TDEER: An Efficient Translating Decoding Schema for Joint Extraction of Entities and Relations
来源:EMNLP 2021
作者:Xianming Li, Xiaotian Luo, Chenghao Dong, Daihuan Yang etc.
机构:Ant Group, Shanghai
贡献:提出了实体关系联合抽取模型 TDEER(Translating Decoding Schema for Joint Extraction of Entities and Relations)。
- 提出的翻译解码模式,将关系视作 subject 到 object 的翻译操作。TDEER 将关系三元组解码为 subject + relation -> objects。
- TDEER 可以很自然地处理重叠的三重问题。TDEER 遍历所有的 subject 和 relation 来识别出 object,因此可以考虑到所有的三元组,包括重叠或者不重叠的三元组。
- 为了增强模型的鲁棒性,引入了负样本来缓解不同阶段的误差积累。
GitHub:https://github.com/4AI/TDEER
模型结构
TDEER 是一个三阶段模型:
- 第一阶段,TDEER 使用一个基于 span 的实体标记模型来提取所有的 subject 和 object。
- 第二阶段,TDEER 采用多标签分类策略来检测所有的相关关系。
- 第三阶段,TDEER 迭代成对的 subject 和 relation,通过所提出的翻译解码模式来识别各自的 object。

Entity Tagging Model
利用两个二分类模型,分别标记 start 和 end 位置。
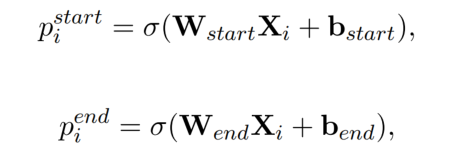
这一步总共用到四个二分类,分别标注 subject 和 object 的 start 和 end 位置。
Relation Detector
一个句子中可能有多个关系,所以采用多标签分类。输入为 CLS 或者最好一个输出 LO(last output)。
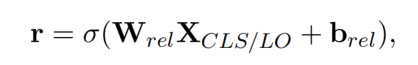
Translating Decoding Schema
TDEER 选择关系 embedding 进入一个全连接层,作为关系表示:
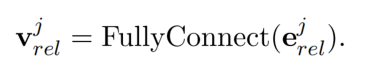
选择 subject 开始和结束位置 token embedding 的平均作为 subject 表示。接着通过加法将 relation 和 subject 链接起来:
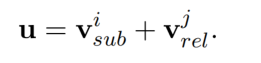
最后,利用注意力机制获取 object 在第 i 个位置上的可能性:
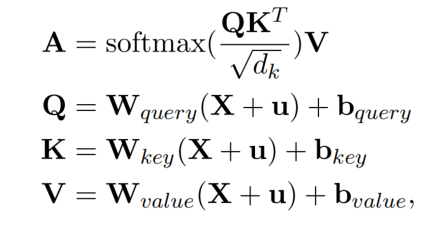
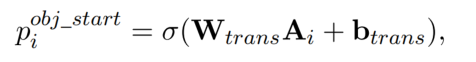
Negative Sample Strategy
在 TDEER 中,翻译解码器可以从上游组件中接收错误的实体关系。因此,论文引入了一种负样本策略来检测和减轻上游成分的误差。
对于每个句子,在训练阶段将正确的 subject/relation 替换为其他不正确的 subject/relation,从而产生不正确的三元组作为负样本,负样本在解码阶段每一个位置上输出为 0。
这个策略使 TDEER 能够在解码阶段,可以处理 subject 和 relation 的噪声输入。
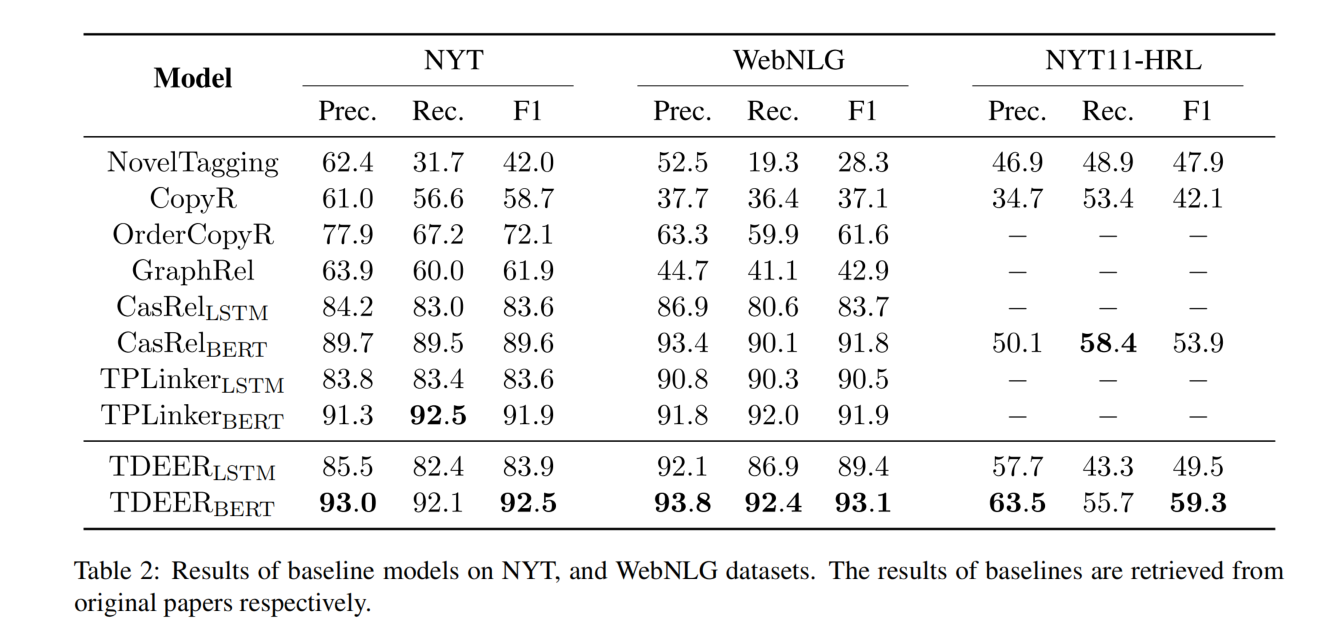
实验