A Novel Global Feature-Oriented Relational Triple Extraction Medel
来源:EMNLP 2021
作者:Feiliang Ren, Longhui Zhang, Shujuan Yin, Xiaofeng Zhao, Shilei Liu etc.
机构:Northeastern University
motivation:基于填表的关系抽取中,大多数只关注使用局部特性,而忽略了关系和标记对的全局关联,这可能回丢失一些重要的信息。为了克服这种缺陷,论文提出了基于全局特征的关系抽取模型,这个模型很好的利用了上述关系和标记对的全局关联。这种全局关联不仅提高了准确性,而且提高了召回率。
方法论
填表策略
对于一个长度为 n 的句子,为每一个 relation 维护一张 n×n 的表,核心在于为表中的每一项分配一个标签。标签包括:N/A,MMH,MMT,MSH,MST,SMH,SMT,SS。标签解释如下:
- N/A:第 i 个 token 和第 j 个 token 没什么关系。
- SS:第 i 个 token 到第 j 个 token 为一个实体。
- MMH,MMT,MSH,MST,SMH,SMT:第 i 个 token 和第 j 个token 与实体对相关。
- 第一个字母代表 subject 为 multi-token entity(M)或者 single-token entity(S)。
- 第二个字母代表 object 为 multi-token entity(M)或者 single-token entity(S)。
- 第三个字母代表两个 token 都是 subject 和 object 的 head token(H)或者 tail token(T)。
这样的填表策略的主要优点在于:
- 每个标签不仅可以揭示一个 token 在一个 subject 或一个 object 中的位置信息。
- 还可以揭示一个subject(或一个 object)是单个 token 实体还是多个 token 实体。
模型结构
模型包括以下几个部分:
- Encoder
- Table Feature Generation(TFG)module
- Global Feature Mining(GFM)module
- Triple Generation(TG)module
TFG 和 GFM 以迭代的方式多次执行,以便逐步细化 table feature。最后,TG 根据每个表对应的细化 table feature 填充每个表,并根据这些填充的表生成所有三元组。
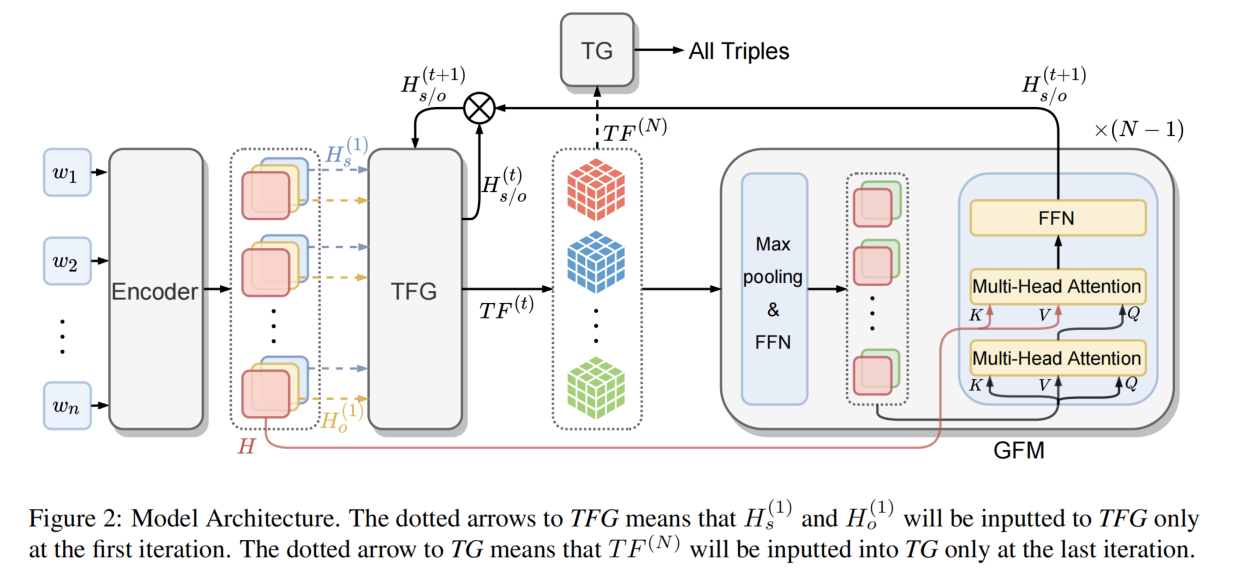
Encoder Module
将句子输入到 BERT 中得到 H,接着送入两个独立的前馈神经网络(FFN)中,得到初始的 subject 和 object feature:
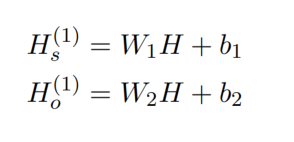
TFG Module
subject 和 object feature 的上标代表的是第 t 次迭代,将第 t 次迭代的 subject 和 object feature 作为输入,为每一个关系生成 table feature(TF)。
TF中的每一项代表一个 token pair 的 label feature,则 table feature 的第 i, j 位置上的计算方法为:
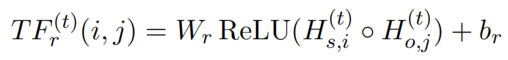
table feature 的维度为 n×n×L(n 代表句子的长度,L 为标签的个数)。
GFM Module
这个模块挖掘两种全局特征,并且基于它们生成新的 subject 和 object feature。然后,新生成的 feature 被反馈给 TFG,以进行下一次迭代。
具体来说,这个模块由三个步骤组成:
- 第一步:连接所有关系的 table feature,形成 unified table feature。这个 unified table feature 就同时包含了 token pair 和 relation 的信息。然后分别利用两个最大池化(最大池化突出从全局的角度提取对 subject 和 object 有帮助的重要特征)操作和 FFN 得到 subject-related table feature 和 object-related table feature:

- 第二步:为了挖掘两种类型的全局表征,论文中使用 Transformer-based 的模型来挖掘 relation 和 token pairs 之间的全局关系。使用多头自注意力机制来挖掘关系之间的全局联系,自注意力机制可以从其他 item 的角度看一个 item 的重要性,非常适合挖掘关系关联。接着使用多头注意力机制,BERT 的输出 H 也作为输入的一部分,因为 H 再一定程度上包含了一个 token 的全局语义信息,因此有助于从整个句子的角度挖掘 token pair 的全局关联。最后进入 FFN 得到新的 subject 和 object feature:

- 第三步:如果展开 TFG 和 GFM 的迭代模块,模型等于一个非常深的网络,可能会遭受梯度消失的问题。为了避免这种情况,我们使用残差网络来生成最终的 subject 和 object feature:
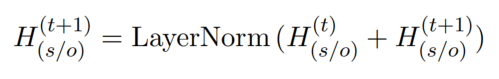
TG Module
选择最后一次迭代得到的 table feature 作为输入,进行填表:
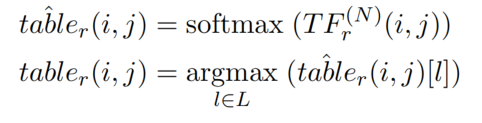
最后进行解码,得到关系三元组。
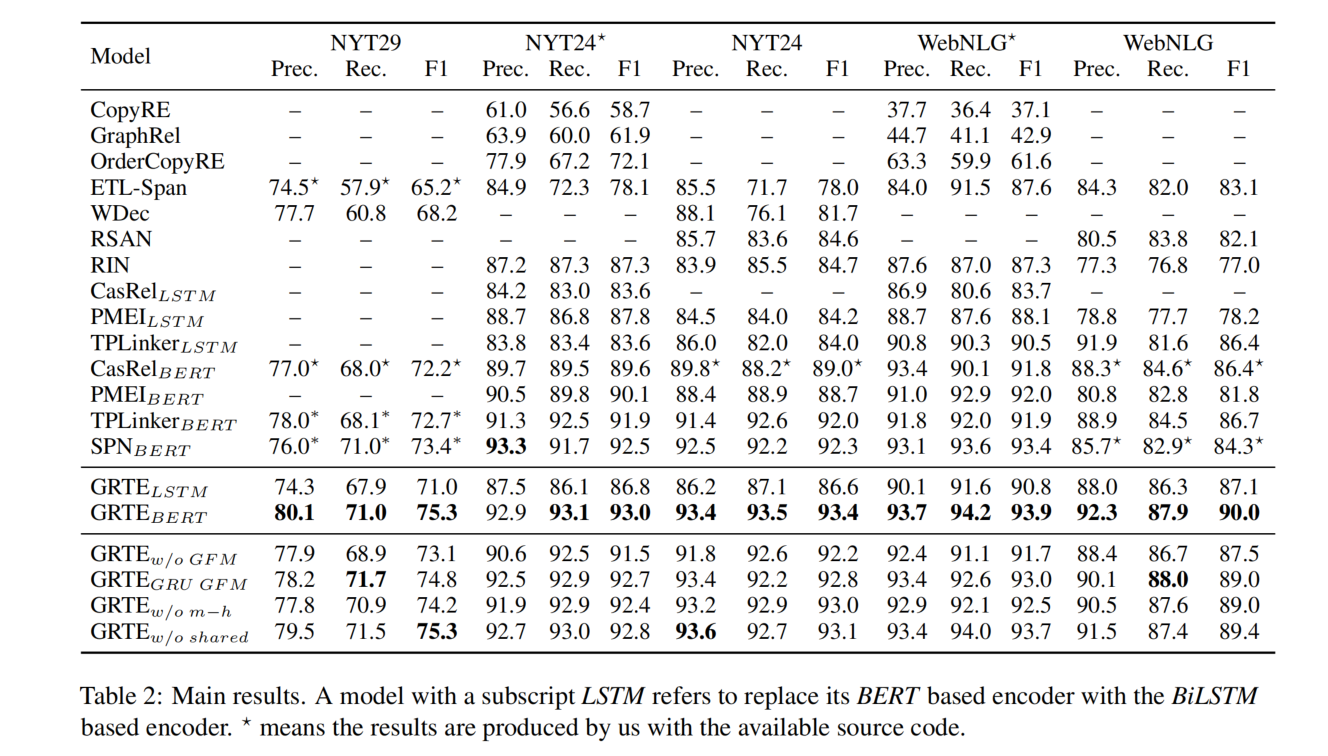
实验结果