Consistent Representation Learning for Continual Relation Extraction
年份:2022
会议:ACL
作者:Kang Zhao, Hua Xu, Jianggong Yang, Kai Gao
机构:Tsinghua University, Beijing
motivation:连续关系抽取(Continual RE,CRE)目的是帮助模型学习新的关系,同时保持对旧关系的准确分类。以往的一些工作证明,存储一些新关系的典型样本并在学习新关系时重播,可以有效地避免遗忘。但是,这种方法有两个缺点:过拟合、在不平衡的数据集上表现不佳。为了解决这个问题,论文提出了一种一致表示学习方法,该方法在回放记忆时采用对比学习和知识蒸馏来保持 relation embedding 的稳定性。
当模型学习新任务时,持续的关系学习需要缓解旧任务的灾难性遗忘。因为神经网络在每次训练中都需要重新训练一组固定的参数,所以解决灾难性遗忘问题最有效的解决方案是存储所有的历史数据,并在每次出现一个新的关系实例时,用所有的数据重新训练模型。该方法在持续关系学习中取得最佳效果,但由于时间和计算功率成本的原因,没有在现实生活中被采用。
连续学习主要存在三个方法:
- 基于正则化(Regurgitation-based)的方法:限制了神经权重的更新。
- 动态架构(Dynamic architecture)方法:动态扩展模型架构,学习新任务,有效防止遗忘旧任务。然而,这些方法不适合NLP应用,因为模型的大小随着任务的增加而显著增加。
- 基于记忆(Memory-based)的方法:从旧任务中保存一些样本,并在新任务中不断学习它们,以缓解灾难性遗忘。
对比学习(CL)的目的是使相似样本的表示在嵌入空间中映射得更近,而不同样本的表示应该映射得更远。
方法
CRL 包括三个主要步骤,算法如下图所示:
- Init training for new task(4 ~ 11):通过监督对比学习,在新的数据集上训练 encoder 和 projector head(实际上是两层神经网络)的参数。
- Sample selection(12 ~ 13):对于新数据集上的每一个关系,检索关系中的每一个 sample 作为一个 cluster。对每一种关系都应用 k-means 算法,选择最接近中心的关系 representation,并存储在 cluster 的 memory 中。
- Consistent representation learning(16 ~ 23):为了在学习新关系后,保持历史关系嵌入在空间中的一致性,对 memory 中的 sample 进行了对比重放和知识精馏约束。



Encoder
Encoder(BERT)的输入为一个句子和一对实体 E1 和 E2。使用四个保留关键字,用于标记实体在句子中的开始和结束位置。将两个实体对应位置上的输出连接起来,得到高维 relation representation(也可以认为是 entity pair representation):
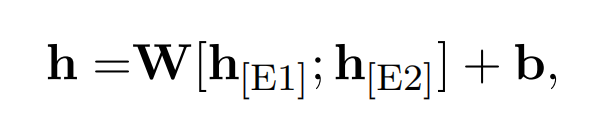
上述编码器记为 E。
然后,使用一个 projection head 获取低维度的 representation(用于分类),其中 Proj 表示两层的神经网络。
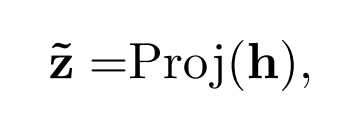
最后进行正则化后,得到的向量用于对比学习。
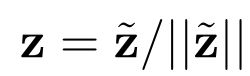
Initial training for new task
在开始训练新任务之前,首先利用 Encoder 提取新训练集中每句话的 relation representation,并且将之用于初始化临时 memory bank Mb:
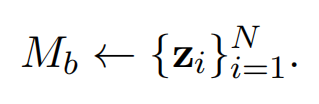
接着开始训练,对于每一个 batch 首先获取对应的 relation representation,接着通过监督对比学习聚类进行明确的约束(使得相同关系类型的 relation representation 尽量的接近,不同类型的 relation representation 距离远一些):

在每一次 batch 反向传播结束后,去更新在 memory bank 中的相应 representation Mb。
Selecting Typical Samples for Memory
为了使模型在学习新任务时不忘记对旧任务的相关知识,需要在 memory bank Mr 中存储一些样本 Sample,旧任务中的样本被存储到 Mr 中。使用 k-means 算法对每一种关系进行聚类,其中聚类的数量是需要为每个类存储的样本的数量(memory size)。然后,选取最接近中心的 relation representation,并存储在记忆中。
Consistent Representation Learning
在学习完新任务后,旧关系在空间中的 representation 可能会发生变化。为了使编码器在学习新任务的同时不改变旧任务的知识,论文提出了两种重放策略来学习一致性表示来缓解这一问题:对比重放和知识蒸馏。
Contrastive Replay with Memory Bank
在学习过新的知识过后,通过重播在 memory bank Mk 中的样本,使用与之前相同的监督对比学习聚类的方法,来进一步训练 Encoder(这里的不同之处在于,每个 batch 都使用整个 memory bank Mk 中的所有样本进行对比学习):

编码器可通过在记忆中回放样本,以减轻对之前学习到的知识的遗忘,同时巩固在当前任务中学习到的知识。
然而,对比重放允许编码器训练少量的样本,这有过拟合的风险。另一方面,它可能会改变前一个任务中关系的分布。因此,论文提出用知识蒸馏来弥补这一不足。
Knowledge Distillation for Relieve Forgetting
我们希望该模型能够保留历史任务中关系之间的语义知识。因此,在编码器训练任务之前,论文使用 relations in memory 之间的相似性度量作为记忆知识(Memory Knowledge),然后使用知识蒸馏来缓解模型对这些知识的遗忘。
具体来说,就是首先对记忆 Mk 中的样本进行编码,然后计算每个类的原型(每一个关系类型对应一个原型,原型的计算方法为这个关系类型中所有 relation representation 之和):
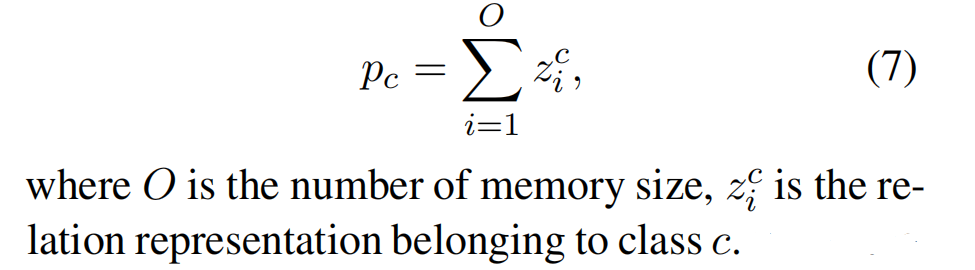
然后,计算关系类型之间的余弦相似度来表示在记忆中学习到的知识:
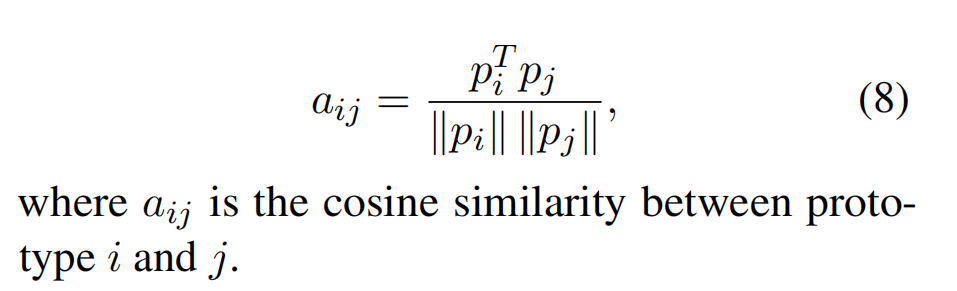
在执行记忆重放时,使用 KL 散度使编码器保留对旧任务的知识。

NCM for Prediction
为了预测测试样本 x 的标签,the nearest class mean(NCM)将 x 的嵌入与所有记忆原型进行比较,以最相似的原型对应的标签预测关系:

在预测过程中不需要额外的线性层,因此可以添加新的类别,而不需要结构的改变。
实验
实验是在两个基准数据集上进行的,训练、测试、验证比例为 3:1:1。
- FewRel:它是一个包含 80 个关系的 RE 数据集,每个关系都有 700 个实例。
- TACRED:它是一个大规模的RE数据集,包含 42 个关系(包括无关系)和 106264 个样本。与FewRel相比,TACRED 中的样品是不平衡的,所以每个关系的训练样本数量限制为 320 个,相关的测试样本数量限制为 40 个。
为了模拟不同的任务,论文将数据集的所有关系随机划分为 10 个集合来模拟 10 个任务。
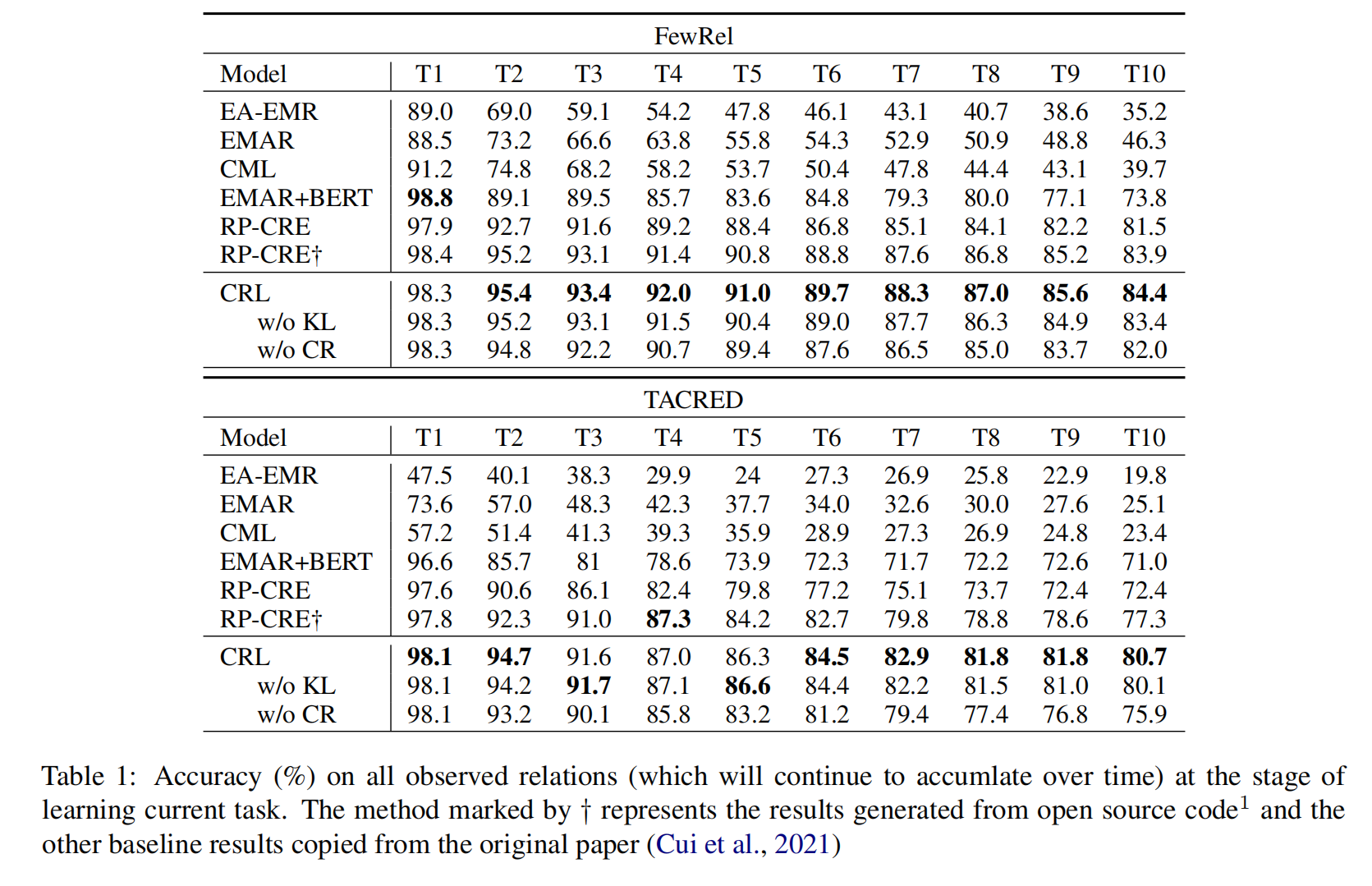
探究 memory size 对模型效果的影响,实验结果表明,memory size 对于模型的表现影响非常大,并且 memory size 越大效果越好。
