Span-based Joint Entity and Relation Extraction with Transformer Pre-training
来源:ECAI 2021
作者:Markus Eberts, Adrian Ulges
贡献:提出了模型 Span-based Entity and Relation Transformer(SpERT)。
- 提出了一种基于 span 的联合实体和关系提取的新方法。
- 论文探究了模型成功的因素,结果表明:
- 来自同一句子的负样本产生既有效率又有效果的训练,足够数量的强负样本是至关重要的。
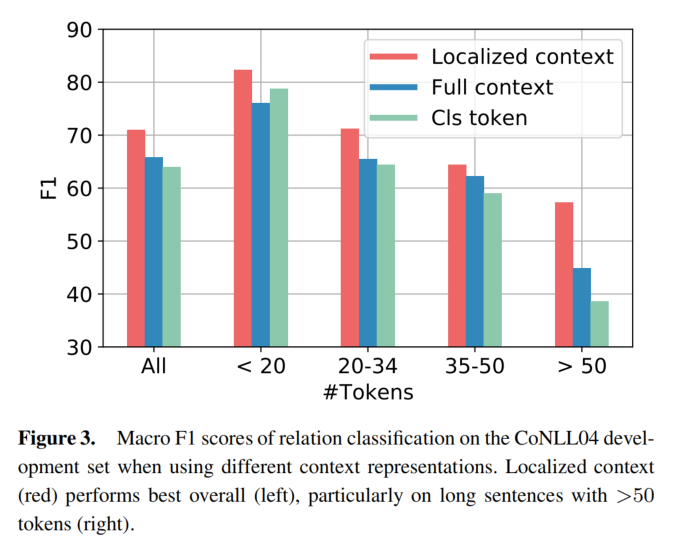
- 一个局部的上下文表示是有益的,特别是对于较长的句子。
- 对预训练的模型进行微调会比从头开始的训练产生很强的性能提高。
数据集:
- CoNLL04:从新闻中提取的带有命名实体识别和关系的句子。包含四类实体(地点、组织、人员、其他),以及物种关系类型(Work-For、Kill、Organization-Based-In,Live-In,Located-In)。包含训练集 1153 句话、测试集 288 句话。
- SciERC:来源于五百篇人工智能论文的摘要,这个数据集包含六种实体(Task,Method,Metric,Material,Other-Scientific-Term,Generic),以及七种关系(Compare,Conjunction,Evaluate-For,Used-For,Feature-Of,Part-Of,Hyponym-Of),共 2687 个句子。
- ADE:由 4272 个句子和 6821 个关系组成,这些关系描述了药物使用产生的不良反应。它包含一个单一的关系类型不良反应和两种实体类型不良反应和药物。
模型方法
SpERT 模型分为三部分:
- span classification
- span filtering
- relation classification
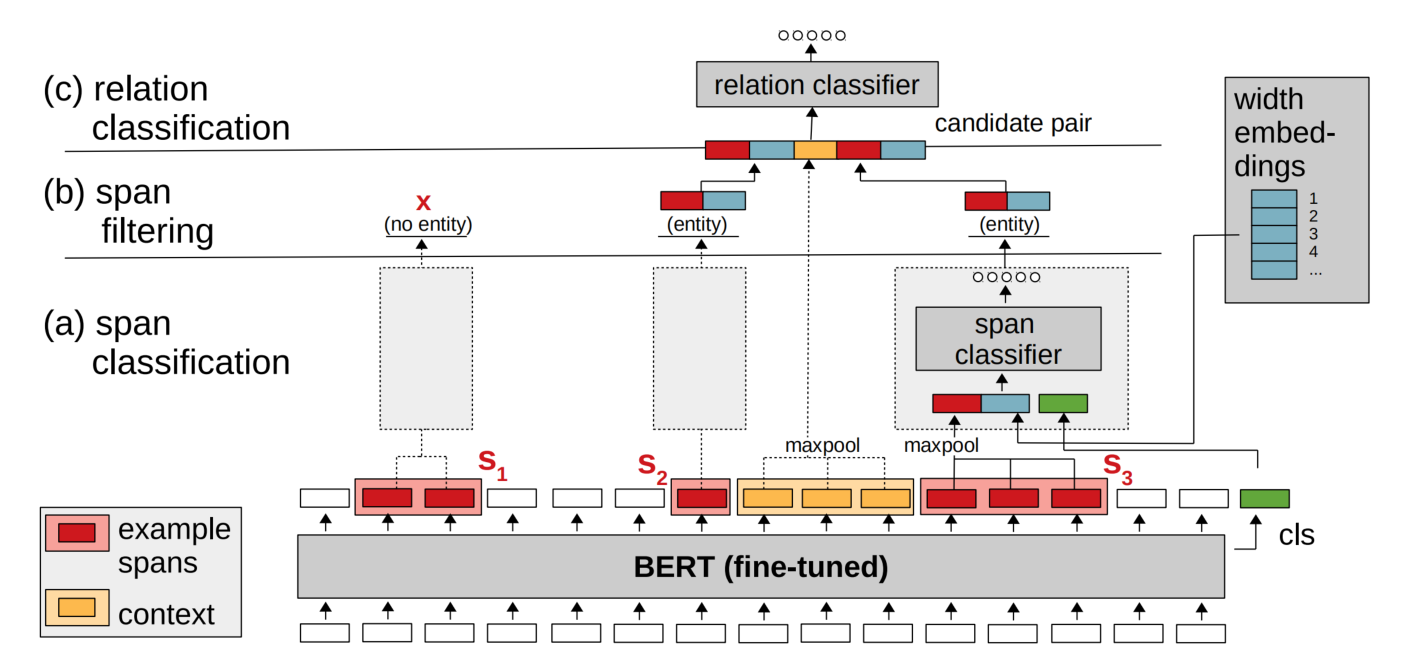
Span Classification
对于任意一个 span 作为输入,目标是进行实体分类(实体类型 + none)。其输入包含三个部分:
- 对这个 span 中所有 BERT 输出,利用融合函数进行融合。实验发现,最大池化的表现是最好的。
- span 对应的宽度 embedding,加入宽度嵌入的原因是跨度过长不太可能表示为实体。
- CLS 对应的嵌入,它代表整个句子的上下文表示。
将这三部分进行拼接,接着送入线性层、softmax 进行实体分类。
Span Filtering
论文采用了一种最简单的方法,直接将实体类型为 none 的 span 过滤掉。
Relation Classification
对于两个 span 进行的关系分类,需要得到 span pair 的表示。span pair 表示由以下组成:
- 两个 span BERT 输出后经过融合函数后得到的表示、宽度 embedding。
- 本地上下文表示(可以用 CLS,但是 CLS 不适合表达出多种关系的长句子,所以用更加本地化的方式),从第一个实体的结束到第二个实体的开始,接着送入融合函数(最大池化),就是本地上下文表示。如果这段为空(如遇到了 overlap),则将上下文表示设置为全零。
因为关系一般不是对称的,所以需要交换两个 span 的位置,分别进行分类。
Training
在训练时,采样方式如下:
- 对于 span classification:将所有的已经标记的实体作为正样本,随机选取一些 span 作为负样本。
- 对于 relation classification:将所有的 ground truth 作为正样本,在一句话中对于没有标记为任何关系的实体对作为负样本。
在训练过程中,只会过一遍 BERT,这样大大提高了训练速度。
实验
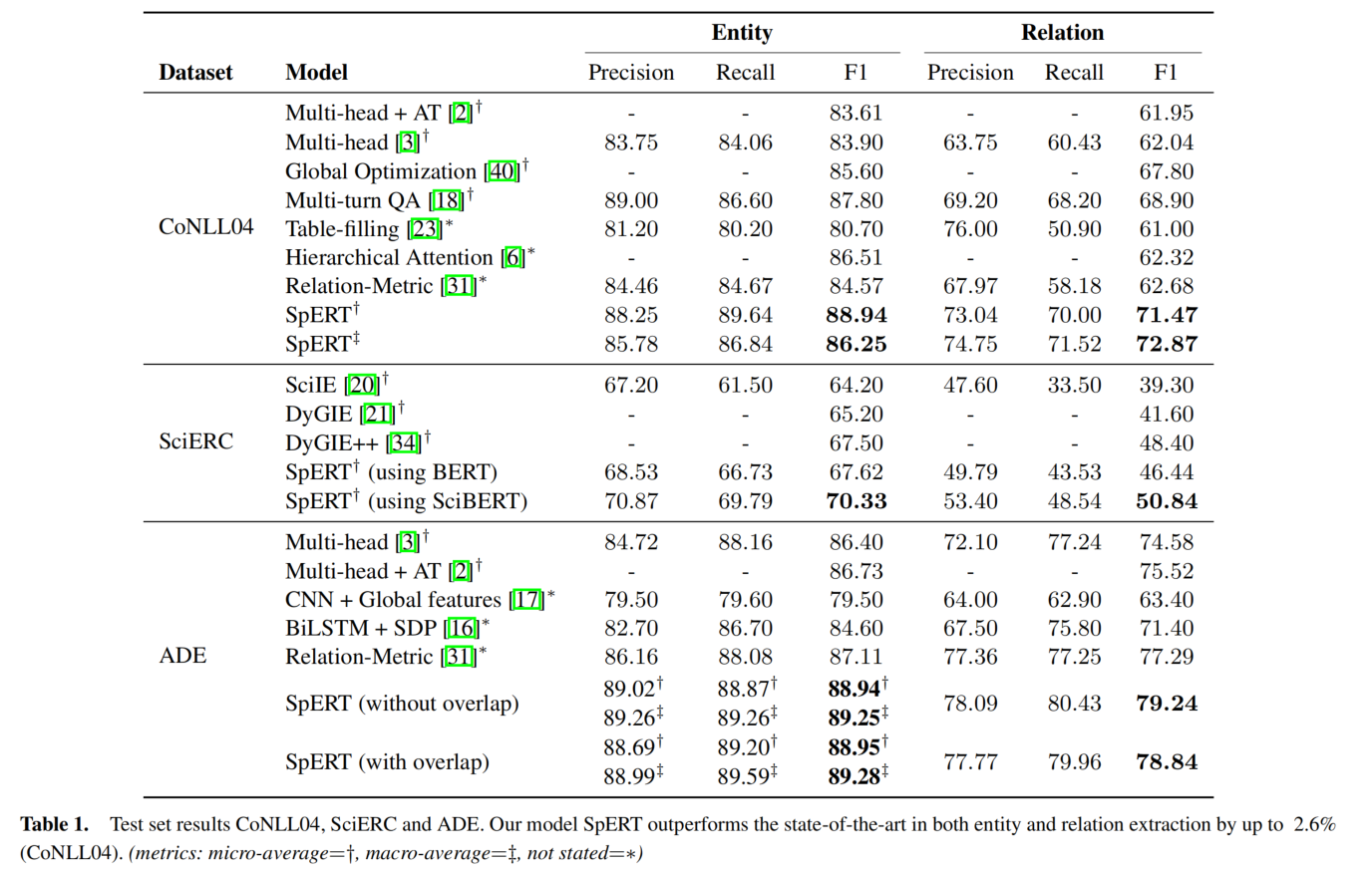
实验结果探究
negative sample
论文探究了 negative sample 对于实验结果的影响:发现当 negative sample 只有 1 时,SciERC 的 f1 仅仅只有 10,当 negative sample 数量为 20 时,f1 值达到了 50。这说明,negative sample 对于实验的结果影响非常大。
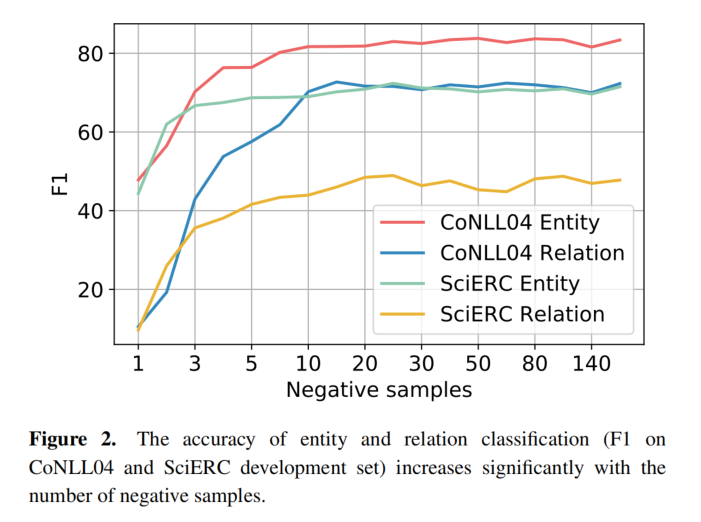
localized contex
论文比较了三种不同的上下文表示方式,发现局部上下文表示最好(尤其在长句子的场景下)。
fuse function