客户端缓存
客户端缓存依赖于 HTTP 缓存机制,通过 HTTP Header 控制。
强制缓存
HTTP 强制缓存规定了一个过期时间,在这个时间点之前客户端可以不发出请求,直接使用本地缓存。
根据约定,强制缓存在浏览器的地址输入、页面链接跳转、新开窗口、前进和后退中均可生效,但在用户主动刷新页面时应当自动失效。
两类 HTTP Header 保证了强制缓存:
- Expires:Expires 是 HTTP 1.0 提供的 Header,后面跟随一个截止时间用于定于缓存的有效时间。
Expires 有设计缺陷:
- 受限于客户端的本地时间。
- 无法处理涉及客户端身份的私有资源。
- 无法描述不缓存。
- Cache-Control:Cache-Control 是 HTTP 1.1 种定义的 Header,如果 Cache-Control 和 Expires 同时存在,并且语义存在冲突,规定必须以 Cache-Control 为准。它有一系列参数:
- max-age 和 s-maxage:max-age 后面跟随一个以秒为单位的数字,表明相对于请求时间多少秒以内缓存是有效的。s-maxage 中的 s 为 Share,即允许被 CDN、代理等持有的缓存有效时间。
- public 和 private:指明是否涉及到用户身份的私有资源,如果是 public,则可以被代理、CDN 等缓存,如果是 private,则只能由用户的客户端进行私有缓存。
- no-cache 和 no-store:no-cache 指明该资源不应该被缓存,如果一个页面中引用了两张相同的图片,则会请求两次。no-store 指不能保存在本地,但是用一个页面中引用了两张相同的图片,只会请求一次。
- no-transform:禁止资源被任何形式地修改。某些 CDN、透明代理支持自动 GZip 压缩图片或文本,以提升网络性能,而 no-transform 就禁止了这样的行为。
- min-fresh 和 only-if-cached:这两个参数是仅用于客户端的请求 Header。min-fresh 后续跟随一个以秒为单位的数字,用于建议服务器能返回一个不少于该时间的缓存资源。only-if-cached 表示客户端要求不必给它发送资源的具体内容,此时客户端就仅能使用事先缓存的资源来进行响应,若缓存不能命中,就直接返回 503/Service Unavailable 错误。
协商缓存
强制缓存有一个缓存过期时间,没有一个检测变化的机制,如果缓存还没有过期即使内容发生变化,客户端也不会向服务器请求而是使用本地缓存。
协商缓存在一致性上有更好的表现,但是性能上会差一些,因为需要一次检测变化的开销。
强制缓存和协商缓存是完全并行工作的,当强制缓存存在时,直接从强制缓存中返回资源,无须进行变动检查;而当强制缓存超过时效,或者被禁止(no-cache)时,协商缓存依然可以工作。
协商缓存有两种变化检测机制,分别是根据资源的修改时间、以及根据资源唯一标识符进行检查。
- Last-Modified 和 If-Modified-Since:服务器通过 Last-Modified 告诉客户端资源最后修改时间,客户端通过 If-Modified-Since 将这个时间回送给服务器。
- Etag 和 If-None-Match:服务器通过 Etag 告诉客户端这个资源的唯一标识符,客户端通过 If-None-Match 将这个唯一标识符回送给服务器。
如果此时服务端发现资源没有变动(通过最后修改时间或者唯一标识符),就只要返回一个 304/Not Modified 的响应即可,无须附带消息体。如果发现有变动,则返回 200 并携带完整内容。
Last-Modified 只能精确到秒级,如果一秒之内发生了多次变化,则不能准确标注修改时间。
HTTP Vary Header 在响应中,用于指定其他 HTTP 头部作为客户端缓存命中的依据,如下表示根据 MIME 类型和浏览器类型来缓存资源。
1 | Vary: Accept, User-Agent |
服务端缓存
缓存一致性
Cache Aside
Cache Aside 策略指的是:
- 对于写操作,首先更新数据库,再删除缓存。
- 对于读操作,如果命中直接读取结果,如果未命中则读取直接读取数据库,然后将查询到的结果更新到缓存中。
Cache Aside 策略适合读多写少的场景,不适合写多的场景。
Cache Aside 选择在写操作时删除缓存,如果想要更新缓存而不是删除缓存,会出现数据不一致的情况,可以通过以下方法解决:
- 在更新缓存时加上分布式锁。
- 给缓存一个较短的过期时间,这样不一致的数据也会很快的过期。
如果选择先删除缓存,再更新数据库,则会出现数据不一致的问题。这种方法的解决方案是延迟双删:先删除缓存,更新数据库之后,延迟一段时间再次删除缓存。
延迟双删的延迟时间应该稍大于一次读请求的时间,但是这个值非常难预估,这也是延迟双删中最困难的点。
Read/Write Through
Read/Write Through 策略原则是应用程序只和缓存交互,不再和数据库交互,而是由缓存和数据库交互。
Read Through:先查询缓存中数据是否存在,如果存在则直接返回,如果不存在由缓存从数据库中加载数据,再返回给用户。
Write Through:如果缓存中数据已经存在,则更新缓存中的数据,由缓存同步更新到数据库中。如果缓存数据不存在,则直接更新数据库(缓存加载工作由 Read Through 完成)。
由于常用的 Redis 或者 Memcache 没有从数据库中加载数据的功能,所以不常使用。
Write Back
Write Back 也被称为 Write Behind,这种策略在更新数据时,只更新缓存同时记录需要更新的数据,并且由另一个线程通过批量异步的方式更新数据库。
Write Back 适合写多的场景,但是数据不是强一致性的,而且有数据丢失的风险。
问题
缓存穿透
key 对应的数据在数据源(DB)并不存在,每次针对此 key 的请求从缓存获取不到,那么就会从数据源请求数据,从而可能压垮数据源。
解决方案:
- 对空值缓存:如果一个查询返回的数据为空(不管是数据是否不存在),仍然把这个空结果进行缓存,设置空结果的过期时间会很短,最长不超过五分钟。
- 设置可访问的名单(白名单):将可以访问的 id 记录在 Redis 缓存中,可以使用 string 类型或者 bitmaps 类型(id 作为 bitmaps 的偏移量)。每次访问时都在缓存中查询 id 是否在其中,若不存在就直接返回空值,不查询数据库。
- 布隆过滤器(Bloom Filter):是一个很长的二进制向量(位图)和一系列随机映射函数(哈希函数)。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都远远超过一般的算法,缺点是有一定的误识别率和删除困难。
缓存击穿
某一个 key 对应的数据存在,但在 redis 中过期,此时若有大量并发请求过来(热点数据),这些请求发现缓存过期一般都会从数据库中加载数据并回设到缓存,这个时候大并发的请求可能会瞬间把数据库压垮。
解决方案:
预先设置热点数据:把一些热门数据提前存入到 redis 里面,增加这些热门数据 key 的时长。
实时调整热点数据:监控哪些数据热门,实时调整 key 的过期时长。
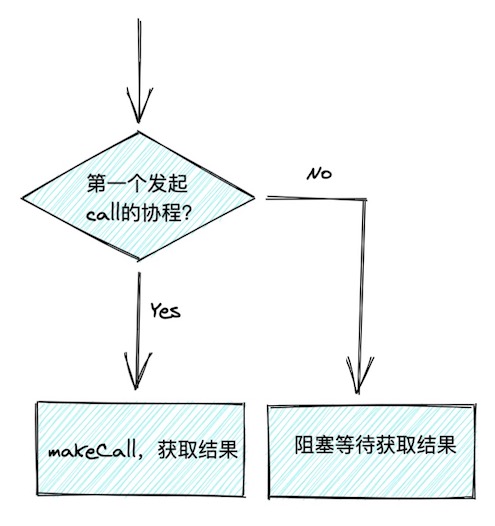
singleflight:可以将对同一个 Key 的并发请求进行合并,只让其中一个请求到数据库进行查询,其他请求共享同一个结果。
缓存雪崩
大量缓存在同一时刻全部失效,造成瞬时 DB 请求量大、压力骤增,引起雪崩。缓存雪崩通常因为缓存服务器宕机、缓存的 key 设置了相同的过期时间等引起。
解决方案:
- 构建多层缓存架构:nginx缓存 + redis缓存 +其他缓存,每一种缓存的过期时间不一样。
- 随机缓存失效时间:在原有的失效时间基础上增加一个随机值,这样每一个缓存的过期时间的重复率就会降低。