A Unified Multi-Task Learning Framework for Joint Extraction of Entities and Relations
来源:AAAI 2021
作者:Tianyang Zhao, Zhao Yan, Yunbo Cao, Zhoujun Li
机构:State Key Lab of Software Development Environment, Beihang University, Beijing, China
作者根据提取三元组的顺序将关系抽取模型分成了三类:
- relation-last:可以被总结为先抽取出实体,然后对任意两个实体进行关系分类。这种方法的缺点就是需要枚举出所有的实体对进行关系判断,并且由非常多的负例影响了关系分类器。
- relation-first:首先检测出句子中可能包含的关系,然后在句子中选择关系对应的 subject 和 object。这种方法首先通过预测关系,过滤掉了不相关的关系,减轻了无用关系造成的负面影响,大大避免了数据不平衡的问题。
- relation-middle:首先提取出 subject,然后根据 subject 提取出 relation,最后提取出 object(典型的比如多轮次 QA,CasRel也属于这个方法)。在多轮次 QA 中,基于模板进行提问的,这样做的好处是:
- 查询问题明确地提供了关于类型信息的先验知识。
- 基于 QA 结构,增强了查询与文本之间的交互作用。
- 它提供了一种处理重叠实体和关系的自然方法。
但是,基于 QA 的方法由以下问题:
- 严重依赖于手工设计的模板,这使得模型难以迁移。
- 目前主流的方法无法在非实体上识别出关系,严重依赖于 NER。
- 现有的方法无法处理非预定义的关系。
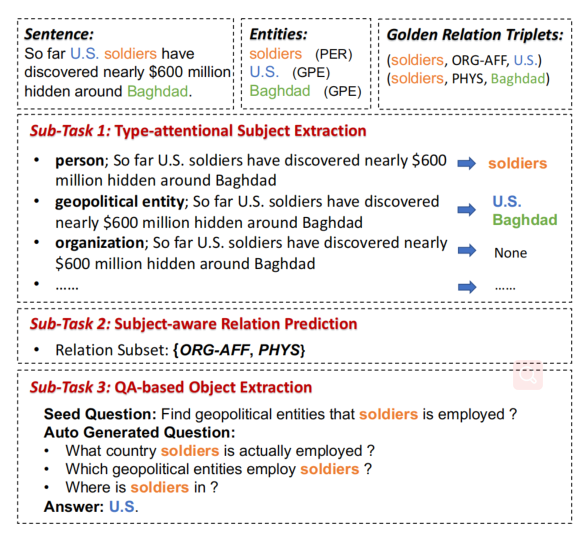
文章提出了一个实体关系联合抽取框架,将任务划分为了三个子任务:the type-attentional subject extraction,the subject-aware relation prediction(SRP),the QA-based object extraction。
- 为了缓解模板依赖的问题,提出了 type-attention,为 subject 提取任务中提供明确的实体类型信息。
- 论文引入了 subject-aware relation prediction 任务,利用全局和局部语义获得了给定主体的关系子集。
- 论文提出了一种 question generation(QG)策略,以自动得到在 object 提取任务中的多种查询语句。这个子任务根据之前的类型信息和查询,在句子中选择文本跨度,而不依赖于 NER。此外,论文还提出了一种模糊问题回答方法,来解决非预定义的关系检测问题。
模型方法
为了整合任务之间的相互作用,采用多任务学习的方式来提高整体的性能。基于 relation-middle 的方式,模型由三个部分组成:
- type-attentional subject extraction:显式的提供类型信息,来从句子中预测 subject。
- subject-aware relation prediction:给定 subject,选择可能与 subject 相关关系的多分类问题。
- QA-based object extraction:使用自动生成的问题从句子中选择 object。
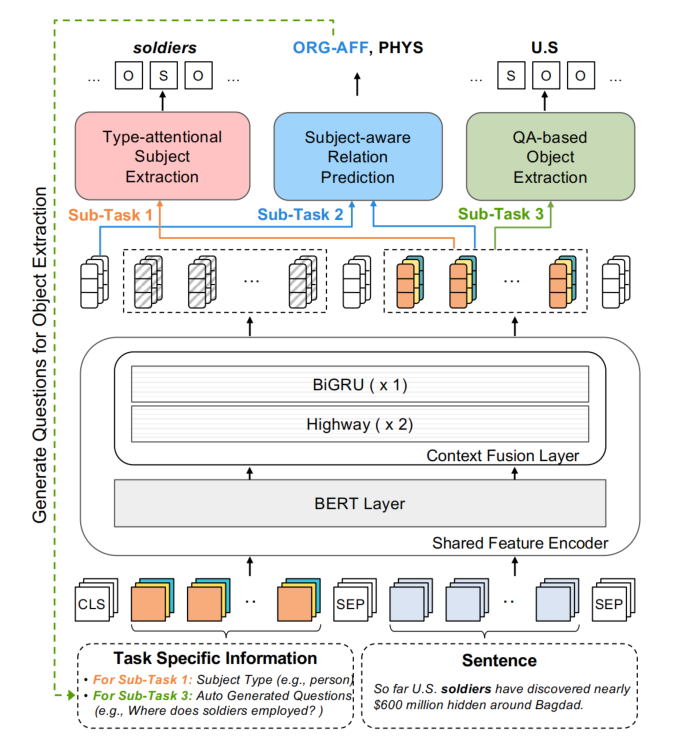
Shared Feature Encoder
共享特征编码层由两部分组成:BERT Layer 和 Context Fusion Layer。
BERT Layer
BERT 层的输入包括三个部分:
- 输入的句子
- 任务相关的信息
- 特殊 tokens:CLS 用于 subject-aware relation prediction。
Context Fusion Layer
为了有效地增强序列内的上下文信息,论文应用了一个 context fusion layer 进一步编码 BERT 的输出。BERT 的输出首先被送入两层的 highway 网络中:
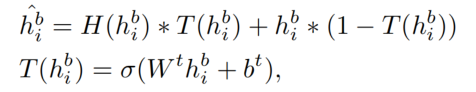
然后送入一个双向 gate recurrent unit(BiGRU)中:
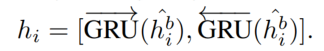
Type-attentional Subject Extraction
将 BERT 输入中任务相关的信息设置为实体类型,并且利用 BIOES(Begin、Inside、Outside、Ending、Single)标记 subject。
具体来说就是将共享特征编码层的输出,送入了一个 softmax 层以预测各个标签的概率:
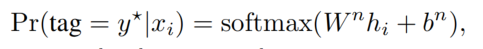
Subject-aware Relation Prediction
这个任务用于预测给定 subject 相关的关系,从而过滤一些冗余的关系。论文从局部特征和全局特征来预测这些关系。
Local Relation Prediction(LRP)
将共享编码层的输出与实体类型 embedding 连接起来,然后送入线性层和 sigmoid 进行多分类,得到关系的概率:
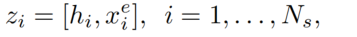
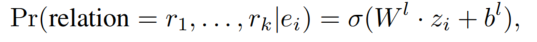
Global Relation Prediction(GRP)
之前的工作只使用局部信息进行关系预测,忽略了整体句子的语义。为了解决这个问题,我们引入了一个全局关系预测来修正局部关系预测的结果。具体来说就是利用 CLS 进行关系预测:
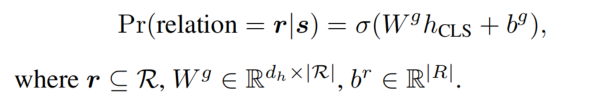
在训练时,集成 LRP 和 GRP 来计算损失。在推理时,只使用 LRP!!
QA-based Object Extraction
在得到 subject 和可能的关系后,基于 QA 提取对应的 object。
Object Extraction Process
生成的 T 个不同问题,分别作为共享编码层输入的任务相关信息,得到 T 个不同的答案。为了挑选出最佳答案,采用加权的策略,为每一个问题定义一个权重。在训练阶段,在验证集上计算权重。最后选取分数最高的为最终答案。
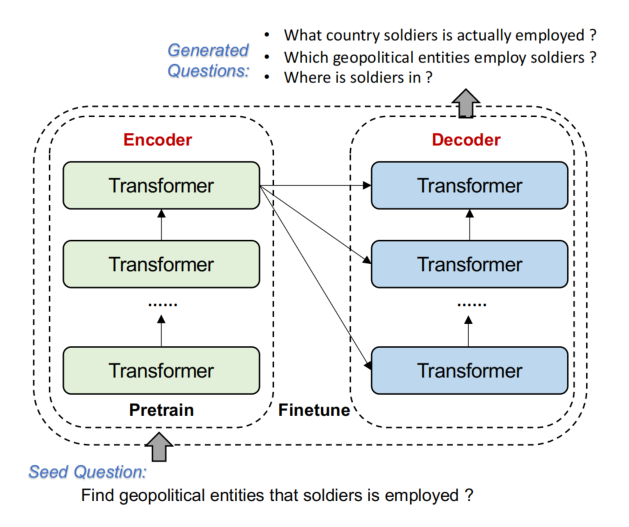
Automatic Question Generation
论文提出基于 Seq2eq 模型自动生成问题。以一个 seed question 作为 seq2seq 模型的输入,种子问题的模板为:Find [object type] that [subject text] is [relation type]。
自动生成一系列的问题:
对于非预定义关系的检测:
论文采用定义模糊问题来检测非预定义的关系。
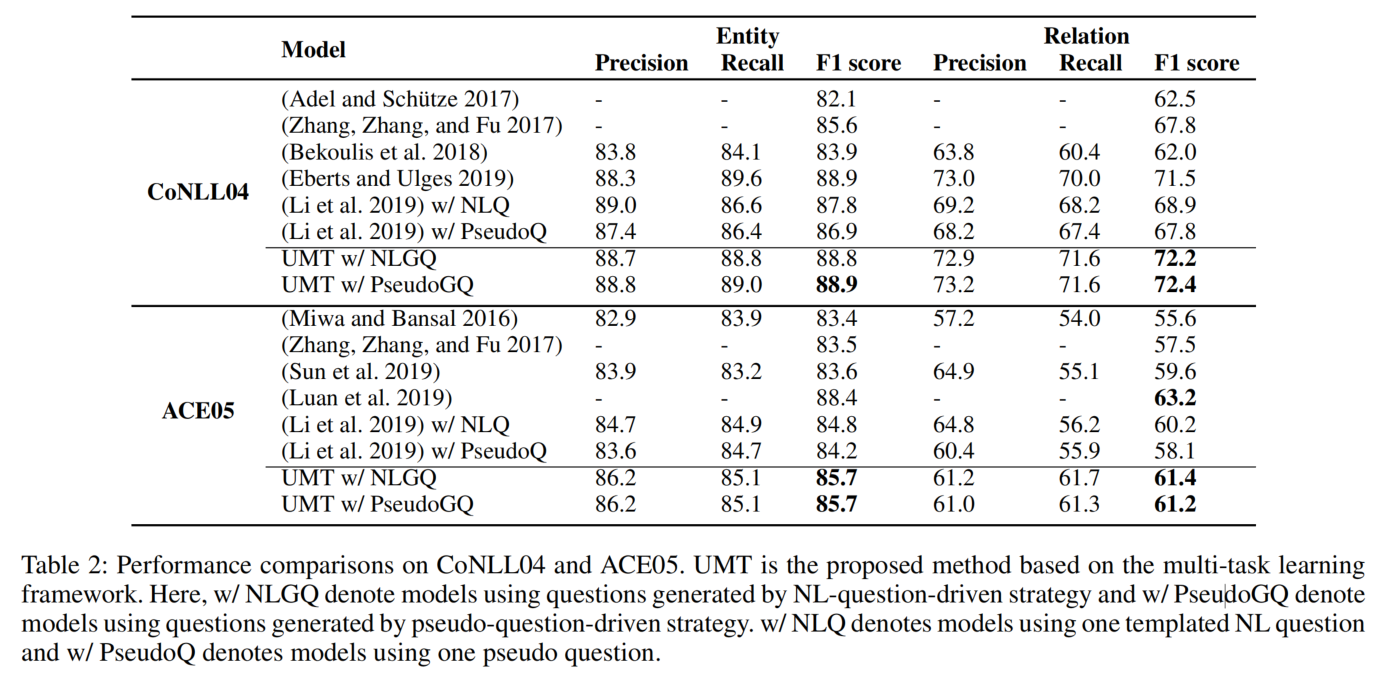
实验结果