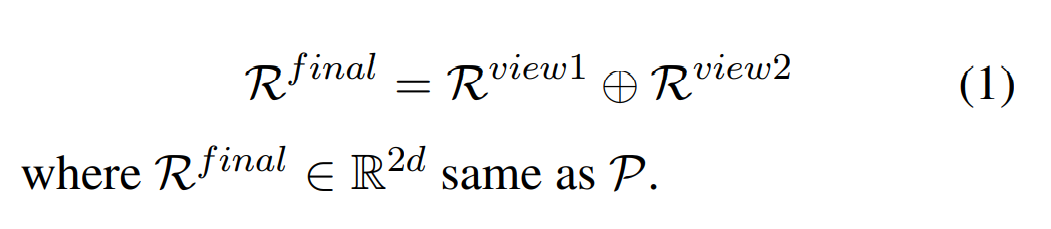
Relation Classification
最终的原型表示是初始原型与关系表示的加和:
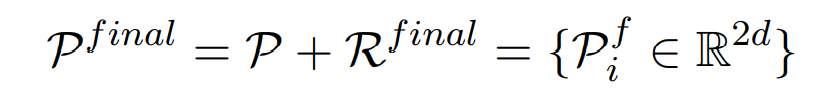
当预测时,使用点积去计算目标与原型的距离,选择最短距离作为预测结果。
实验
数据集
模型在 FewRel 1.0 上进行测试,这个数据集上包含 100 个关系类型,每一个关系类型包含 700 个带标注的实例。
实验结果