REBEL: Relation Extraction By End-to-end Language generation
年份:2021
会议:EMNLP
作者:Pere-Lluís Huguet Cabot, Roberto Navigli
机构:Sapienza University of Rome
motivation:在端到端的联合关系抽取中,通常模型很复杂、需要适应关系或者实体类型的数量(不够灵活)、无法处理不同性质的文本(句子和文档级别)、需要长时间的训练。
dataset:REBEL,一个利用自然语言推理、获得的大规模远程监督数据集。使用 REBEL 进行预训练。
REBEL
论文将关系抽取作为一个生成任务来处理,采用 seq2seq 模型,因此采用 BART 作为基础模型。
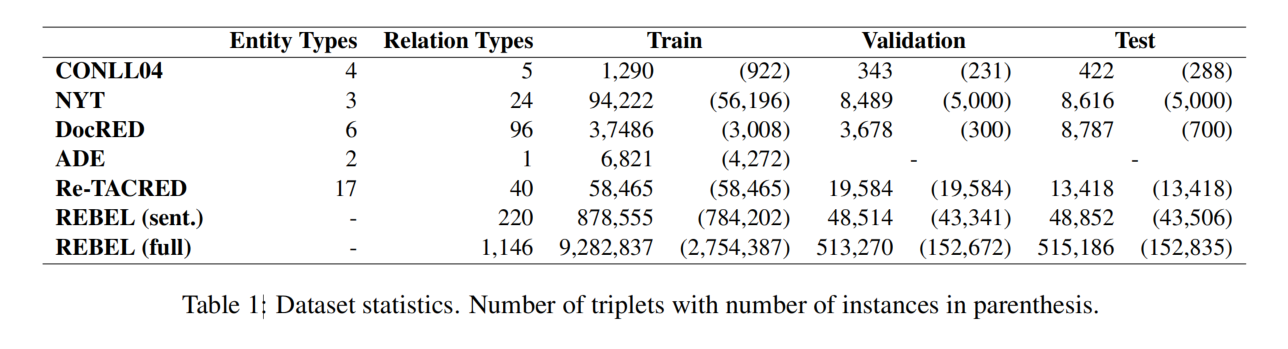
Triplets linearization
因为这是一个生成任务,所以需要将复杂的三元组结构(overlap 问题)转为线性的表示,从而将三元组转为一句话。同时,解码也需要简单。
为此,论文引入了三个特殊的标签:
- triplet:若干共享头实体的三元组的开始。
- subj:头实体的结束以及尾实体的开始。
- obj:尾实体的结束,以及表明头实体和尾实体的关系。
算法如下:

若需要预测实体类型,则不应该用 subj 和 obj 标签,而是实体类型标签(如 per 或者 org 等)。
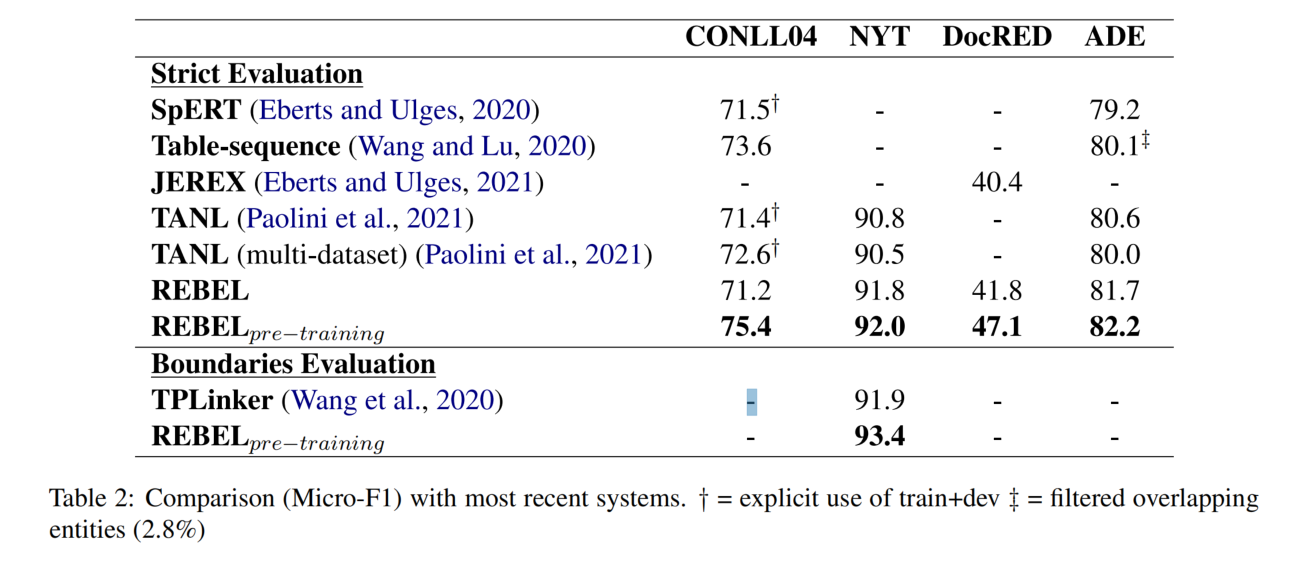
REBEL 数据集
自回归 transformer 模型,如 BART 或者 T5,在生成任务中表现良好,但是需要大量的数据来训练。
使用 REBEL 数据集对 BART 进行预训练。预训练的优势在于,可以快速迁移到其他数据集。
实验结果