高并发读
缓存
在高并发读的场景下,首先想到的就是加缓存。
- 本地缓存或者 Redis/Memcached 集中式缓存。在缓存时,注意缓存的一致性、以及缓存雪崩缓存击穿等问题。
- MySQL 的 Master/Slave。如果查询是多张表的联合查询结果,而不是 kv 对(当然也可以用 kv 来缓存,但缺点就是任何一张数据库表变化了,缓存都需要更新),可以采用 MySQL 的 Master/Slave 集群,通过 Slave 来分担读压力。
- CDN。对于静态文件,如图片、HTML、CSS、JS 等文件,可以采用 CDN 内容分发网络,CDN 的本质就是在传输链路上做就近缓存。
并发读
将串行操作改为并行操作是常用的优化策略。
- 异步 RPC。当查询的内容没有依赖关系时,可以采用异步 RPC 来减少查询时间。
- 冗余请求。如果在集群中,每一个节点都可能以很小的概率出现调用延迟,可以对同一种请求发出多个冗余请求,取出最快的响应作为查询结果。
重写轻读
在查询数据时需要聚合数据的场景下,可以采用重写轻读的方式进行优化。重写轻读的思路,就是将聚合数据的操作,提前到写入数据时完成,查询的是已经聚合过的数据。
推送 拉取
比如某个用户需要获取他关注的人发的微博,可以分为两种获取方式:
- 推送:在用户发微博时,写入自己的数据库就成功返回。然后利用后台程序,把这条微博主动推送给所有粉丝的收件箱(可以采用 Redis 实现,收件箱可以是一个 list,记录被推送的微博)中。
- 拉取:如果用户粉丝数量很大,那么推送给全部的粉丝这一操作本身就是十分耗时的。所以在查询时还可以主动的从数据库中拉取数据。
在实际应用中,可以采用推拉结合的方式。
对于粉丝数量少的用户,可以采用推送的方式。对于粉丝数量多的用户,只推送给在线粉丝,离线粉丝采用主动拉取的方式。
对于读取的一方,有的是推送给他的、有的是主动拉取的,返回查询结果时,需要把二者再聚合起来。
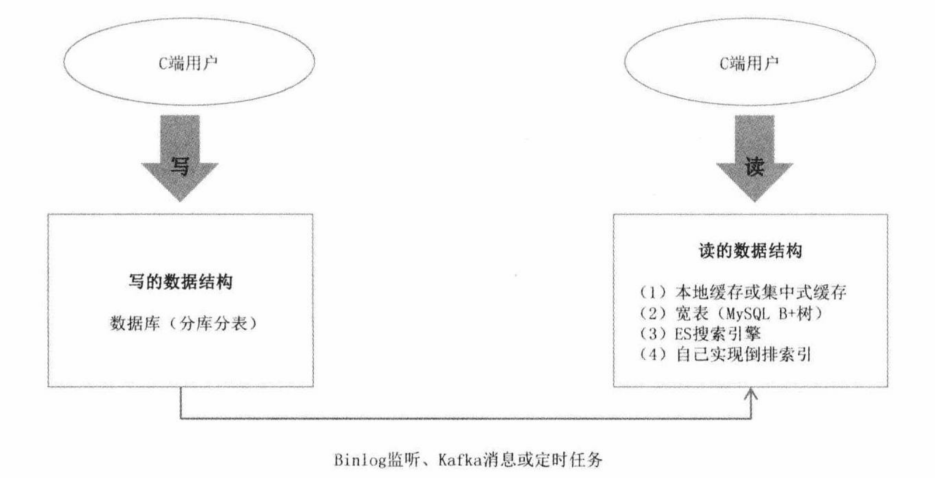
总结 - CQRS
上述的方法本质上都是读写分离,也就是 CQRS(Command Query Responsibility Separation)。CQRS 的特点如下:
- 读写两侧可以采用不同的数据结构:在写入的一侧通常采用 MySQL 这类关系型数据库,可以采用分库分表缓解读压力。而在读的这一侧则根据业务需求选择合适的数据库。
- 读和写的串联:可以在读写之间加入消息队列,来保证读写的最终一致性。
高并发写
数据分片
在高并发写的场景下,需要进行数据分片,对分片的数据可以做到并发写入操作。
最常见的数据分片操作就是数据库的分库分表。分表后,可以更加充分的利用 CPU、内存等资源。分库后,可以利用多台机器的资源。
任务分片
除了在数据上进行分片,也可以对处理应用程序本身进行分片。
典型的任务分片为 Map/Reduce、服务器的 1+N+M 网络模型。
异步化
在应用程序和数据库之间,通过消息队列进行连接,通过异步操作写入数据库。
异步化的操作有两个好处:削峰和更快的用户响应速度。
短信验证码就是一个典型的异步应用。
批量写入
将写请求合并后,批量写入,这也是高并发写的优化思路。