Map
HashMap
HashMap 和 Hashtable 的区别
HashMap 和 Hashtable 的区别如下:
- 线程安全:HashMap 不是线程安全的,Hashtable 是线程安全的(函数都由 synchronized 修饰,但是锁的粒度很大,并发度为一)。
- 效率:HashMap 效率更高,因为 Hashtable 线程安全,效率更低(Hashtable 已被淘汰,不要使用)。
- 对 Null 的支持:HashMap 支持 Null 的 Key 和 Value,而 Hashtable 不支持。
- 初始容量和扩容大小:
- Hashtable:如果不指定初始容量,默认初始容量为 11,每一次扩容 2n+1。
- HashMap:如果不知道初始容量,默认初始容量为 16,每一次扩容 2n;指定初始容量时,容量扩充为 2 的幂次方大小。
- 底层数据结构:HashMap 在 JDK 1.8 之前,采用数组+链表的方式,之后采用数组+链表/红黑树的方式(当链表长度大于16,会将链表转为红黑树。但是如果数组长度小于 64,会优先扩容数组)
为什么 HashMap 的容量是 2 的幂次方?
因为在通过对哈希取模选则数组下标时,2 的幂次方可以快速计算:
(n-1) & hash = hash % 数组长度
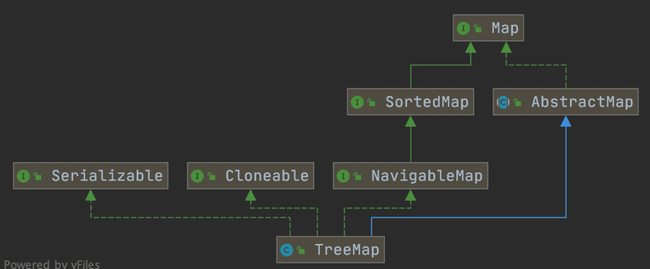
HashMap 和 TreeMap 的区别
HashMap 和 TreeMap 都继承自 AbstractMap,但是 TreeMap 还实现了 NavigableMap 接口和 SortedMap 接口。实现 NavigableMap 接口让 TreeMap 有了对集合内元素的搜索能力;实现 SortedMap 接口让 TreeMap 有了对集合中元素根据 key 的排序能力。
HashMap 多线程死循环问题
JDK1.7 及之前版本的 HashMap 在多线程环境下扩容操作可能存在死循环问题,这是由于当一个桶位中有多个元素需要进行扩容时,多个线程同时对链表进行操作,头插法可能会导致链表中的节点指向错误的位置,从而形成一个环形链表,进而使得查询元素的操作陷入死循环无法结束。
为了解决这个问题,JDK1.8 版本的 HashMap 采用了尾插法而不是头插法来避免链表倒置,使得插入的节点永远都是放在链表的末尾,避免了链表中的环形结构。
ConcurrentHashMap
ConcurrentHashMap 和 Hashtable 的区别
ConcurrentHashMap 和 Hashtable 的区别主要体现在实现线程安全的方式不同:
- 底层数据结构:Hashtable 采用数组+链表的方式。ConcurrentHashMap 在 JDK 1.7 采用分段锁+链表,JDK 1.8 采用数组+链表/红黑树的方式。
- 实现线程安全的方式:
- ConcurrentHashMap:在 JDK 1.7 时,使用分段锁的方式保证线程安全;在 JDK 1.8 时,摒弃了分段锁而是直接使用 Node 数组+链表/红黑树的方式,并发控制使用 synchronized 和 CAS 操作。
- Hashtable:使用 synchronized(同一把锁)保证线程安全,并发程度为 1。
ConcurrentHashMap 并发实现机制
ConcurrentHashMap 在 JDK 1.7 和 1.8 中实现并发的机制不同:
- JDK 1.7:分段锁的方式实现并发,默认 16 个段,也就是说最多支持 16 个线程并发访问。段的个数一旦初始化之后不能改变。
- JDK 1.8:摈弃了分段锁的概念,采用 Node 数组+synchronized+CAS 保证并发安全。锁粒度更细,synchronized 只锁定当前链表或红黑二叉树的首节点,这样只要 hash 不冲突,就不会产生并发,就不会影响其他 Node 的读写,效率大幅提升。
ConcurrentHashMap 为什么 key 和 value 不支持 null
多线程环境下,存在一个线程操作该 ConcurrentHashMap 时,其他的线程将该 ConcurrentHashMap 修改的情况,所以无法通过 containsKey(key) 来判断否存在这个键值对,也就没办法解决二义性问题了。
与此形成对比的是,HashMap 可以存储 null 的 key 和 value,但 null 作为键只能有一个,null 作为值可以有多个。如果传入 null 作为参数,就会返回 hash 值为 0 的位置的值。单线程环境下,不存在一个线程操作该 HashMap 时,其他的线程将该 HashMap 修改的情况,所以可以通过 contains(key)来做判断是否存在这个键值对,从而做相应的处理,也就不存在二义性问题。
也就是说,多线程下无法正确判定键值对是否存在(存在其他线程修改的情况),单线程是可以的(不存在其他线程修改的情况)。