Adjacency List Oriented Relational Fact Extraction via Adaptive Multi-task Learning
来源:ACL(finding) 2021
作者:Fubang Zhao, Zhuoren Jiang, Yangyang Kang, Changlong Sun, Xiaozhong Liu
机构:Alibaba Group, Zhejiang University
motivation:论文提出所有的关系抽取模型都可以根据图的角度来组织,并且提出了一种邻接表视角的关系抽取模型 DIRECT(aDjacency LIst ORiented rElational faCT)。为了解决子任务错误的传播和子任务失衡问题,采用了一种新的自适应多任务学习策略和动态子任务损失平衡方法。、
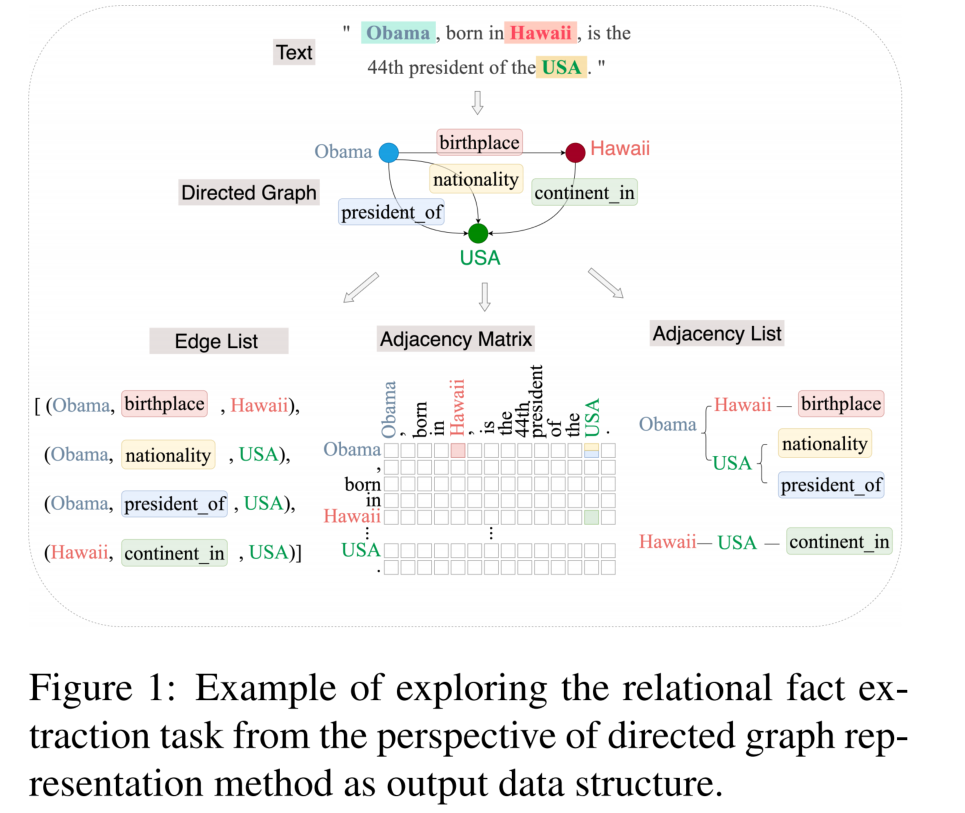
关系抽取可以被描述为一个有向图的构造任务,实体为节点,关系为边。有三种方法表示图:
- Edge List
- Adjacency Matrix
- Adjacency List
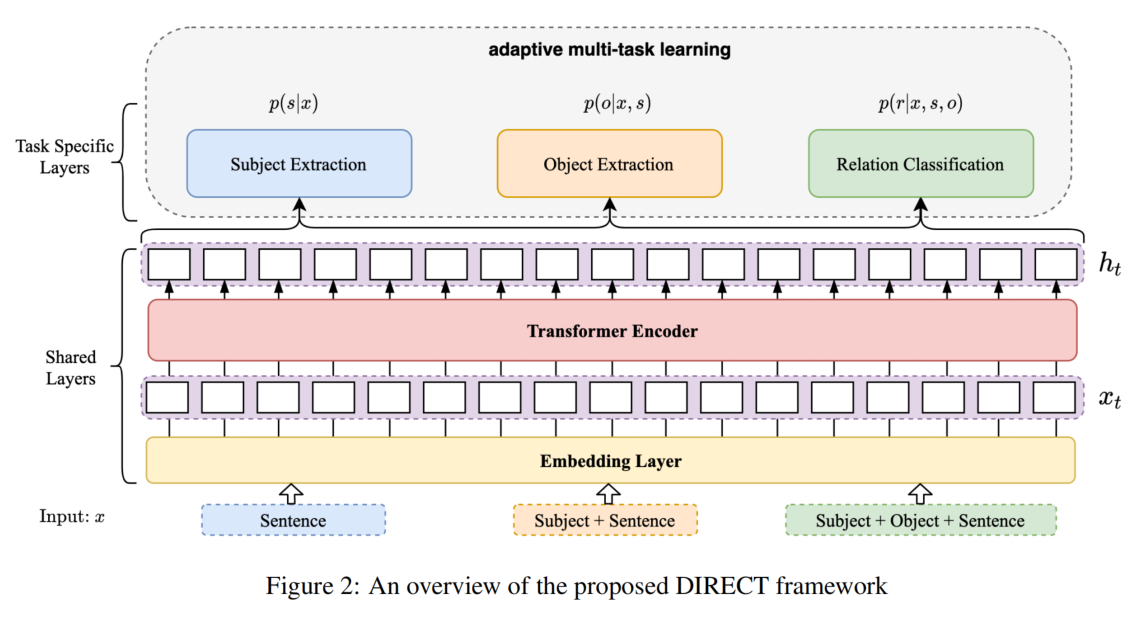
DIRECT 框架
DIRECT 框架其中包括一个共享的BERT编码器和三个输出层:subject 提取、object 提取和关系分类。
- 首先将输入的句子输入到 subject 提取模块中提取所有的 subject;
- 然后将每个提取的 subject 与句子连接,输入 object 提取模块,提取所有object ,可以形成一组 subject-object pair;
- 最后,将 subject object pair 与句子连接,输入关系分类模块,得到它们之间的关系。
为了平衡子任务损失的权值,提高全局任务性能,三个模块共享 BERT 编码器层,并采用自适应多任务学习策略进行训练。
Subject and Object Extraction
对每个 token 执行两次独立的二分类,以表明当前 token 是一个跨度的开始还是结束。token 是开始或结束的概率如下:
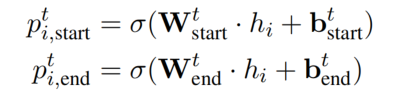
Subject 和 Object Extraction 的总体结构是一样的,但是输入是不一样的。
- Subject Extraction 输入的是原始的句子。
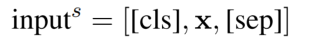
- 而 Object Extraction 输入的是 subject 加上原始的句子。
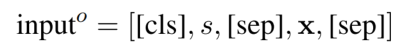
在预测时,提取出概率大于阈值的 start position,在下一个 start position 之前搜索概率大于阈值的 end position,以此为一个实体的 span。
Relation Classification
关系分类就是对每一个关系都进行一个概率预测:
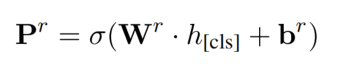
输入为 subject、object、与原始句子的连接:
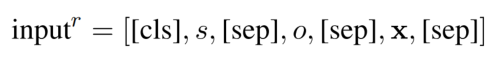
Adaptive Multi-task Learning
在 DIRECT 中,subject extraction 模块、object extraction 模块、关系分类模块可以被看作是三个子任务。如果直接和单独地训练每个模块,错误传播问题就会损害模型的表现。与此同时,三个独立的 encoder 会消耗更多的内存。
因此,我们使用多任务学习来缓解这个问题,encoder 层跨三个模块共享。但是直接应用多任务学习有以下挑战:
- 这三个子任务的输入和输出是不同的,这意味着不能简单地加和每个任务的损失。
- 应该如何平衡三个子任务模块的损失权重。
因此,论文提出了一种新的自适应多任务学习策略来解决上述问题。

为了确保每个任务对共享编码器有足够的影响,将根据每个子任务的训练数据量来惩罚子任务的权重。
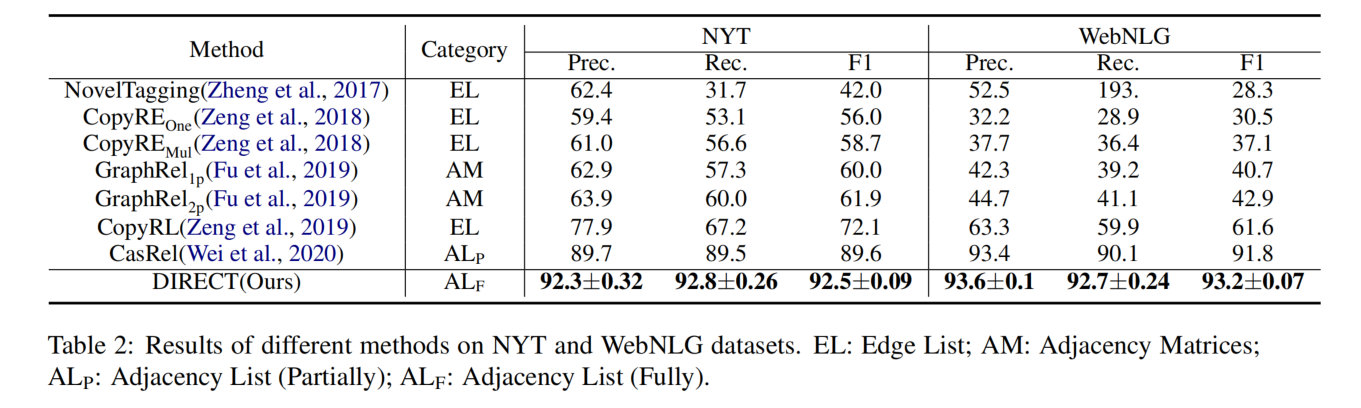
实验结果