Continual Few-shot Relation Learning via Embedding Space Regularization
来源:ACL 2022
作者:Chenwei Qin, Shafiq Joty
机构:Nanyang Technological University
motivation:现有的持续关系学习(Continual Relation Learning,CRL)方法依赖于大量的标记训练数据来学习新的任务,这在实际场景中很难获得,因为获取大的、具有代表性的标记数据往往昂贵且耗时。因此,模型有必要在很少的标记数据下学习新的关系模式,同时避免对先前任务知识的灾难性遗忘(在论文中,这个场景被称为 CFRL(Continual Few-shot Relation Learning)。因此,论文提出了 ERDA,一个基于 embedding space regularization 和 data augmentation 的 CFRL 方法。
GitHub:https://github.com/qcwthu/Continual_Fewshot_Relation_Learning
在持续学习中,避免灾难性遗忘的方法:
- regularization-based methods:对神经权值的更新施加约束,使得以前的任务很重要,以减轻灾难性遗忘。
- architecture-based methods:动态地改变模型架构,以获取新的信息,同时记住以前的知识。
- memory-based methods:将以前的任务中的几个关键例子保存到记忆中,并在学习新任务时重放。
其中 memory-based 的效果最好,但是在 memory-based continual learning 中,这些方法的一个主要限制是,他们都假设大量的训练数据学习新关系,这在实际场景中是非常昂贵的。如果新的训练数据很少,那么现有的方法就会出现过拟合。
模型方法
问题描述
CFRL 假设除了第一个任务有足够的数据进行训练外,后续的新任务都是 few-shot 的。CFRL 的问题设置与真实场景一致,在真实场景中,我们通常有足够的数据来处理现有的任务,但当新任务出现时,只有少数标记数据。
假设在后续的任务中,每一个 few-shot 任务的关系数量为 N,每个关系的样本数量为 K,那么称为 N-way K-shot continual learning。
为了避免灾难性以往,一个存储一些之前任务的关键样本在 memory M = {M1, M2, ...} 在学习期间被维护。由于对任务的数量没有限制,所以 Mk 被限制为很小。在 CFRL 设置中,每个关系只允许将一个样本保存在 memory 中。
总体框架
在每一个时间步,根据任务是否是 few-shot,过程分别有四个或三个工作模块。对于一般的学习任务(general learning process)有三个步骤,适用于所有的任务。如果这个任务是一个 few-shot 的任务(k > 1),我们应用一个额外的步骤来创建一个增强的训练集。
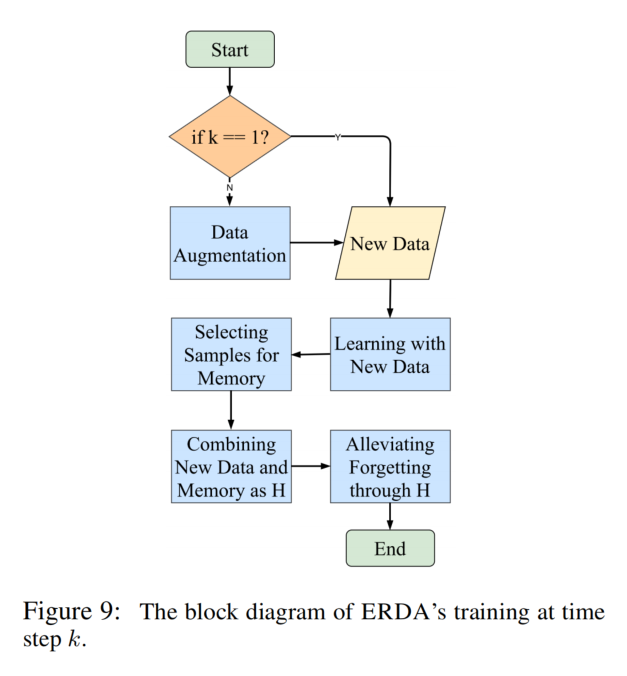

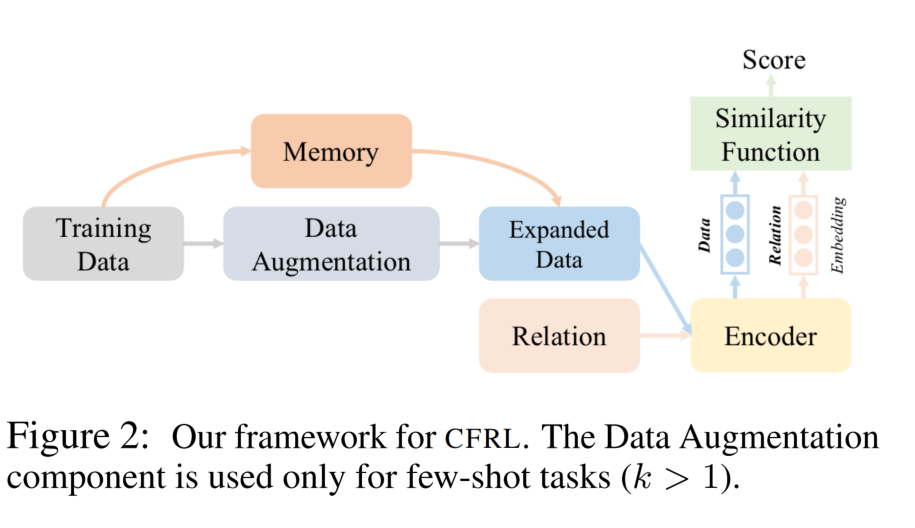
General Learning Process
Encoder
论文中采用两种 Encoder:
- Bi-LSTM
- BERT:由于新的任务很少,只微调了第12层编码层和额外的线性层。在一个给定的标记句子中包含了实体周围的特殊标记(“#”表示头部实体,“@”表示尾部实体),以提高编码器对关系信息的理解。并且,使用 [CLS] 标记特性作为输入序列的表示。
Learning with New Data
在每一个时间步上,使用扩展数据集进行 fine-tune。
- 首先,使用新关系的名字进行 encode,作为关系表示。
- 接着,使用 Lnew 损失函数在扩展数据集(数据增强之后的数据集)上,对模型进行训练。

其中:
- Lce 用于关系分类。
- Lmm 为 multi-margin loss,确保关系类内部的紧凑性、同时增加类之间的距离。
- Lpm 为 pairwise margin loss,会惩罚最近的错误标签的相似性得分高于正确标签的得分的情况。Lmm 和 Lpm 都增强了模型的鉴别能力。


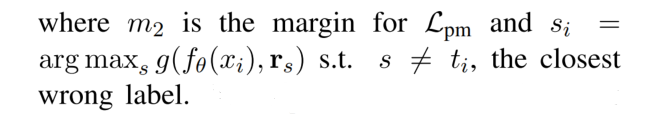
Selecting Samples for Memory
接着为新的关系类型选择记录在 memory 中的样本,计算所有新关系类型的中心,接着选择最接近中心的记录在 memory 中。
Alleviating Forgetting through Memory
再将数据增强之后的数据集与 memory 中的样本合并后进行训练,允许模型学习新的关系知识并巩固以前的知识。然而每一个关系只包含一个样本,设计了一种方法为 memory 中的每一个样本生成一个 hard negative sample。负样本是动态生成的:
- 在一个 Batch 中,对于每一个在 memory 中的样本,都随机的替换头实体或者尾实体,来生成一个负样本。
同时,引入 contrastive loss 进行训练,这种损失迫使模型将有效的关系和硬的负面关系区分开来,从而使模型学习到更精确和更细粒度的关系知识。
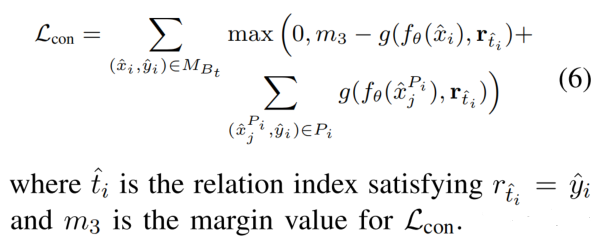
最后,在数据增强之后的数据集与 memory 中的样本合并后生成的数据集上,同样也使用 Lce、Lmm 和 Lpm 进行训练:
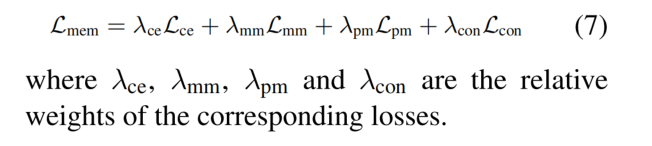
在进行训练时,会更新 relation embeddings:通过对关系名称的送入 encoder 得到的 embedding、以及 memory 中 embedding 的平均来更新关系表示 embedding。通过反复训练模型、更新关系表示,就可以反复掌握新的关系模式,同时减轻对先前知识的灾难性遗忘。
在推理时,计算输入的句子与所有关系表示的相似度,选分数最高的。
Data Augmentation for Few-shot Tasks
对于每一个 few-shot 任务,希望进行数据增强。
开始之前,通过从一个带有标记实体的未标记语料库 C 中选择可靠的样本来获得更多的数据。我们使用关系相似度模型 Sπ 和维基百科中的句子作为 C 来实现这一点。模型 Sπ 将一个句子作为输入,并生成一个标准化的向量表示。利用两个向量之间的余弦相似度来衡量两个对应句子之间的关系相似度。相似性越高,就意味着这两个句子更有可能具有相同的关系标签。
论文提出两种互补的方式来进行数据增强:
- Augmentation via Entity Matching:对于训练集中的一个句子,首先提取出头实体和尾实体。搜索语料库中具有相同头实体和尾实体的句子,作为候选送入 Sπ 中计算相似度。超过一定阈值的,就加入到扩展数据集中。(具有相同实体的句子,可能表达同一种关系)
- Augmentation via Similarity Search:如果语料库中没有相同的头实体和尾实体的句子,就将语料库中与该句子相似度 Top-K 的句子加入到扩展数据集中。
为了训练 Sπ,采用一种对比学习方法对 C 上的 BERT-base 模型进行微调。于观察到具有相同实体对的句子更有可能编码相同的关系,论文使用在 C 中包含相同实体的句子对作为正样本。对于负样本,只是选择 hard negative sample 作为负样本(头实体或者尾实体不同)。随机抽取与正样本相同数量的负样本,以平衡训练。
实验结果