本节讨论主从复制、多主节点复制和无主节点复制。冗余复制有多个好处:
- 降低延迟。
- 提高可用性。
- 提高读吞吐。
主从复制
主从复制需要注意因为读取不同从数据库、或者从数据库与主数据库的不同步,而造成的暂时不一致性。
主从复制的原理如下:
- 指定某一个副本为主节点。当客户端写数据库时,必须将写请求发给主节点,主节点首先将新数据写入本地存储。
- 其他副本为从节点。主节点将日志发送给所有的从节点,从节点收到日志后应用到本地存储。
- 客户端可以从主节点或者从节点中执行查询操作。
主从复制中,只有主节点是可写的,从节点仅可读。
同步复制 异步复制
复制分为同步复制和异步复制。
- 同步复制: 主节点发送消息,等待从节点响应。同步复制的优点是,从库保证有与主库一致的最新数据副本。缺点是,如果同步从库没有响应,主库就无法处理写入操作。
- 异步复制:主节点发送消息,但不等待从节点的响应。异步复制的速度快、效率高,但是可能会出现数据丢失的情形。
基于同步复制和异步复制的优缺点,所以通常情况下采用半同步复制。半同步复制就是有既有同步从节点(一个),又有异步从节点。当所有的同步从节点响应后完成写入操作。
从节点的日志同步
在新的从节点出现时,需要同步主节点中所有的数据。过程如下:
- 在第一次同步时,主节点会给从节点发送某个时刻的一致性快照。
- 从节点同步快照后,此后的同步,就是增量拉取所有的数据变更。
处理节点宕机
在分布式系统中,任何节点都可能发生宕机。所以必须处理节点的宕机行为,保证集群的高可用。
从库失效:追赶恢复
如果是从节点失效了,则恢复比较容易。从节点可以从日志中知道,在发生故障之前处理的最后一个事务。从库因此可以向主库请求同步之后的所有数据变更,直到追上主节点的数据。
主库失效:故障切换
如果是主节点失效了,则恢复起来非常棘手。其中一个从库需要被提升为新的主库,并且需要重新配置客户端中主库的地址,其他从节点需要拉取新的主节点的数据变更,这个过程就是故障切换。
故障切换可以手动进行(通过数据库管理员),或者是自动进行。自动故障切换的过程如下:
- 确认主库失效。大多数系统只是简单使用 超时:节点频繁地相互来回传递心跳,并且如果一个节点在一段时间内没有响应,就认为它挂了。
- 选择一个新的主库。通过选举过程(这是共识问题)来完成,或者可以由之前选定的控制器节点来指定新的主库。主库的最佳人选通常是拥有旧主库最新数据副本的从库。
故障切换回导致很多问题:
- 如果采用异步复制,则可能出现写入操作丢失的情况。
- 新老主节点数据冲突。新主副本在上位前没有同步完所有日志,旧主副本恢复后,可能会发现和新主副本数据冲突。
- 发生脑裂,集群内部出现多个主节点。
- 超时阈值选取。如果超时阈值选取的过小,在不稳定的网络环境中可能会造成主副本频繁的切换。
复制日志的实现
下面是主库发送给从库的复制日志的几种实践方式。
基于语句的复制
最简单的情形,就是主库记录每一个写入语句,将这些语句发送给从数据库,从数据库解析并执行该SQL语句,就像从客户端收到一样。
虽然听上去很合理,但是又有很多问题:
- 任何调用非确定性函数(nondeterministic)的语句,可能会在每个副本上生成不同的值。例如,
NOW()函数或者RAND()函数。 - 如果语句使用了自增列(auto increment),或者依赖于数据库中的现有数据(例如,
UPDATE ... WHERE <某些条件>),则必须在每个副本上按照完全相同的顺序执行它们,否则可能会产生不同的效果。当有多个并发执行的事务时,这可能成为一个限制。 - 触发器和、存储过程、用户定义的函数,可能会在每个副本上产生不同的结果。
的确有办法绕开这些问题 ——例如,当语句被记录时,主库可以用固定的返回值替换任何不确定的函数调用,以便从库获得相同的值。但是由于边缘情况实在太多了,现在通常会选择其他的复制方法。
基于语句的复制在 5.1 版本前的MySQL中使用。但现在在默认情况下,如果语句中存在任何不确定性,MySQL 会切换到基于行的复制。
传输预写日志 WAL
不管是基于 B+ 树的数据库,还是基于 LSM 树的数据库,都需要记录追加写入的预写日志。所以可以将追加写入的日志复制给从节点,作为同步日志。
主要缺点是日志记录的数据非常底层:包含哪个字节发生了变化,这使得复制与存储引擎紧密关联,通常不可能在主节点和从节点之间使用不同版本的存储引擎。
基于行(逻辑)日志复制
复制和存储引擎使用不同的日志格式,这样可以使复制日志从存储引擎内部分离出来。
关系数据库的逻辑日志通常是以行的粒度描述对数据库表的写入的记录序列(MySQL binlog 就是这种方式)。
对于外部应用程序来说,逻辑日志格式也更容易解析。
基于触发器的复制
触发器有机会将更改记录到一个单独的表中,使用外部程序读取这个表,再加上任何业务逻辑处理,会后将数据变更复制到另一个系统去。
触发器虽然有更高的开销、也更加复杂,但是更具有灵活性。
存储过程同理,数据库直接执行用户代码。
复制滞后问题
同步复制可以保证主节点和从节点的同步,但是性能低,多副本时容易阻塞写入。在异步复制时,某些从节点的进度会落后于主节点,即复制滞后。经过一段时间后,多副本会进入最终一致性。
读你所写
同一个客户端,写入主副本后返回;稍后再去读一个落后的从副本,会发现没有内容。
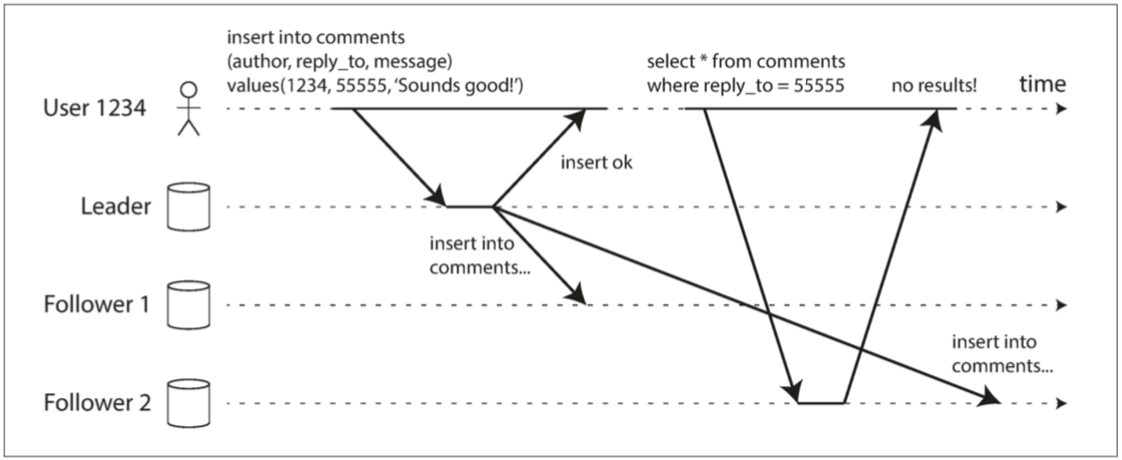
所以引入新的一致性,写后读一致性(read-after-write consistency),对于单个客户端来说,就一定能够读到其所写变动。提供这种一致性的可能方案:
- 按内容分类。对于客户端可能修改的内容集,只从主副本读取。如社交网络上的个人资料,读自己的资料时,从主副本读取;但读其他人资料时,可以向从副本读。
- 按时间分类。 近期(阈值值得关注)内有过改动的数据,从主副本读,其他的向从副本读。
- 利用时间戳。客户端记录写入时间戳,如果读取到的时间戳早于写入时间戳,则换一个副本读取。
单调读
同一个客户端读取两个同步进度不同的副本,可能会读取到更早的数据。
所以,再引入一种一致性保证,单调读。使用以下方法实现:
- 一个客户端只从一个从节点读数据(可以根据哈希)。
- 写后读一致性中的时间戳机制。
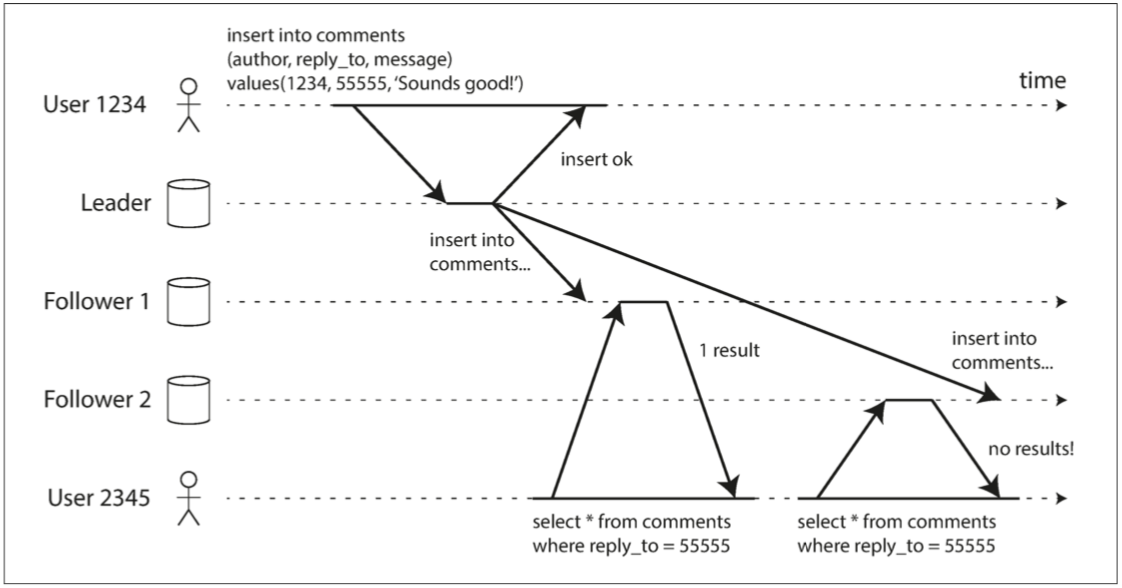
读写一致性和单调读有什么区别?
写后读保证的是写后读顺序,单调读保证的是多次读之间的顺序。
一致前缀读
如果数据库由多个分区(Partition)组成,而分区间的事件顺序无法保证。此时,如果有因果关系的两个事件落在了不同分区,则有可能会出现因果倒置。
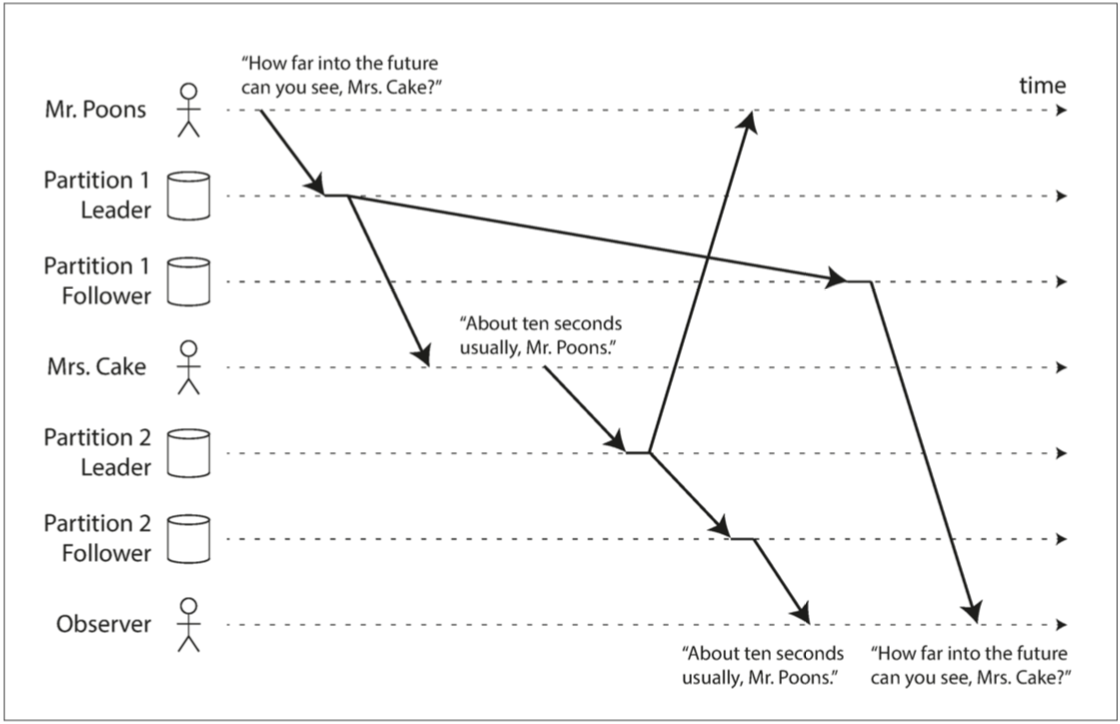
所以引入一致前缀读(consistent prefix reads)。实现这种一致性保证的方法:
- 不分区。
- 让所有有因果关系的事件路由到一个分区,如何确定事件之间的因果关系是个难题。
终极解决方案 - 分布式事务
分布式事务可以解决复制滞后带来的一致性问题。
多主节点复制
配置多个主节点可以防止单点故障,每一个主节点都可以写入,同时扮演其他主节点的从节点。
多主节点之间的复制拓扑结构有三种:环形(MySQL 默认仅支持环形)、星型、洪范结构。
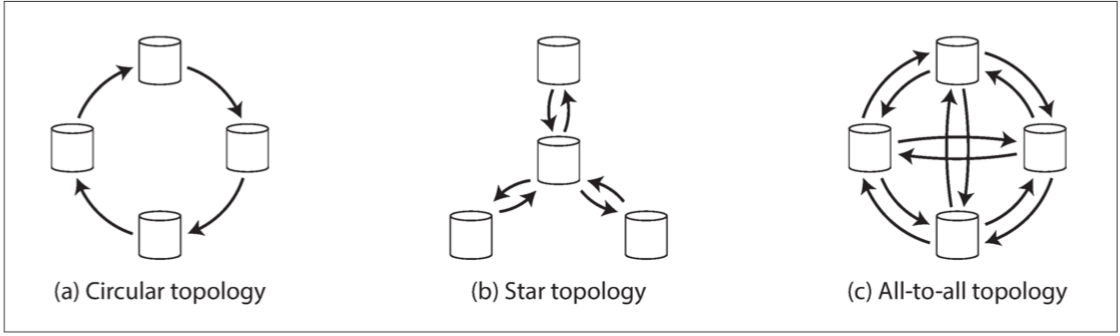
环形和星型依然有单点故障的问题,就可用性而言洪范结构更好。但是洪范结构也有问题:就是消息同步复制错乱(添加时间戳是不够的,因为无法保证时钟完全同步,解决办法是版本向量技术)。
无主节点复制
一些数据存储系统采用不同的方法,放弃主库的概念,并允许任何副本直接接受来自客户端的写入。
从 Amazon 的 Dynamo 论文开始,无主模型又重新大放异彩,Riak,Cassandra 和 Voldemort 都受其启发,可以统称为 Dynamo 流(Dynamo-style)。
Dynamo 流派的存储中通常有两种机制:
- 读时修复(read repair),本质上是一种捎带修复,在读取时发现旧的就顺手修了。
- 反熵过程(Anti-entropy process),本质上是一种兜底修复,读时修复不可能覆盖所有过期数据,因此需要一些后台进程,持续进行扫描,寻找陈旧数据,然后更新。
Quorum 读写
如果副本总数为 n,写入 w 个副本才认定写入成功,并且在查询时最少需要读取 r 个节点。只要满足 w + r > n,我们就能读到最新的数据(鸽巢原理)。此时 r 和 w 的值称为 quorum 读写。即这个约束是保证数据有效所需的最低票数。
在 Dynamo 流派的存储中,n、r 和 w 通常是可以配置的:
- n 越大冗余度就越高,也就越可靠。
- r 和 w 都常都选择超过半数,如
(n+1)/2 - w = n 时,可以让 r = 1。此时是牺牲写入性能换来读取性能。
虽然 Quorum 读写看起来能够保证返回最新值,但在工程实践中有很多不一致的情况,很多细节需要处理。
Soft Quorum
大型集群(总节点数目 > n)中,可能最初选中的 n 台机器,由于种种原因,导致无法达到法定读写数目,则此时有两种选择:
- 对于所有无法达到 r 或 w 个法定数目的读写,直接报错。
- 仍然接受写入,并且将新的写入暂时交给一些正常节点(不在 n 之内的节点)。
后者被称为 Soft Quorum:写和读仍然需要 w 和 r 个成功返回,只不过可能一些节点不在 n 内,只是暂时的保留写入,之后再进行数据迁移。
一旦宕机节点恢复,由反熵后台进程将数据迁移回应该在的节点之中(n 内的节点)。