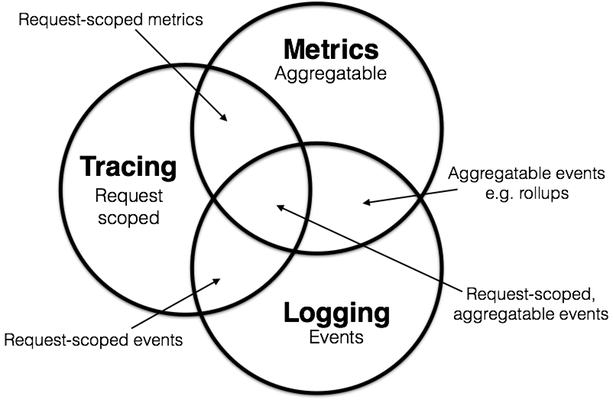
可观测性包含三个方面:日志、追踪、度量:
- 日志:日志用于记录离散的事件,这些事件就是程序的行为。
- 追踪:追踪就是为了得到完整的远程调用链路,主要目的是排查故障、观察调用链是否符合预期。
- 度量:度量是指对系统中某一类信息的统计聚合,如内存占用率、磁盘占用率等等。
日志
日志不仅仅是输出并记录日志这么简单,在微服务架构中的海量日志处理也是十分重要的。日志处理过程包括如下步骤:

输出
日志应该无有遗漏地记录信息,格式统一,内容恰当(不应该过多占用 I/O,不应该过少缺少必要信息)。
收集和缓冲
将日志文件统一收集起来集中存储、索引,由此便催生了专门的日志收集器。
最初日志收集器是由 Logstash 负责的,但是 Logstash 需要跑在单独的 JAVA 虚拟机上,默认堆栈就达到了 1GB。作为每一个节点上都要部署的收集器,这就过于沉重了。
后来 Elastic.co 公司利用 Golang 编写了轻量高效的日志收集器 Filebeat。不过 Beats 家族不仅于此,处理 Filebeat 外,有用于收集 Linux 审计数据的 Auditbeat、用于收集 Windows 事件日志的 Winlogbeat、用于心跳检测的 Heartbeat 等等。
因为集群中有很多节点都在日志收集,产生的日志数据数以万计。在日志收集过后的流程中,需要保证日志不丢失,在做到在后续处理能力出现瓶颈时做到削峰填谷。所以在这之后架设一个 Kafka 或者 Redis 作为缓冲层,以应对突发流量。
聚合加工
将日志集中收集之后,存入 Elasticsearch 之前,一般还要对它们进行加工转换和聚合处理。这是因为日志是非结构化数据,一行日志中通常会包含多项信息,如果不做处理,那在 Elasticsearch 就只能以全文检索的原始方式去使用日志,既不利于统计对比,也不利于条件过滤。
Logstash 的基本职能是把日志行中的非结构化数据,通过 Grok 表达式语法转换为结构化数据,进行结构化的同时,还可能会根据需要,调用其他插件来完成时间处理(统一时间格式)、类型转换(如字符串、数值的转换)、查询归类(譬如将 IP 地址根据地理信息库按省市归类)等额外处理工作,然后以 JSON 格式输出。
存储和查询
Elasticsearch 是一种文档数据库,它用于存储日志。对于加工过后已经结构化的日志,Elasticsearch 便可针对不同的数据项来建立索引,进行条件查询、统计、聚合等操作的了。
Elasticsearch 只提供了 API 层面的查询能力,它通常搭配同样出自 Elastic.co 公司的 Kibana 一起使用,Kibana 作为 GUI 图形界面。
追踪
追踪用于知晓服务调用链路,所以又称之为链路追踪。
追踪和跨度
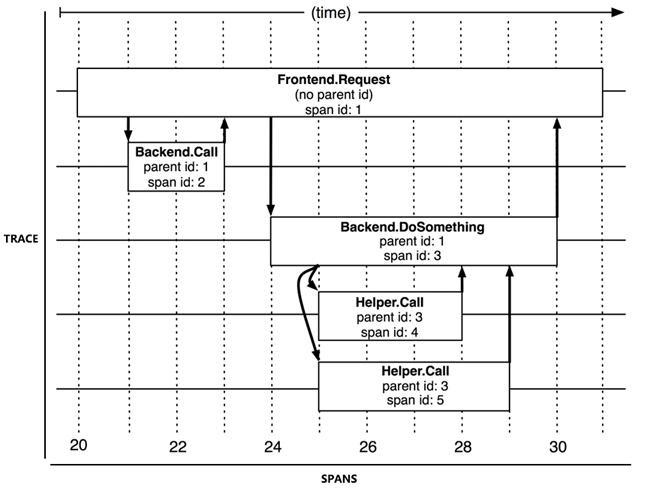
对于链路追踪,有追踪和跨度两个概念。Trace 就是一次调用的完整过程(纵向的),而 Span 是在一个服务内部的处理过程(横向的,包括处理时间、处理结果)。想要进行链路追踪,对于每一次服务调用都需要记录 Trace 和 Span,通过 Trace 和 Span 生成服务调用拓扑图。根据拓扑图中 Span 记录的时间信息和响应结果(正常或异常返回)就可以定位到缓慢或者出错的服务;将 Trace 与历史记录进行对比统计,就可以从系统整体层面分析服务性能,定位性能优化的目标。
OpenTelemetry + Jaeger
OpenTelemetry 只涉及到遥感数据(链路追踪信息、日志、指标)的采集和传输,为遥感数据的采集和传输提供一套统一的标准。
Jaeger 是分布式链路追踪工具,用于管理和监控链路追踪数据。
链路追踪可以涉及两个步骤:
- 采集链路请求数据。
- 存储、管理和可视化收集的数据以采取快速行动。
OpenTelemetry 解决了第一步,而 Jaeger 旨在解决后者。使用 OpenTelemetry,可以生成链路信息、日志、指标,而 Jaeger 只负责链路追踪分析。
度量
度量虽然没有一个统一的协议标准,但是 Prometheus 已经成为了实践标准。下面以 Prometheus 为例进行说明。
特点
Prometheus 作为一种云原生监控系统,有以下特点:
易于管理
- Prometheus 核心部分只有一个单独的二进制文件,不存在任何的第三方依赖(数据库、缓存等),因此不会存在级联故障。
- Prometheus 基于 Pull 模型的架构方式,可以在任何地方搭建监控系统。
- 对于一些复杂的情况,还可以使用 Prometheus 服务发现功能动态管理监控目标。
监控服务的内部运行状态
- Pometheus 鼓励用户监控服务的内部状态,基于 Prometheus 丰富的 Client 库,用户可以轻松的在应用程序中添加对 Prometheus 的支持,从而让用户可以获取服务和应用内部真正的运行状态。
强大的数据模型
- 所有采集的监控数据均以指标(metric)的形式保存在内置的时间序列数据库当中。所有的样本除了基本的指标名称以外,还包含一组用于描述该样本特征的标签。每一条时间序列由指标名称(Metrics Name)以及一组标签(Labels)唯一标识。如下所示:
1 | { |
强大的查询语言 PromQL
- Prometheus 内置了一个强大的数据查询语言 PromQL。 通过 PromQL 可以实现对监控数据的查询、聚合。同时 PromQL 也被应用于数据可视化(如 Grafana)以及告警当中。
可扩展
- Prometheus 对于联邦集群的支持,可以让多个 Prometheus 实例产生一个逻辑集群,当单实例 Prometheus Server 处理的任务量过大时,通过使用功能分区 + 联邦集群可以对其进行扩展。
架构
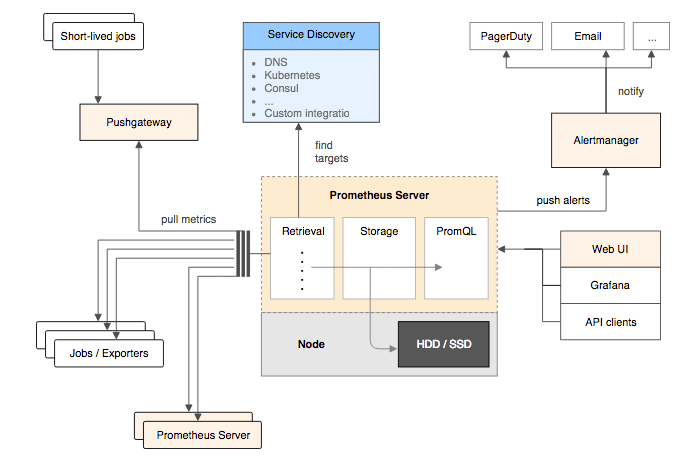
Prometheus 整体上可以分为三个模块:
- 采集层
- 存储计算层
- 应用层
采集层
采集层主要用于采集被监控的数据,层分为两类,一类是生命周期较短的作业,还有一类是生命周期较长的作业(这种对应于监控特定的机器)。
- 短作业:直接通过 API,在退出时将指标推送给 Pushgateway(推送网关,短作业将指标推送给推送网关,之后 Prometheus server 中的 Retrieval 统一从推送网关中拉取短作业的监控数据)。Prometheus 基于 Pull 架构的同时还能够有限度地兼容 Push 式采集,是因为它有 Push Gateway 的存在。
- 长作业:Retrieval 组件直接从 Job 或者 Exporter(Exporter 为专门为一些应用开发的数据获取组件,如 mysqld_exporter、node_exporter 等)拉取数据。Exporter 以 HTTP 协议返回符合 Prometheus 格式要求的文本数据给 Prometheus 服务器。
存储计算层
存储计算层包含两个主要组件,Prometheus server 和 Service discovery。
- Prometheus server:
- Retrieval:取数据组件,它会主动从 Pushgateway 或者 Exporter 中拉取指标数据。
- TSDB:时序数据库,提供数据核心存储与查询。
- HTTP server:对外提供 HTTP 服务。
- Service discovery:可以动态发现要监控的目标。
应用层
应用层主要分为两种,AlertManager 和数据可视化。
- AlertManager:专门用于处理告警的组件。
- 数据可视化:用于数据可视化或者向外提供 API 用于提供监控数据,数据可视化可以采用 Prometheus Web UI、Grafana。