服务容错
微服务架构中必须有服务容错的设计,否则会造成故障服务带来的雪崩效应。下面介绍几种服务容错设计模式。
断路器模式
断路器就是熟悉的熔断器,通过熔断器对象接管服务调用者的远程调用,一个熔断器一对一的对应一个远程服务对象。
状态
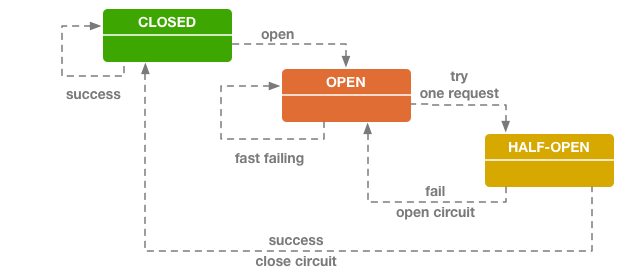
熔断器实际上可以看作是一个有限状态机,有三种状态 CLOSE、OPEN、HALF-OPEN。
- 当熔断器监控到服务返回的故障超过了阈值时,就会变为 OPEN,此后一段时间内不会对该服务(实例)发出任何实际请求,而是直接返回错误。
- 一段时间之后,熔断器会变为 HALF-OPEN 状态,此时下一个远程调用请求会尝试发出,熔断器根据结果变更状态,如果成功则变为 CLOSE,如果失败则继续为 OPEN。
阈值
什么情况下 CLOSE 会变为 OPEN,最简单的方法就是如果出现任何一个错误,就变更状态。但是在用户的角度看来,这是十分糟糕的体验,因为此时调用的服务可能只是偶然的错误并不是真正的故障,在用户看来系统表现十分不稳定。
一个可行的方案是从两个方面考虑,只有同时满足时才从 CLOSE 变为 OPEN:
- 一段时间的请求数量达到阈值:如果请求本身很少,不用熔断器介入。
- 一段时间内的请求故障率达到阈值:如果错误很少,也不用熔断器介入。
舱壁隔离模式
舱壁隔离模式是服务隔离的常用模式,调用服务产生的故障可以分为三类:超时、拒绝(如授权和认证问题)、失败(如参数错误和执行过程错误)三大类。
其中超时最容易引起全局性的风险,因为只要请求不结束就会占用一个线程不能释放。而线程是全局性的系统资源,由超时等待而不能释放的线程多了,那么用于正常服务请求的线程就少了。
更极端的情况,由于等待超时的线程占用了全部的系统线程,那么当前服务对外就会表现为不可用(尽管当前服务只是因为没有多余的线程用于接收服务请求,而不是真正的故障了)。
所以一种可行的方法就是为每一种服务单独的设立服务的最大连接数,超过最大连接数就不允许再请求了。这时,局部的故障不会影响到全局了。
重试模式
可以对错误的请求进行重试,但是是否要进行重试,这都是必须要考虑的问题:
- 在关键的业务上进行重试,对于不关键的业务是否需要重试,需要斟酌重试带来的额外性能消耗是否会得不偿失。
- 重试是否可以解决故障,如果返回的故障为拒绝,说明没有权限或者没有认证,此时重试太多次也无济于事。
- 重试是否具有幂等性,具有幂等性的操作才会进行重试。
终止条件
重试不能无限制的进行,需要确定的终止条件来保证。终止条件可以是超时终止(超时说明服务不可用,避免无限期的等待),或者是次数终止(重试不仅会给调用者带来负担,对于服务提供者也是同样是负担)。
流量控制
网络存储计算等资源不是无限的,如果一个系统内部没有限流机制,因为请求数量超过系统能够承受的最大数量,那么在范围内的正常请求也会受到影响。
所以,必须要由限流器来保证系统的健壮性,防止过多的请求影响正常的请求。
流量统计指标
做流量控制,就需要定义统计指标:
- 每秒事务数(Transaction per Second,TPS):事务可以理解为一个业务操作,是衡量信息系统吞吐量的最终标准。
- 每秒请求数(Hits per Second,HPS):每秒从客户端发向服务端的请求数,注意一个事务可以发出多个请求。
- 每秒查询数(Queries per Second,QPS):一台服务器能够响应的查询次数。
以上都是基于计数的流量统计指标,最理想的情况是使用 TPS 作为指标。因为信息系统最终是为人类用户来提供服务的,用户不关心业务到底是由多少个请求、多少个后台查询共同协作来实现。但是这是很难做到的,因为由于用户前端的交互,一个业务可能会持续很长时间(甚至几分钟),发出的请求均匀或者不均匀的分布在这段时间内,TPS 不能准确反映出系统所承受的压力。
主流系统大多倾向使用 HPS 作为首选的限流指标,它是相对容易观察统计的,而且能够在一定程度上反应系统当前以及接下来一段时间的压力。
统计指标不是一定遵循以上标准,对于 I/O 密集型操作,可以将请求或者响应的内容大小作为流量统计指标。
限流设计模式
如何进行限流,也有一些常见常用的设计模式可以参考使用。
流量计数器模式
设置一个计数器,当流量指标超过计数器的阈值后,进行限流。
这样的方式是最简单的,但是有一个问题就是计数器方式是基于离散的时间点统计流量指标,可能不能正确的反映出系统当前的流量压力。
滑动窗口模式
设置一个窗口,窗口随着时间片一起平滑的移动,根据窗口内部的所有统计信息来决定是否进行限流操作。
滑动窗口模式可以近似的看作连续性的,解决了计数器模式的缺点。但是它通常只适用于否决式限流,超过阈值的流量就必须强制失败,很难进行阻塞等待处理,也就很难在细粒度上对流量曲线进行整形,起不到削峰填谷的作用。
漏桶模式
漏桶就是维护一个先进先出的队列,队列长度就是漏桶大小。当队列已满时便拒绝新的请求进入,处理结束后从队列中移出。
令牌桶模式
令牌桶就是定期向令牌桶当中放置令牌,取到令牌后就意味着可以接收请求进行处理。如果桶中没有令牌,则会返回失败。
分布式限流
以上都是部署在单个节点上的限流方式,如果在微服务架构中,需要对整个集群的服务进行统一的限流(如不管有多少个提供点赞服务的节点,限流的效果就是点赞操作一秒钟最多点 1000 次)。
有两种实现方法:
- 集中式缓存存储流量指标:通过集中式的缓存(Redis)使得流量指标能够被集群内的所有节点共享,这样就能完成集群内的分布式限流。但是这样的代价也是很明显的,每一次都必须以网络请求的方式获取或者修改流量指标,这也消耗量系统的资源。
- 改造令牌桶:将令牌改造为数值形式的货币额度,当请求进入集群时在 API 网关处领取一定的货币额度(对于不同身份的用户,额度可以有所差异),对于任何请求都会消耗一定的货币,把剩余额当作是内部限流的指标。只要一旦剩余额度小于等于零,就不允许访问其他服务了,必须发起一次网络请求在网关处重新申请一次额度。这种方法中,失败的代价很高,这意味着之前的所有操作都白做了,但是它是一种性能和限流的折衷方案。