索引
OLTP 数据库存储引擎的核心在于索引,所以介绍几种索引机制。
哈希索引
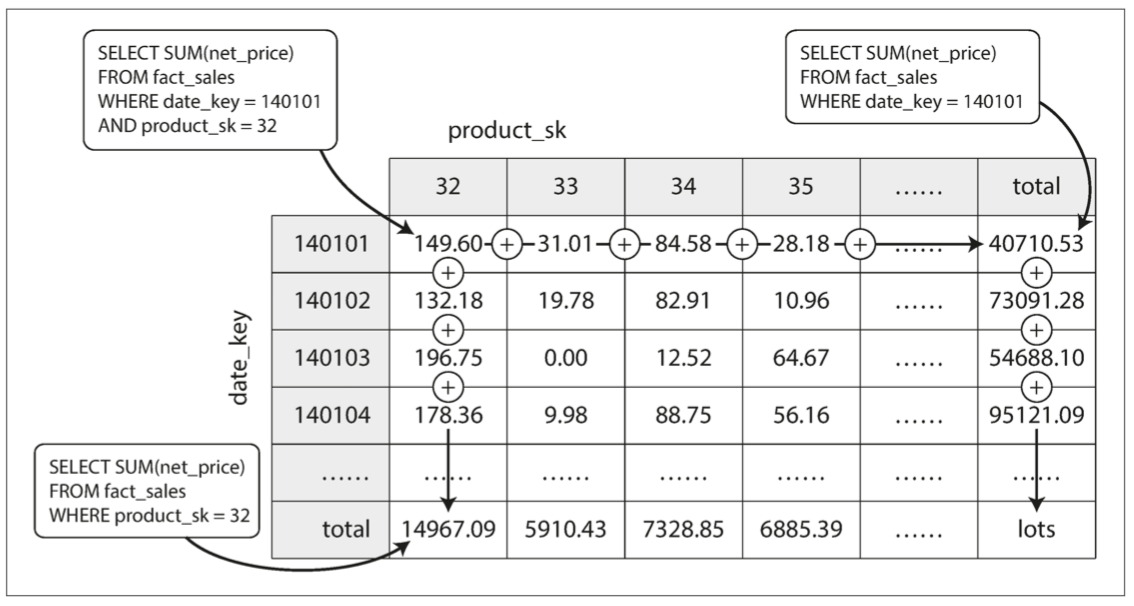
假设我们的数据存储只是一个追加写入的文件(日志),最简单的索引策略就是:在内存中维护一个 hash map,记录键和文件偏移量的映射。
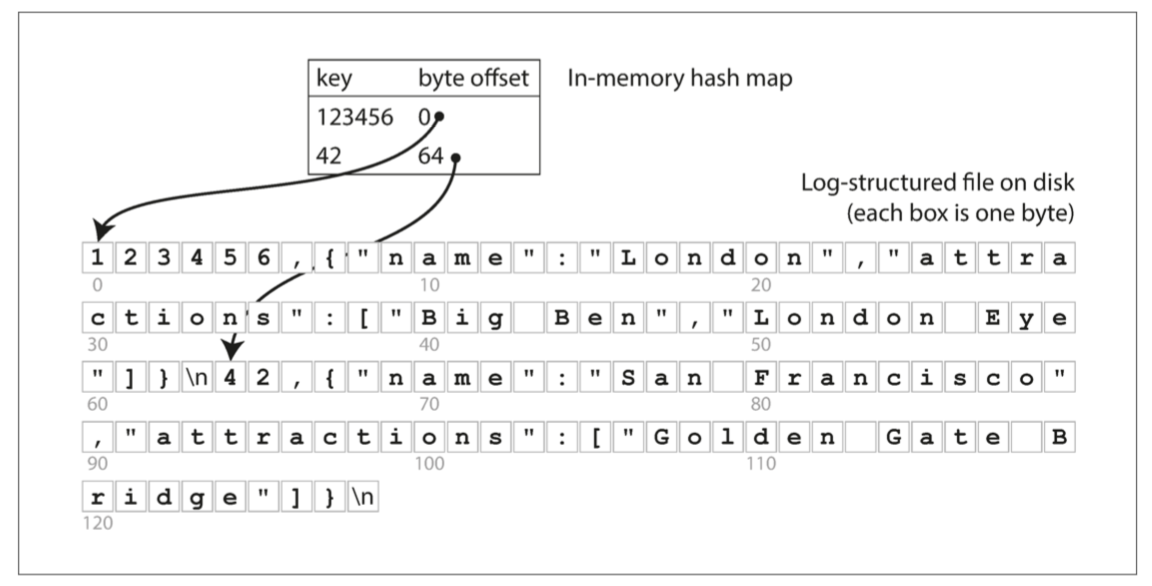
文件分段与压缩
为了防止日志文件无限制的增长,可以采取文件分段和压缩的策略。
- 将日志分为特定大小的段,当日志增长到特定大小时就关闭,开始写入一个新的段文件。
- 将段进行压缩,只保留每一个键最新的值。同样的,也可以把多个段的内容压缩合并到一起。
每一个段都有自己的 hash map,将键映射到文件偏移量中。在查询时,从后向前检索每一个段的 hash map 即可。
参考 Redis AOF 压缩的思路,在进行压缩时:
- 首先记录位置,开启一个后台线程开始压缩位置之前的数据。
- 正常写入 AOF 文件,后台线程将压缩之后的数据写入一个新的 AOF 文件中。
- 暂停写入,将开始压缩后写入的数据追加到新文件中,用新的 AOF 文件替换旧的 AOF 文件。
崩溃恢复与并发控制
崩溃恢复
数据库可能在追加写入文件时崩溃,所以需要包含校验和用于检测和忽略日志的损坏部分。
在数据库重新启动时,内存中的 hash map 将丢失。原则上需要重新顺序读取段文件来重新构建 hash map,但是如果段文件非常大这是十分耗时的。所以可以通过在磁盘上保存 hash map 的快照,用于快速加载到内存中。
并发控制
由于写操作是以严格顺序的顺序附加到日志中的,所以常见的实现选择是只有一个写线程,但是可以有多个线程同时读取。
局限性
哈希索引也有两个局限性:
- 哈希表必须全部放入内存。原则上可以在磁盘上维护哈希表,但是这样会有大量的随机 I/O,性能表现很难优秀。
- 范围查询效率不高。范围查询必须顺序查找每一个键。
LSM 树
SSTable
之前文件中的键值顺序为写入顺序,现在做出一个改变:键值对的顺序按照键进行排序,把这个格式称为排序字符串表(Sorted String Table,SSTable)。还要求每个键只在每个合并的段文件中出现一次(压缩过程已经保证)。
优势
SSTable 相比于哈希索引顺序写入的日志文件相比,有以下几个优势:
- 合并段是简单且高效的,即使文件大于可用内存。类似于归并算法,每一次合并只取几个段中的最小键值(遇到相同的键时只需要最新的,其他旧段中的丢弃)。
- 不需要保存所有键的索引,因为键在文件中的存储是有序的,所以部分索引就可以知道键值对所在的区间。
- 对索引区间内的数据,在保存到磁盘之前可以进行压缩,这样节省了磁盘空间。
从 SSTable 到 LSM 树
LSM(Log Structure Merge,日志结构合并)树的本质就是 SSTable + 一个追加写入的日志。
LSM 树:在 LevelDB 和 RocksDB 使用。
构建 SSTable
在内存中对键进行排序(如红黑树、AVL 树),存储引擎的工作流程如下:
- 写入时,将其添加到内存中的平衡树数据结构(如红黑树)中,这个数据结构被称为内存表(memtable)。
- 当内存表大于某个阈值时,将其作为 SSTable 文件写入磁盘。因为内存表已经完成了键的排序,所以写入磁盘时就是顺序写入的。当写入完成后,创建一个新的内存表实例,用于记录新写入的数据。
- 读取时,首先尝试在内存表中查询关键字,如果没有找到则在最近的磁盘文件中查找关键字,依次类推。
- 定期开启一个后台线程,合并压缩磁盘段文件。
追加写入的日志
当数据库崩溃时,如何解决最近的写入(在内存表中,但尚未写入磁盘)将丢失的问题?
- 在磁盘上保存一个单独的日志,每个写入都会立即被追加到这个磁盘日志文件上。
- 该日志不是按排序顺序,但这并不重要,因为它的唯一目的是在崩溃后恢复内存表。
- 当内存表写入到磁盘 SSTable 时,相应的日志就可以被丢弃了。
性能优化
- 当查找数据库中不存在的键时:LSM树算法可能会很慢,必须检测 memtable,然后从后往前读取磁盘中的每一个 SSTable 段之后,才能确定键不存在。为了优化这种访问,存储引擎通常使用额外的布隆过滤器。
- 压缩合并策略:常见的策略是大小分级压缩和分层压缩。
- 大小分级压缩中,较新的和较小的SSTable文件被连续合并到较旧的、较大的文件SSTable中。
- 分层压缩中,按照键的范围分裂成多个更小的 SSTable,新数据在最顶层,旧数据在下层,上层的 SSTable 可以和下层的 SSTable 进行合并压缩。
B 树 B+ 树
MySQL 的存储引擎 InnoDB 就是基于 B+ 树的,B 树和 B+ 树的原理这里不再过多赘述。
哈希索引和 LSM 树都是基于日志结构的索引,段的写入都是顺序写入的。而 B+ 树将数据库分解成固定大小的页(与磁盘页保持一致),是内部读写的最小的单元,页内部可以随机读写。
根据经验来说,LSM 树写入更快,而 B+ 树读取速度更快。
事务处理 数据分析
数据库的使用可以分为在线事务处理(OLTP,OnLine Transaction Processing)和在线分析处理(OLAP,OnLine Analytics Processing)。
OLTP 和 OLAP 的特点如下:
| 属性 | 事务处理 OLTP | 分析系统 OLAP |
|---|---|---|
| 主要读取模式 | 查询少量记录,按键读取 | 在大批量记录上聚合 |
| 主要写入模式 | 随机访问,写入要求低延时 | 批量导入(ETL),事件流 |
| 主要用户 | 终端用户,通过Web应用 | 内部数据分析师,决策支持 |
| 处理的数据 | 数据的最新状态(当前时间点) | 随时间推移的历史事件 |
| 数据集尺寸 | GB ~ TB | TB ~ PB |
OLTP 数据库面向用户,就是我们通常意义上的数据库,如 MySQL、Oracle 等;而 OLAP 数据库面向内部分析人员,被称为数据仓库。
OLTP 数据库也可以做 OLAP,但是对于大量数据而言,数据仓库可以针对其访问模式进行优化。
数据仓库
数据仓库是一个独立的数据库,分析人员可以查询他们想要的内容而不影响 OLTP 操作。数据仓库包含公司各种OLTP系统中所有的只读数据副本。
从OLTP数据库中提取数据(使用定期的数据转储或连续的更新流),转换成适合分析的模式,清理并加载到数据仓库中。将数据存入仓库的过程称为 ETL(Extract Transform Load,提取-转换-加载)。
分析数据模型
对于 OLTP 而言,有关系、文档等数据模型。对于 OLAP 而言,数据模型则少得多。许多数据仓库使用了星型模型或者雪花模型。
在星型模型中:
- 从 OLTP 系统中提取出的数据表被称为维度表。
- 而星型数据模型的中心为事实表,事实表中的每一行代表在特定时间发生的事件;每一列都是维度表的外键引用。事实表的列数非常多,通常上百。
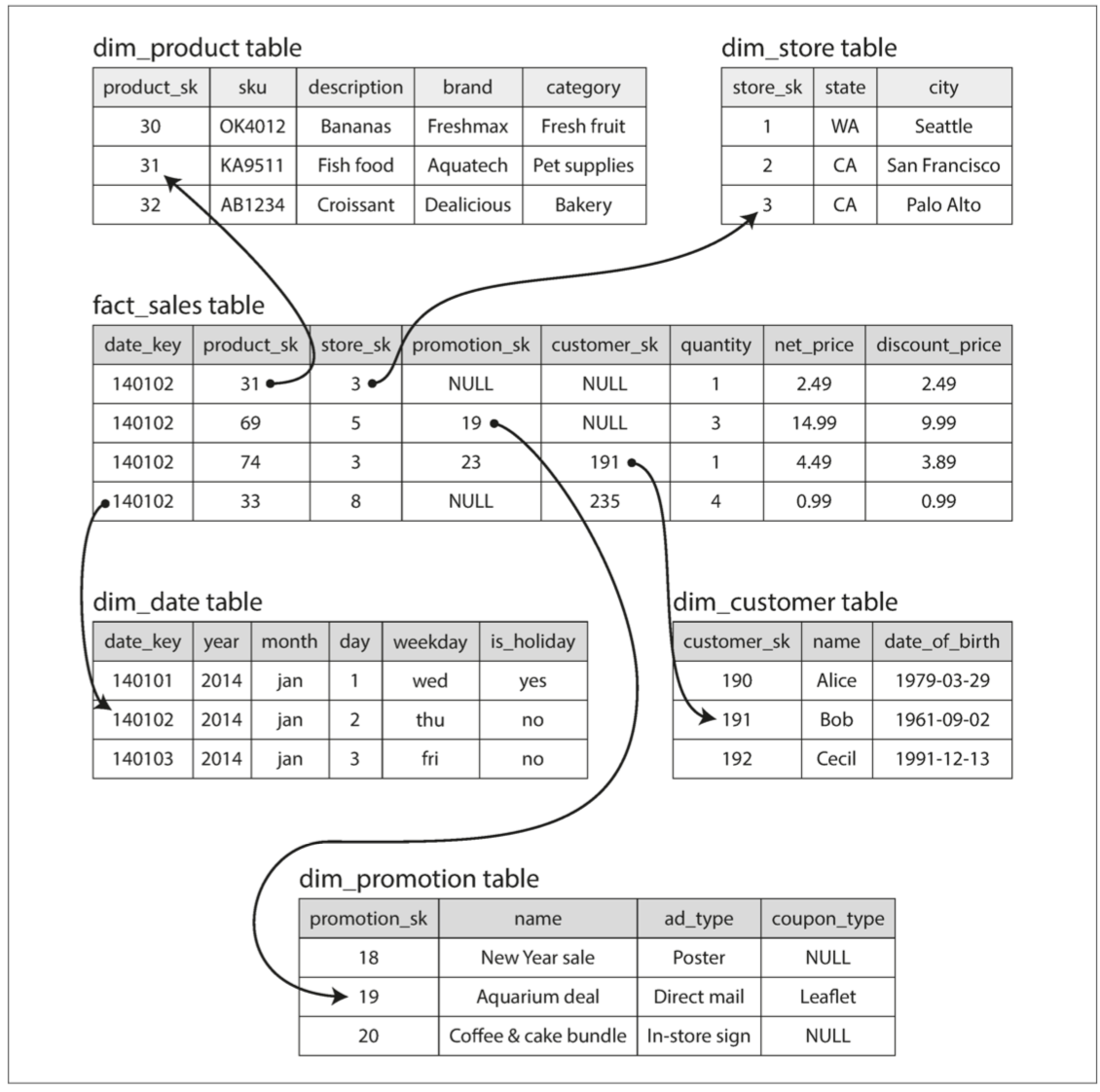
雪花模型是星型模型的变体,就是将维度表进一步分解,维度表中包含其他维度表的外键引用。但是星形模式通常是首选,因为分析师使用它更简单。
列存储
尽管事实表通常超过百列,但典型的数据仓库查询一次访问大量的行,但是只访问少数几个列。
所以可以考虑将 OLAP 数据库设计为列存储,将来自每一列的所有值存储在一起。列存储的优缺点如下:
优点:
- 自动索引:因为基于列存储,所以每一列本身就相当于索引。
- 数据压缩:大部分列数据基数其实是重复的、并且列的数据类型一致利于压缩。
缺点:
- 写入慢:当一条新数据到来,需要将每一列存储到对应的位置。这样就需要多次写磁盘操作。
存储顺序
由于数据仓库的查询多为聚合函数(SUM、AVG 等),列式存储中的存储顺序相对不重要。但也免不了需要对某些列利用条件进行筛选,为此可以如 LSM-Tree 一样,对所有行按某一列进行排序后存储。
排序后的那一列,压缩效果会更好。
同时,如果在分布式数据库中,同一份数据会存储多份。对于每一份数据,在不同副本上可以按不同列有序存储。这样,针对不同的查询需求,便可以路由到不同的副本上做处理。
读优化:物化视图 读优化
数据仓库查询通常涉及聚合函数,并且是多读少写的场景。所以引入物化视图(物化视图与数据库中的逻辑视图不同,物化视图相当于是持久化了的视图),物化视图本质上是对数据的一个摘要存储,如果原数据发生了变动,物化视图要被重新生成。
物化视图的一个特例就是数据立方(OLAP Cube),按照不同维度对数据进行聚合并缓存下来。