当数据 schema 发生变化时,意味着数据库和应用程序都会发生变化:
- 数据库:关系型数据库可以通过 ALTER 语句修改数据表结构。读时模式数据库不会强制模式,因此数据库可以包含在不同时间写入的新老数据格式的混合。
- 应用程序:新旧版本的代码,以及新旧数据格式可能会在系统中同时共处。所以需要保持双向兼容性(后向兼容和前向兼容)。
后向兼容通常不难实现:新代码的作者当然知道由旧代码使用的数据格式,因此可以显示地处理它。
向前兼容性可能会更棘手,因为旧版的程序需要忽略新版数据格式中新增的部分。
编码
采用适当的编码(序列化和反序列化),可以应对新旧数据格式共存的情形。
Json 和 XML
Json 和 XML 是文本格式的编码,具有人类可读性。但是因为其没有用 IDL 定义其格式、传输效率低等问题,而被人诟病。
尽管可以对 Json(MessagePack、BSON 等)和 XML(WBXML、Fast Infoset 等)格式的数据进行二进制编码,但是相比于 Thrift 以及 Protobuf 等编码来说,节省的空间太小。
Thrift 和 ProtoBuf
Thrift
Apache Thrift 需要用 IDL 进行定义:
1 | struct Person { |
Thrift 有两种不同的二进制编码格式,分别称为BinaryProtocol 和 CompactProtocol,另外还有两种不同的基于 JSON 的编码格式。
在编码时与 Json 不同,不会记录字段名字只记录编号。
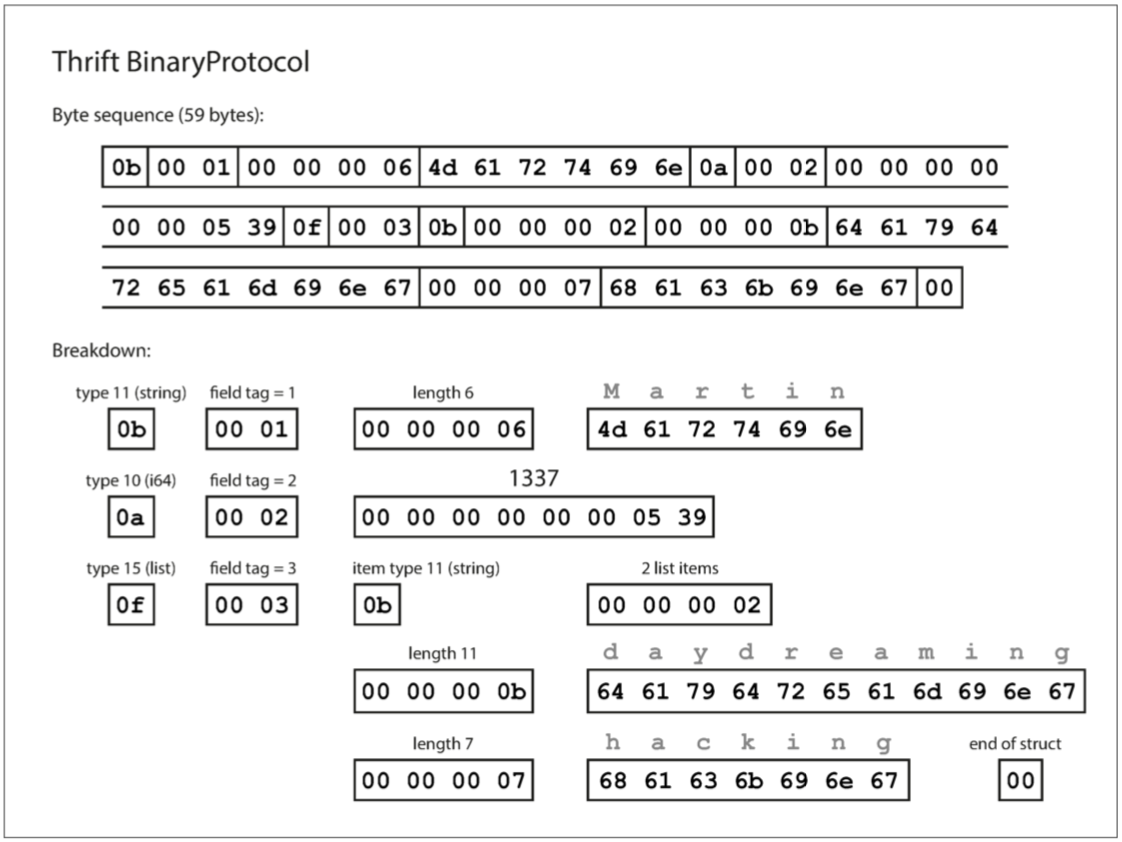
- BinaryProtocol:每个字段都有一个类型注释,还可以根据需要指定长度。
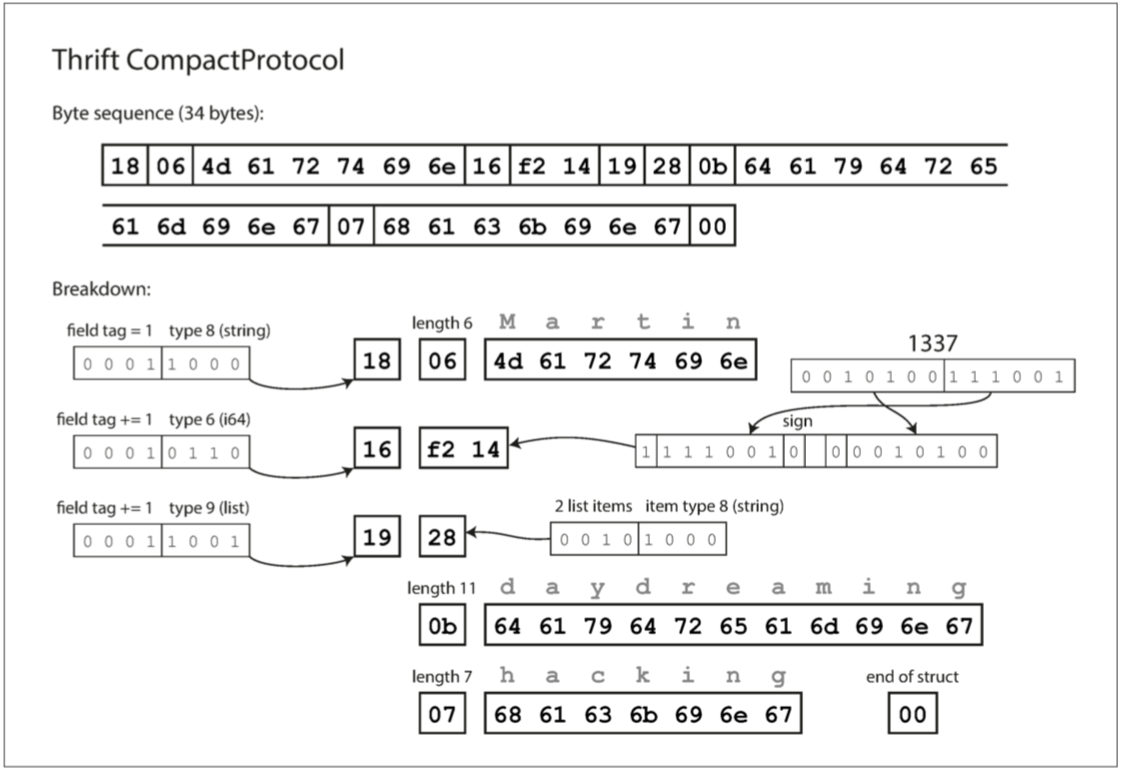
- CompactProtocol:在语义上等同于 BinaryProtocol,它通过将字段类型和标签号打包到单个字节中,并使用可变长度整数来实现(每个字节的最高位用来指示是否还有更多的字节来。)。
ProtoBuf
Protobuf 与 IDL 类似,也需要 IDL 对数据格式进行定义:
1 | message Person { |
Protobuf 只有一种二进制编码格式:打包方式与 Thrift 的 CompactProtocol 非常相似。
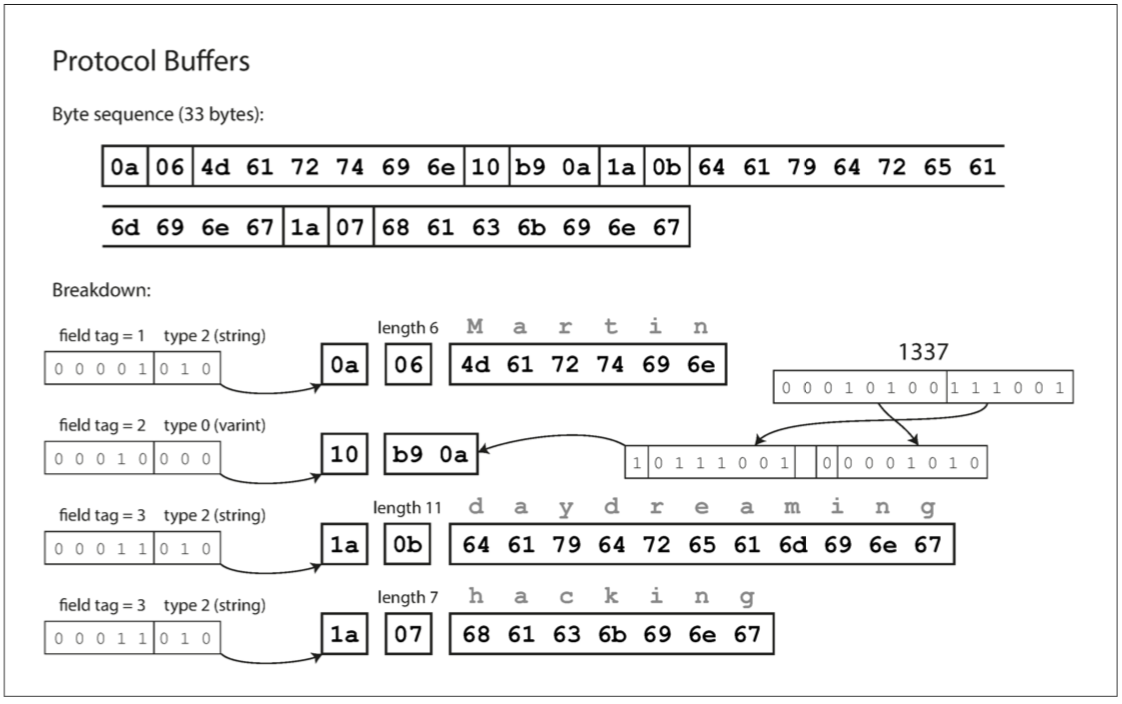
在 Protobuf IDL 定义中,每个字段被标记为必需或可选,但是这对字段如何编码没有任何影响(二进制数据中没有任何字段指示是否需要字段),只在应用程序编解码时有效。
模式演变
数据 schema 不可避免地需要随着时间而改变,我们称之为模式演变。Thrift 和 ProtoBuf 如何保证前向兼容和后向兼容呢?
添加一个字段:只需要给新的字段一个新的数字标签,旧的代码会忽略不能识别的数字标签,这保证了前向兼容。将新增的字段设置为可选,这样就保证了后向兼容。删除一个字段与添加一个字段相反,这里不再过多赘述。
从单值到多值:
- Protobuf 没有类别或者数组类型,对于多值只是在编码时重复数字标记,因此可以将单值字段改为重复字段。
- Thrift 有列表数据类型,因此不允许从单值到多值的相同演变,但是具有支持嵌套列表的优点。
改变精度不能保证双向兼容,会丢失精度。
Avro
Avro 是另一种二进制编码格式,有两种模式语言:
- 一种(Avro IDL)用于人工编辑。
1 | record Person { |
- 一种(基于 JSON)更易于机器读取。
1 | { |
Avro 在编码时没有数字标签,并且没有编入类型(所以 Avro 必须配合模式定义来解析,如 Client-Server 在通信的握手阶段会先交换数据模式。),编码只是由连在一起的值组成,是上述编码中最紧凑的。
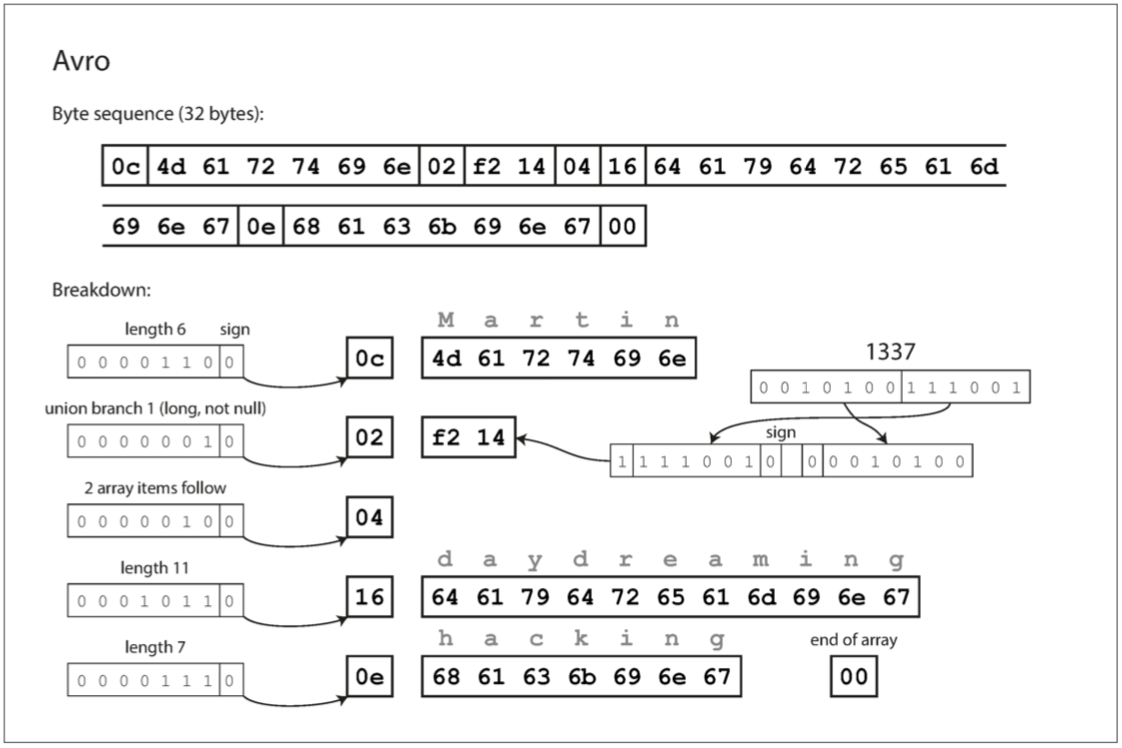
优缺点
- 优点:在握手阶段交换模式定义(支持动态生成消息类型)。
Avro 没有使用数字标号的一个好处是,不需要手动维护字段标号到字段名的映射,这对于动态生成的数据模式很友好。
Avro 的数据模式可以和数据存在一块,可以动态的进行转换,但是 ProtoBuf 的数据模式只能体现在生成的代码中。
- 缺点:语言支持不丰富,(由于没有数字标签)前后向兼容得特性不如 Thrift 和 ProtoBuf。
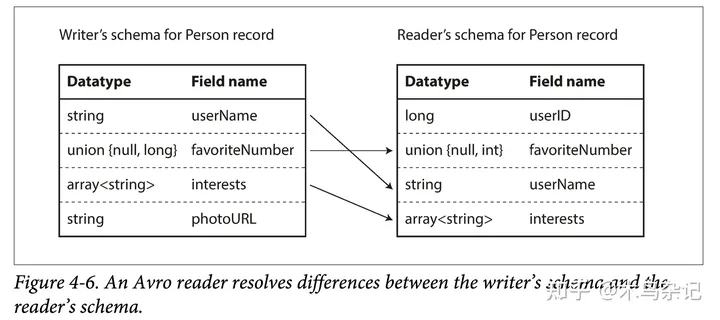
在交换模式后,只要写入和读取得模式是兼容的,那么 Avro 就能够处理向后兼容和向前兼容。
- 使用字段名匹配。
- 忽略多出的字段。
- 对缺少的字段填写默认值。