map
数据结构
map 数据结构
map 的数据结构如下:
1 | type hmap struct { |
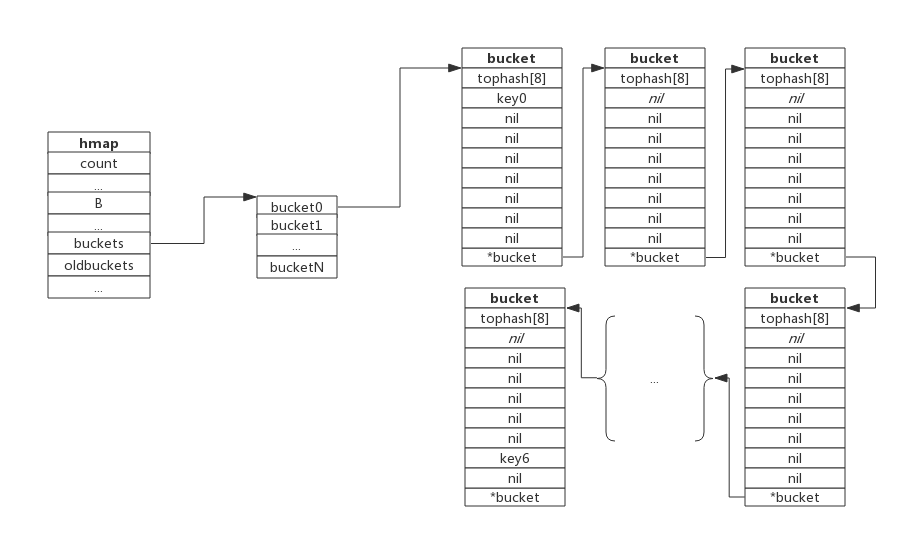
底层使用哈希表作为实现,一个表里面有多个哈希表节点(哈希桶)bucket,每一个 bucket 保存了 map 中的一组键值对。
bucket 数据结构
一个 bucket 的数据结构如下:
1 | type bmap struct { |
每一个 bucket 可以存放 8 个键值对。
如果满了,而且又来一个 key 落在了这个桶里,则会使用 overflow 连接下一个溢出桶。
插入和查找
插入过程
在 map 中的插入过程如下:
- 首先根据 key 计算出哈希值。取哈希值的低 hmap.B 位,来确定是几号桶。
- 遍历当前桶,查找该key是否已经存在:
- 若存在,则更新该值。
- 若不存在,则进行插入,找到第一个可以插入的位置进行插入。
哈希冲突:Golang 使用链地址法处理哈希冲突,在哈希桶中可以存放 8 个键值对,如果满了则通过 overflow 指针像链表一样链接下一个溢出桶。
查找过程
在 map 中的查找过程如下:
- 首先根据 key 计算出哈希值。取哈希值的低 hmap.B 位,来确定是几号桶。
- 根据 bmap.tohash 前 8 位快速确定在这个哈希桶的哪个位置。tophash 可以快速确定 key 是否正确,也可以把它理解成一种缓存措施,如果前 8 位都不对了,后面就没有必要比较了。
- 对比 key 完整的哈希值是否匹配,如果匹配则获取对应的 value。
- 如果没有找到,则去下一个溢出桶中查找。
扩容机制
负载因子用于衡量一个哈希表冲突情况:
1 | 负载因子 = 键数量/bucket数量 |
Go 在负载因子达到 6.5 时才会触发 rehash,因为 Go 的 bucket 可以存 8 个键值对,所以 Go 可以容忍更高的负载因子。
触发扩容的条件
Go 中有两个条件可以触发扩容:
- 装载因子 > 6.5 时:当平均每个桶中的数据超过了 6.5 个,那就意味着当前容量要不足了,发生扩容。
- 溢出桶的数量过多时:当溢出桶的数量变多时,意味着拉链的链条越来越长,扫描速度变慢需要扩容。
- 当 B < 15 时,溢出桶的数量超过 2^B。
- 当 B >= 15 时,溢出桶的数量超过 2^15。
二倍扩容
二倍扩容会使得新的 buckets 是原来的两倍。
因为 map 中存储了很多的数据,一次性搬迁将会造成比较大的延时,Go 采用逐步搬迁策略,即每次访问 map 时都会触发一次搬迁,每次搬迁 2 个哈希桶。
因为不是一次性全部搬迁的,所以需要 hmap.oldbuckets 记录原来的 buckets,当 oldbuckets 中的键值对全部搬迁完毕后,就会删除 oldbuckets。
等量扩容
由于 map 中不断的 put 和 delete key,桶中可能会出现很多断断续续的空位,这些空位会导致链接的溢出桶很长,导致扫描时间变长。这种扩容实际上是一种整理,把后置位的数据整理到前面。
如下图,溢出桶中大部分是空的,访问效率会变差。进行一次等量扩容后,buckets 数量不变,溢出桶数量减少,节省空间而且提高访问效率。
string
数据结构
string 的数据结构如下:
1 | type stringStruct struct { |
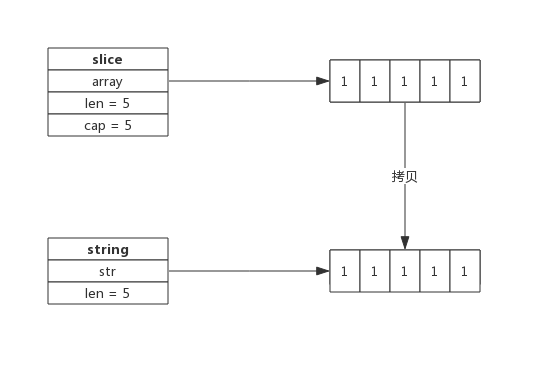
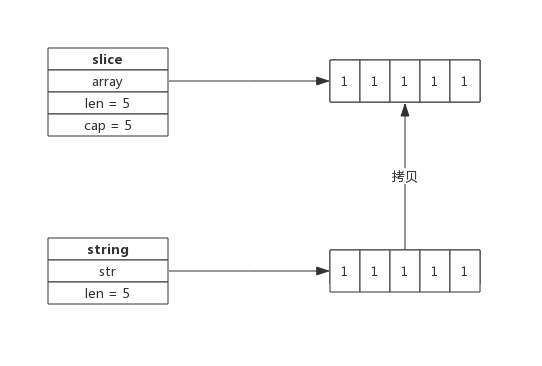
string 与 slice 的结构类型,包含一个指向底层数组的指针,以及长度,不同的是 string 没有容量。
[]byte 与 string 的相互转换
在 byte 切片与 string 的相互转换过程中,需要申请内存进行一次内存拷贝。
byte 切片转为 string:
string 转为 byte 切片:
为了性能上的考虑,有时候只是临时需要字符串的场景下,byte 切片转换成 string 时并不会拷贝内存,而是直接返回一个 string,这个 string 的指针指向切片的底层数组:
- 使用 m[string(b)] 来查找 map;
- 字符串拼接:如 “<” + “string(b)” + “>”;
- 字符串比较:string(b) == “foo”。