本节首先会介绍数据集切分的方法,并讨论索引和分片的配合;然后将会讨论分片再平衡(rebalancing),集群节点增删会引起数据再平衡;最后,会探讨数据库如何将请求路由到相应的分片并执行。
分片方法
分片方法都是基于键值对的,键值对是数据的一种最通用、泛化的表示,其他种类数据库都可以转化为键值对表示:
- 关系型数据库:primary key → row
- 文档型数据库:document id → document
- 图数据库:vertex id → vertex,edge id → edge
所以数据分片的基本方法就是,首先将数据转化为键值对,然后进行分区。分片(Partition) 的本质是对数据集合的划分,可以分为两个步骤:
- 对数据集进行逻辑划分。
- 将逻辑分片调度到物理节点上。
本节介绍逻辑划分方法,分别是按照键范围分区和按键散列分区。
按键范围分区
将该连续的定义域进行切分,每个分区内可以按照关键字排序保存(SSLTable)。保存每个切分的上下界,在给出某个 Key 时,就能通过比较,定位其所在分区。
- 按键范围分区好处在于可以进行快速的范围查询。
- 坏处在于,数据分散不均匀,且容易造成热点。
比如关键字是时间戳,可能导致在近期的分区写入负载高,但是其他分区处于空闲状态。
解决方法就是使用除了时间戳以外的其他内容作为关键字的第一项,使用拼接主键的方式。
按键散列分区
为了避免数据倾斜和读写热点,许多数据系统使用散列函数对键进行分区。
一致性哈希也是基于散列分区,它不仅解决了从键到分区的映射,也解决了分区到节点的映射。
哈希分片在避免数据倾斜和读写热点的同时,也丧失了高效的范围查询方式。
在MongoDB中,如果启用了基于哈希的分片方式则范围查询会发送到所有的分区上,而一些数据库如Riak、Couchbase则不支持范围查询。
Cassandra 则在范围分区和哈希分区做出了折中,即可以将主键声明为复合主键。主键的第一列用于哈希分区,而其他列用作索引列基于SSTable进行排序。因此,它不支持第一列的范围查询,但是如果指定第一列为固定值,则可以对其他列进行高效的范围查询。
负载倾斜与热点
哈希分区可以减轻热点,但是无法完全避免。如果所有的读写操作都针对同一个关键字(如某个热点大 V 的用户 ID),那么最终所有的请求路由到同一个分区。
数据库层面无法解决这种数据热点问题,这种情况下只能通过应用层来减轻数据倾斜的程度。如果某个关键字被认为是热点,一个简单的方法就是在关键字的开头或者结尾加上一个随机数。
但这无疑需要应用层做额外的工作,请求时需要进行拆分,返回时需要进行合并;此外,还需要额外的元数据来标记哪些关键字进行了特殊的处理。
分区和二级索引
由于分区都是基于主键的,在针对有分区的数据建立次级索引时,就会遇到一些困难。数据分区的二级索引可以有两种实现方式:
- 本地索引。
- 全局索引。
本地索引
本地索引就是对每个数据分区独立地建立次级索引,即次级索引只针对本分区数据,而不关心其他分区数据。
本地索引的优点是维护方便、实现简单,在更新数据时,只需要在该分区所在机器同时更新索引即可。
但缺点是,查询效率相对较低,所有基于索引的查询请求,都要发送到所有分区,并将结果合并。这种方法造成了读延迟放大,也容易发生长尾请求(由于某些节点响应慢),导致整个请求过程变慢。
本地索引非常简单,本地索引被广泛使用,如 MongoDB,Riak,Cassandra,Elasticsearch,SolrCloud 和 VoltDB 都使用本地索引。
全局索引
为了避免查询索引时将请求发到所有分区,可以建立全局索引,即每个次级索引条目都是针对全局数据。同时,也会将二级索引数据本身进行分片,分散到多个机器上。
对二级索引进行分区,也可以基于范围或者哈希,优劣前文已经说明。
全局索引可以避免在查询时向所有分区发送请求;但维护起来较为复杂,存在写延迟放大的问题,在插入数据时可能会写入多个二级索引。
为了避免增加写入延迟,在实践中,全局索引多为异步更新。但由此会带来短暂(有时可能会比较长)的数据和索引不一致。
如果想要保证强一致性,需要引入跨分区的分布式事务(实现复杂度高,且会带来较大的性能损耗),但并不是所有数据库都支持。
分区再平衡策略
本小节介绍逻辑分区到物理节点的映射方法。
静态分区
静态分区,即,逻辑分区阶段的分区数量是固定的,并且最好让分区数量大于(比如高一个数量级)机器节点(也不能太大,因为每个分区信息也是有管理成本的)。
静态分区需要元信息节点,维护逻辑分区到物理节点的映射,并根据此映射信息来发现不均衡,进而进行调度。
动态分区
在动态分区中,当分区数据增长超过了阈值则拆分为两个分区,当分区数据删除缩小到了某个阈值则与相邻分区进行合并。
动态分区好处在于,小数据量使用少量分区,减少开销;大数据量增加分区,以均摊负载。
但同时,小数据量时,如果只有一个分区,会限制写入并发。因此,工程中有些数据库支持预分区(如 Hbase 和 MongoDB),即允许在空数据库中,配置最少量的初始分区。
与节点成比例分区
- 静态均衡的分区数量一开始就固定的,但是单分区尺寸会随着总数量增大而增大。
- 动态分区的分区数量与数据量有关,单分区尺寸相对保持不变。
保持总分区数量和节点数量成正比,也即保持每个节点分区数量不变。
请求路由
当客户端请求到来时,我们如何决定将请求路由到哪台机器?需要知道两点:
- 数据条目到逻辑分区的映射。
- 逻辑分区到物理机器的映射。
路由方案
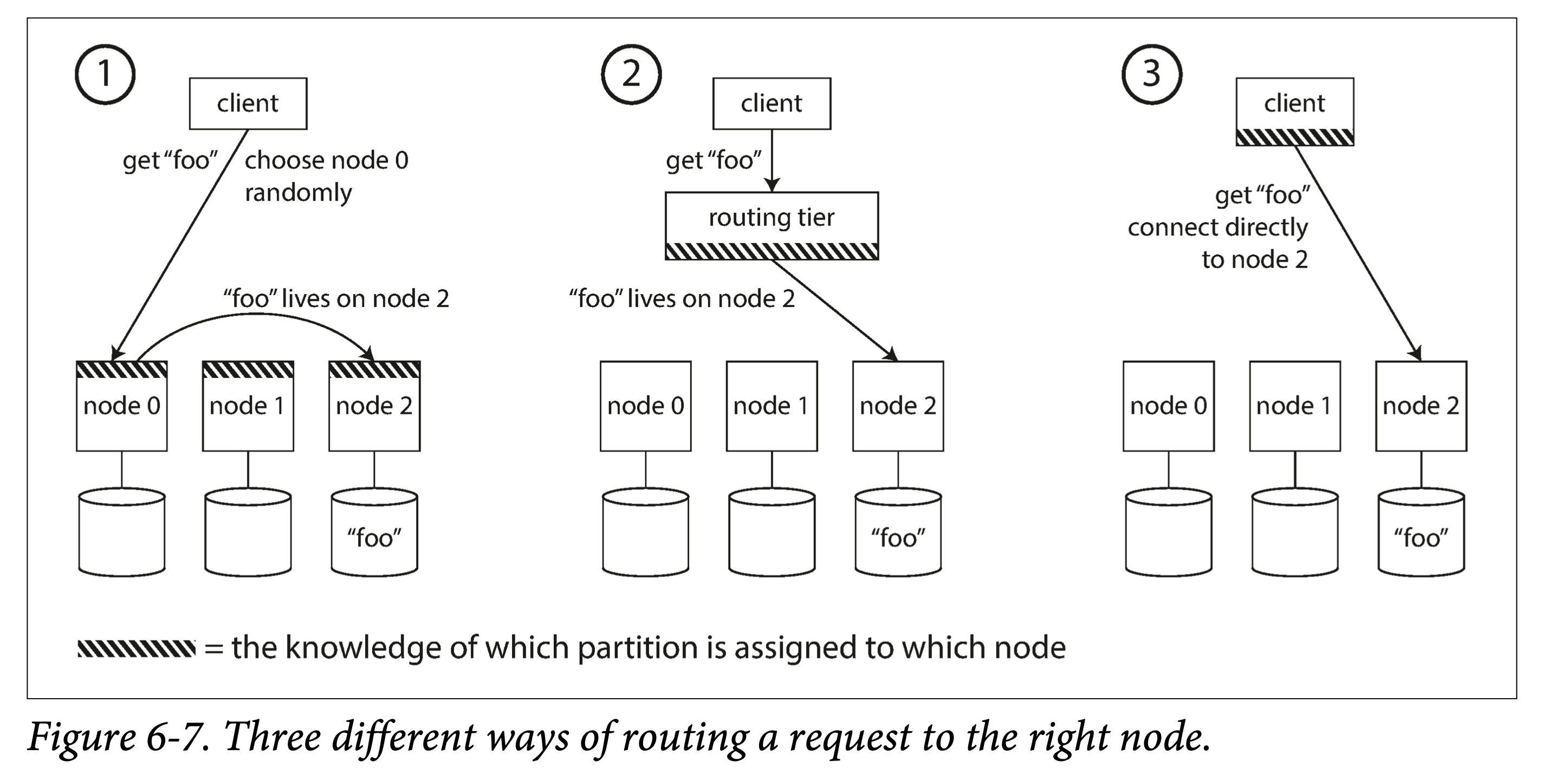
总的来说有三种方案:
- 每个节点都有全局路由表。客户端可以连接集群中任意一个节点,如该节点恰有该分区,则处理后返回;否则,根据路由信息,将其路由合适节点。
- 由一个专门的路由层来记录。客户端所有请求都打到路由层,路由层依据分区路由信息,将请求转发给相关节点。
- 让客户端感知分区到节点映射。客户端可以直接根据该映射,向某个节点发送请求。
感知路由变化
如何让相关组件感知(分区到节点)的映射变化?
- 依赖外部协调组件。如 Zookeeper、Etcd,他们各自使用某种共识协议保持高可用和一致性,并且提供 Watch 接口。在有路由信息更新时,让外部所有节点快速达成一致。
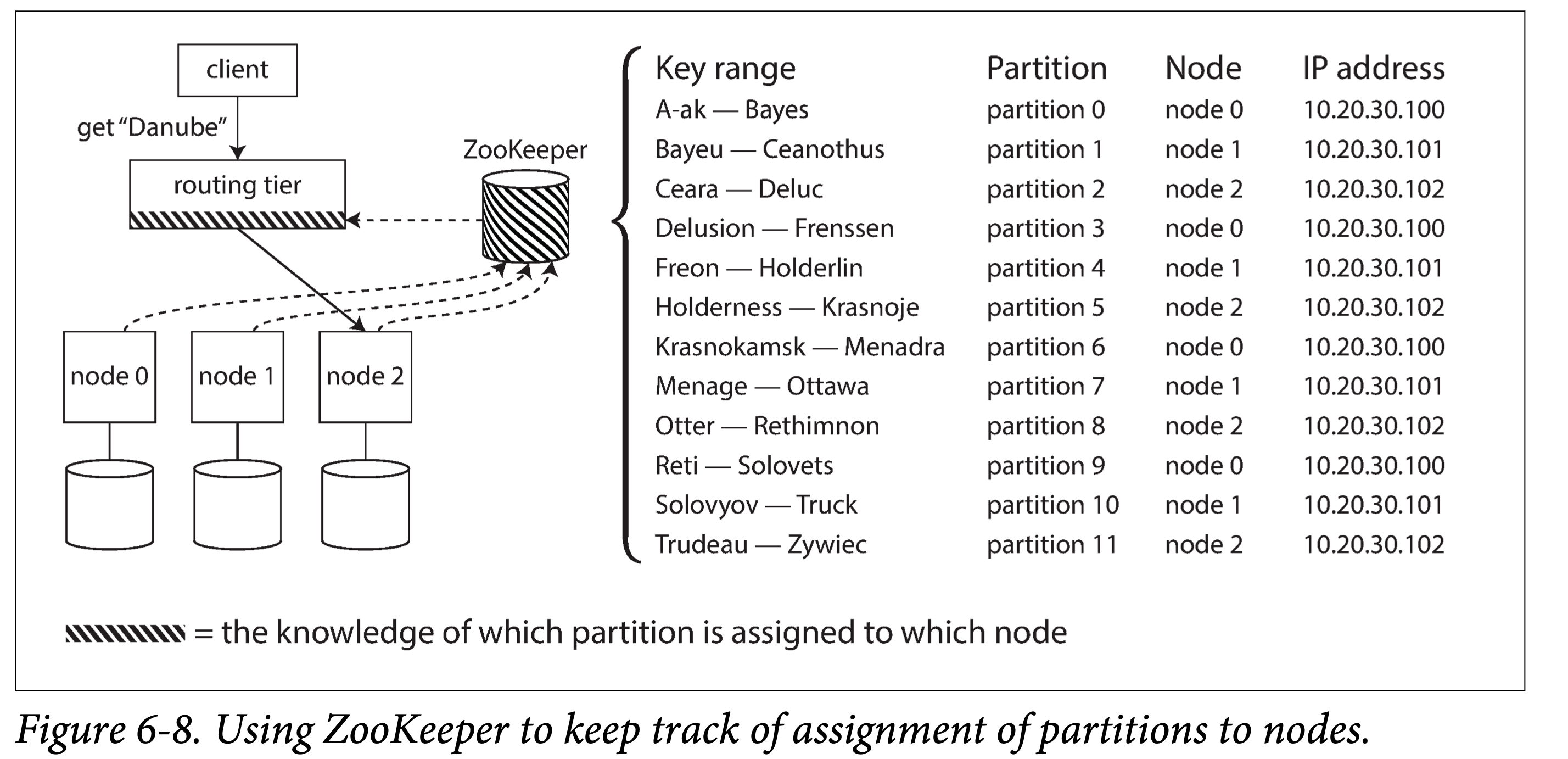
- 使用内部元数据服务器。如三节点的 Meta 服务器,每个节点都存储一份路由数据,使用某种共识协议达成一致。
- 使用某种协议点对点同步。如 Dynamo、Cassandra 和 Riak 使用 Gossip Protocol,节点之间对路由信息进行传播,达成最终一致性。